 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Agnostic Sequence Labeling by Copying Nearest Neighbors
Jun 10, 2019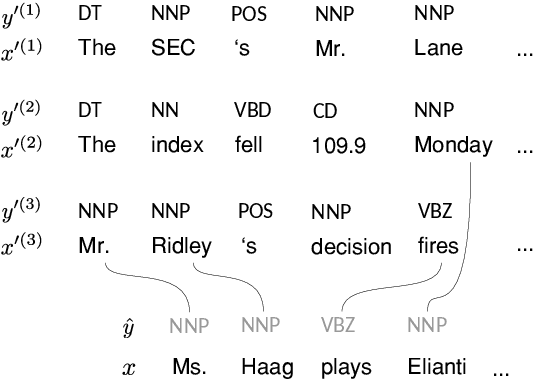
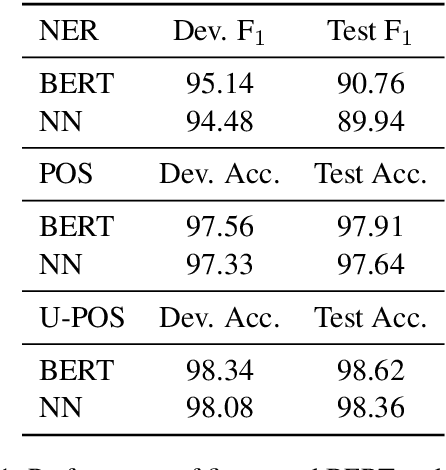
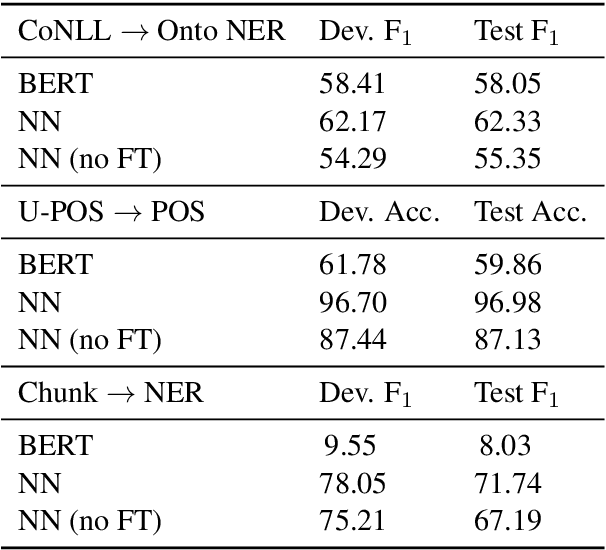

Retrieve-and-edit based approaches to structured prediction, where structures associated with retrieved neighbors are edited to form new structures, have recently attracted increased interest. However, much recent work merely conditions on retrieved structures (e.g., in a sequence-to-sequence framework), rather than explicitly manipulating them. We show we can perform accurate sequence labeling by explicitly (and only) copying labels from retrieved neighbors. Moreover, because this copying is label-agnostic, we can achieve impressive performance in zero-shot sequence-labeling tasks. We additionally consider a dynamic programming approach to sequence labeling in the presence of retrieved neighbors, which allows for controlling the number of distinct (copied) segments used to form a prediction, and leads to both more interpretable and accurate predictions.
