 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Single Camera Depth Estimation using Dual-Pixels
Apr 12, 2019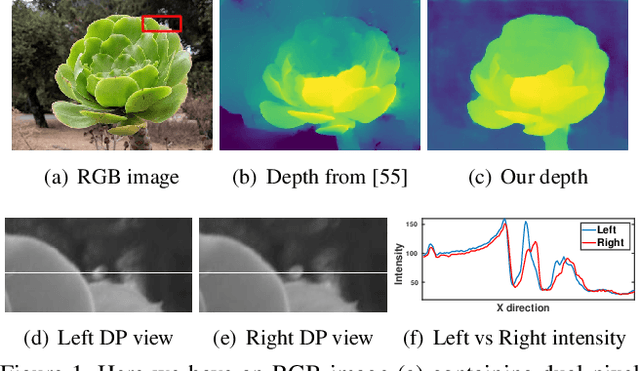
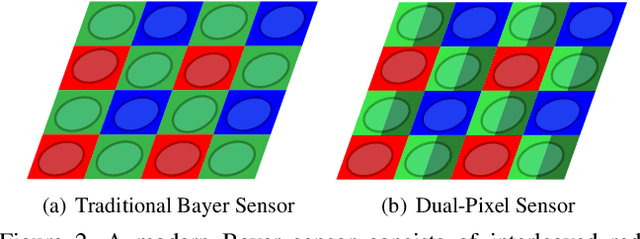
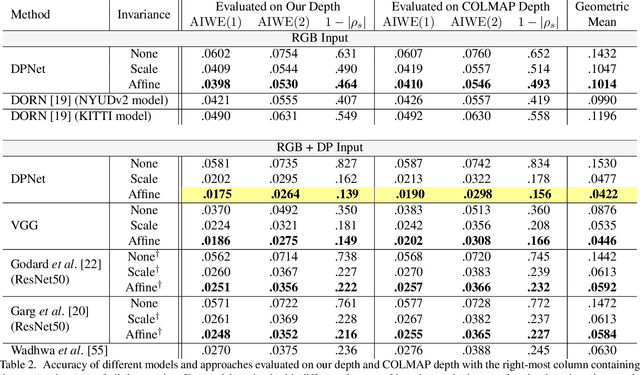
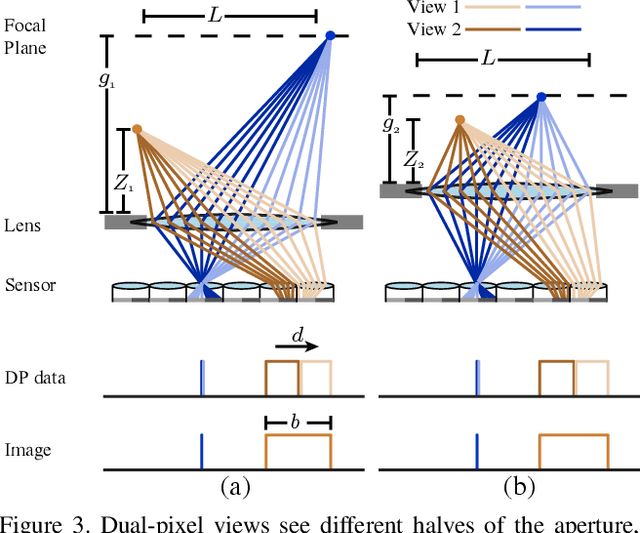
Deep learning techniques have enabled rapid progress in monocular depth estimation, but their quality is limited by the ill-posed nature of the problem and the scarcity of high quality datasets. We estimate depth from a single camera by leveraging the dual-pixel auto-focus hardware that is increasingly common on modern camera sensors. Classic stereo algorithms and prior learning-based depth estimation techniques under-perform when applied on this dual-pixel data, the former due to too-strong assumptions about RGB image matching, and the latter due to a lack of understanding of the optics of dual-pixel image formation. To allow learning based methods to work well on dual-pixel imagery, we identify an inherent ambiguity in the depth estimated from dual-pixel cues, and develop an approach to estimate depth up to this ambiguity. Using our approach, existing monocular depth estimation techniques can be effectively applied to dual-pixel data, and much smaller models can be constructed that still infer high quality depth. To demonstrate this, we capture a large dataset of in-the-wild 5-viewpoint RGB images paired with corresponding dual-pixel data, and show how view supervision with this data can be used to learn depth up to the unknown ambiguities. On our new task, our model is 30% more accurate than any prior work on learning-based monocular or stereoscopic depth estimation.
Wireless Software Synchronization of Multiple Distributed Cameras
Dec 21, 2018


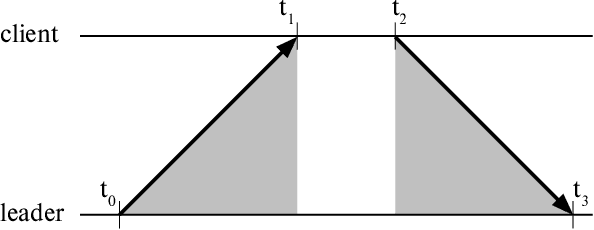
We present a method for precisely time-synchronizing the capture of image sequences from a collection of smartphone cameras connected over WiFi. Our method is entirely software-based, has only modest hardware requirements, and achieves an accuracy of less than 250 microseconds on unmodified commodity hardware. It does not use image content and synchronizes cameras prior to capture. The algorithm operates in two stages. In the first stage, we designate one device as the leader and synchronize each client device's clock to it by estimating network delay. Once clocks are synchronized, the second stage initiates continuous image streaming, estimates the relative phase of image timestamps between each client and the leader, and shifts the streams into alignment. We quantitatively validate our results on a multi-camera rig imaging a high-precision LED array and qualitatively demonstrate significant improvements to multi-view stereo depth estimation and stitching of dynamic scenes. We plan to open-source an Android implementation of our system 'libsoftwaresync', potentially inspiring new types of collective capture applications.