Controllable Paraphrase Generation with a Syntactic Exemplar
Jun 03, 2019
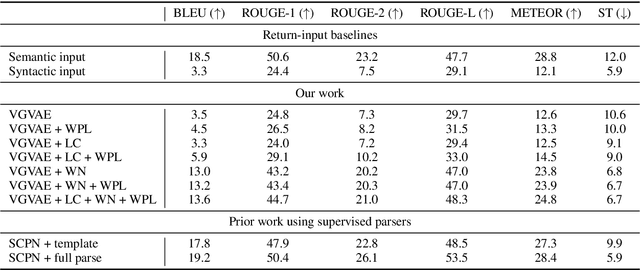
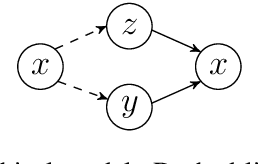
Prior work on controllable text generation usually assumes that the controlled attribute can take on one of a small set of values known a priori. In this work, we propose a novel task, where the syntax of a generated sentence is controlled rather by a sentential exemplar. To evaluate quantitatively with standard metrics, we create a novel dataset with human annotations. We also develop a variational model with a neural module specifically designed for capturing syntactic knowledge and several multitask training objectives to promote disentangled representation learning. Empirically, the proposed model is observed to achieve improvements over baselines and learn to capture desirable characteristics.
A Multi-Task Approach for Disentangling Syntax and Semantics in Sentence Representations
Apr 02, 2019
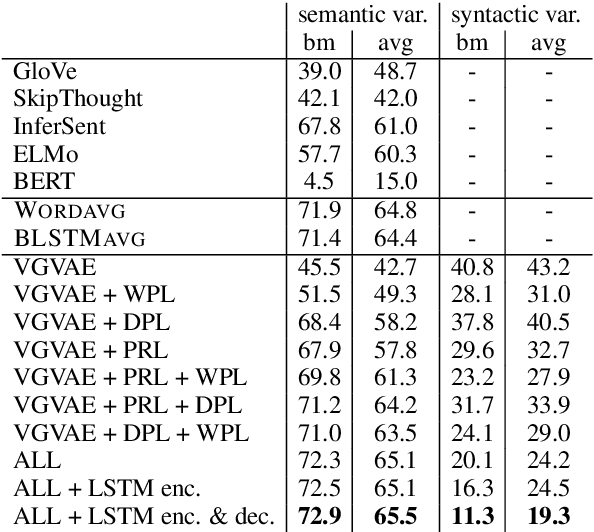
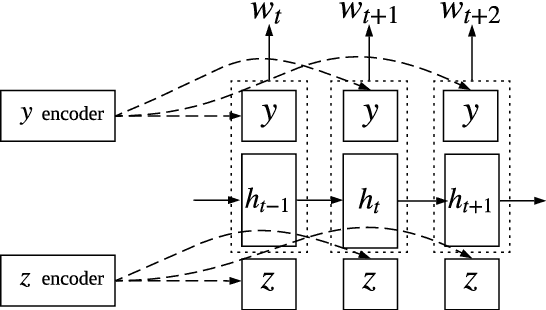
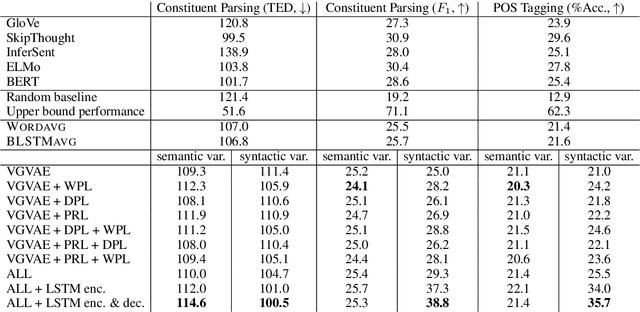
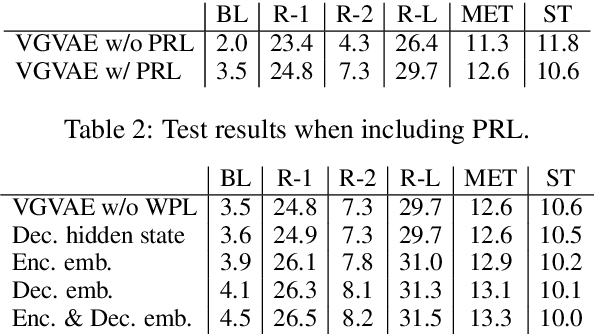
We propose a generative model for a sentence that uses two latent variables, with one intended to represent the syntax of the sentence and the other to represent its semantics. We show we can achieve better disentanglement between semantic and syntactic representations by training with multiple losses, including losses that exploit aligned paraphrastic sentences and word-order information. We also investigate the effect of moving from bag-of-words to recurrent neural network modules. We evaluate our models as well as several popular pretrained embeddings on standard semantic similarity tasks and novel syntactic similarity tasks. Empirically, we find that the model with the best performing syntactic and semantic representations also gives rise to the most disentangled representations.
* NAACL 2019 Long paper
A Tutorial on Deep Latent Variable Models of Natural Language
Dec 18, 2018

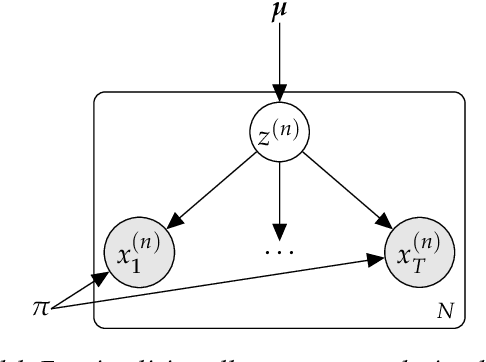
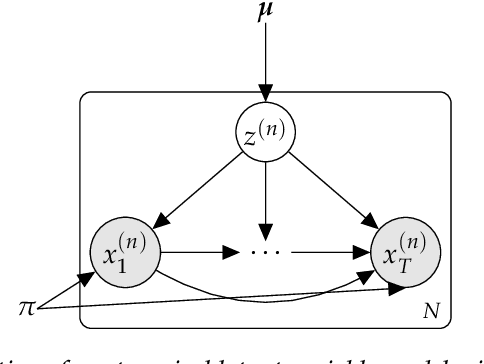
There has been much recent, exciting work on combining the complementary strengths of latent variable models and deep learning. Latent variable modeling makes it easy to explicitly specify model constraints through conditional independence properties, while deep learning makes it possible to parameterize these conditional likelihoods with powerful function approximators. While these "deep latent variable" models provide a rich, flexible framework for modeling many real-world phenomena, difficulties exist: deep parameterizations of conditional likelihoods usually make posterior inference intractable, and latent variable objectives often complicate backpropagation by introducing points of non-differentiability. This tutorial explores these issues in depth through the lens of variational inference.
Learning Neural Templates for Text Generation
Sep 13, 2018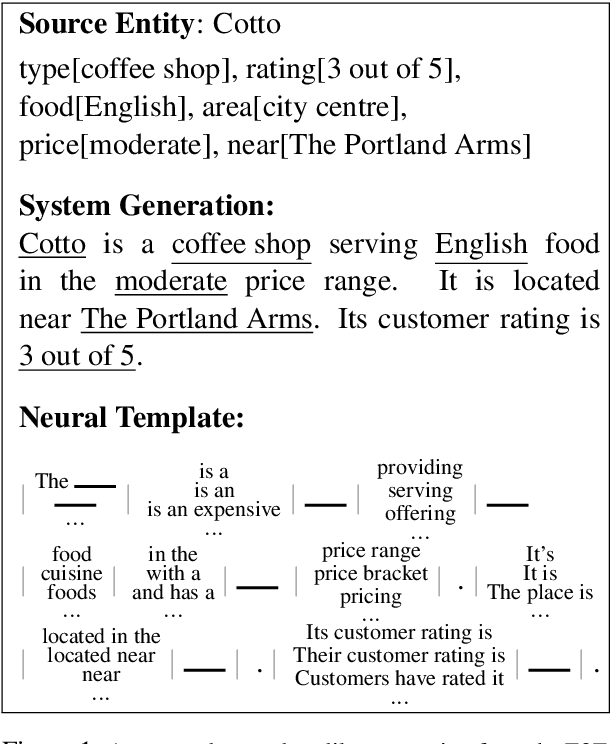
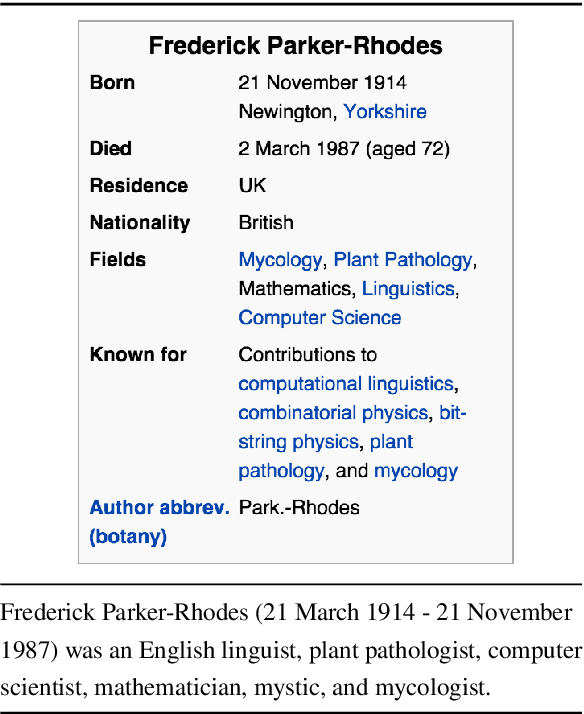
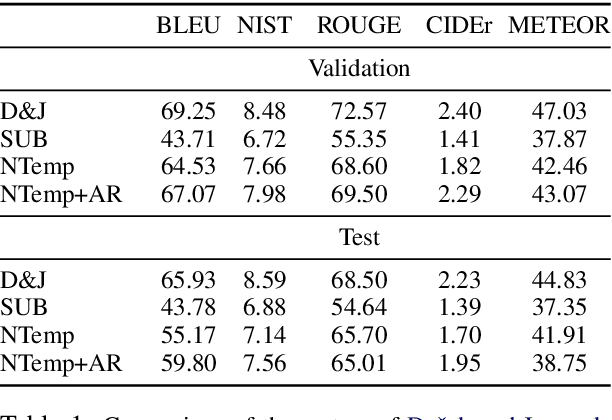
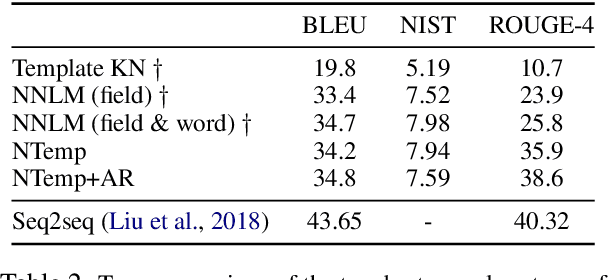
While neural, encoder-decoder models have had significant empirical success in text generation, there remain several unaddressed problems with this style of generation. Encoder-decoder models are largely (a) uninterpretable, and (b) difficult to control in terms of their phrasing or content. This work proposes a neural generation system using a hidden semi-markov model (HSMM) decoder, which learns latent, discrete templates jointly with learning to generate. We show that this model learns useful templates, and that these templates make generation both more interpretable and controllable. Furthermore, we show that this approach scales to real data sets and achieves strong performance nearing that of encoder-decoder text generation models.
Semi-Amortized Variational Autoencoders
Jul 23, 2018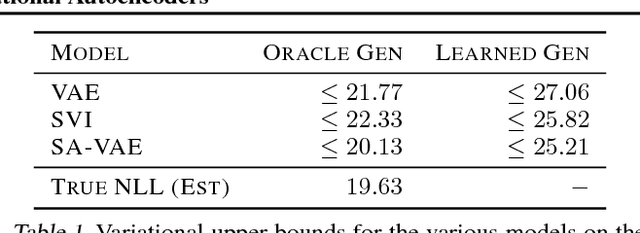
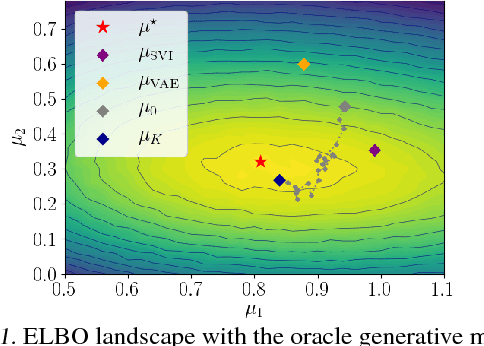
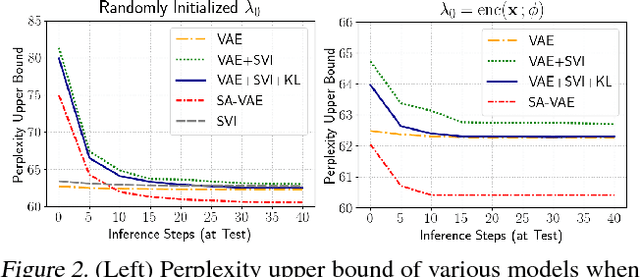
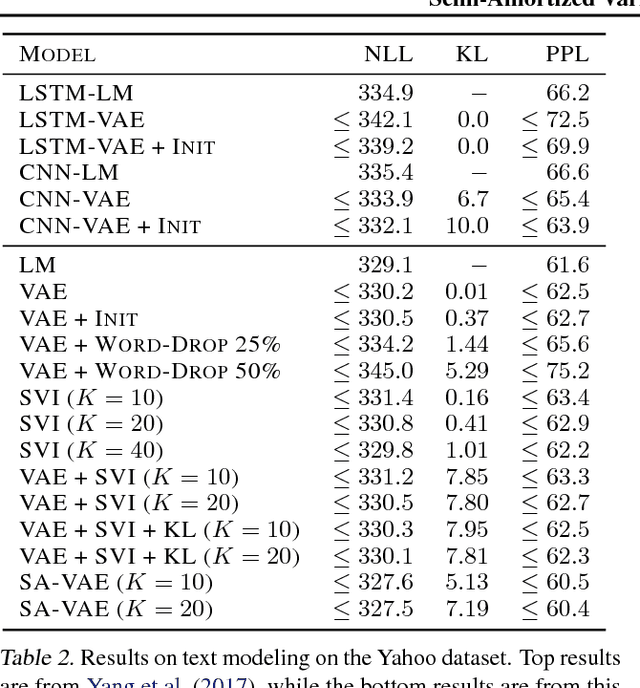
Amortized variational inference (AVI) replaces instance-specific local inference with a global inference network. While AVI has enabled efficient training of deep generative models such as variational autoencoders (VAE), recent empirical work suggests that inference networks can produce suboptimal variational parameters. We propose a hybrid approach, to use AVI to initialize the variational parameters and run stochastic variational inference (SVI) to refine them. Crucially, the local SVI procedure is itself differentiable, so the inference network and generative model can be trained end-to-end with gradient-based optimization. This semi-amortized approach enables the use of rich generative models without experiencing the posterior-collapse phenomenon common in training VAEs for problems like text generation. Experiments show this approach outperforms strong autoregressive and variational baselines on standard text and image datasets.
Challenges in Data-to-Document Generation
Jul 25, 2017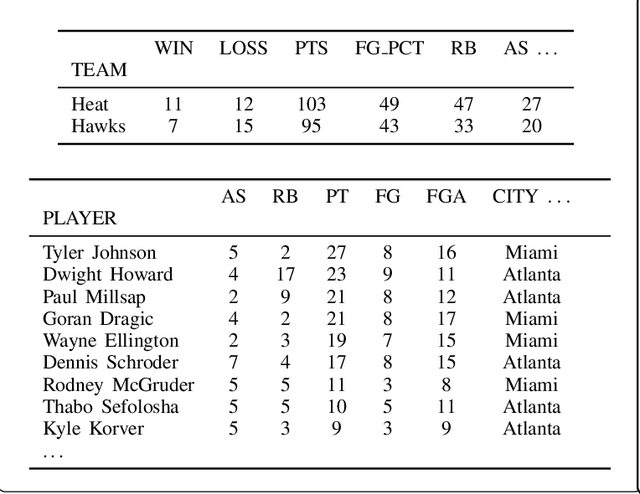
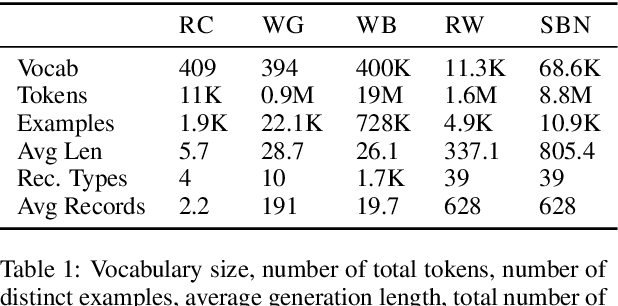

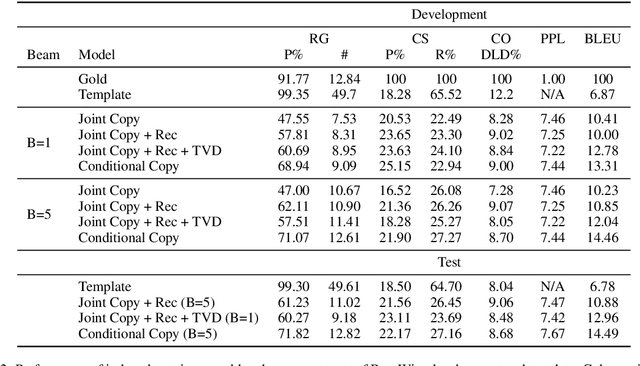
Recent neural models have shown significant progress on the problem of generating short descriptive texts conditioned on a small number of database records. In this work, we suggest a slightly more difficult data-to-text generation task, and investigate how effective current approaches are on this task. In particular, we introduce a new, large-scale corpus of data records paired with descriptive documents, propose a series of extractive evaluation methods for analyzing performance, and obtain baseline results using current neural generation methods. Experiments show that these models produce fluent text, but fail to convincingly approximate human-generated documents. Moreover, even templated baselines exceed the performance of these neural models on some metrics, though copy- and reconstruction-based extensions lead to noticeable improvements.
Training Language Models Using Target-Propagation
Feb 15, 2017



While Truncated Back-Propagation through Time (BPTT) is the most popular approach to training Recurrent Neural Networks (RNNs), it suffers from being inherently sequential (making parallelization difficult) and from truncating gradient flow between distant time-steps. We investigate whether Target Propagation (TPROP) style approaches can address these shortcomings. Unfortunately, extensive experiments suggest that TPROP generally underperforms BPTT, and we end with an analysis of this phenomenon, and suggestions for future work.
Sequence-to-Sequence Learning as Beam-Search Optimization
Nov 10, 2016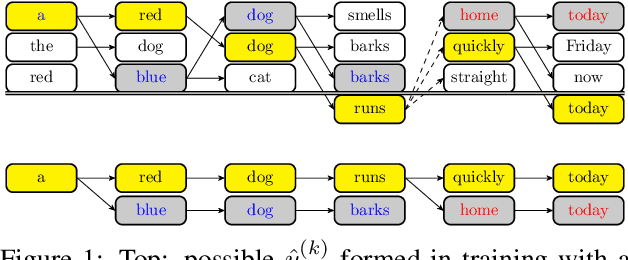
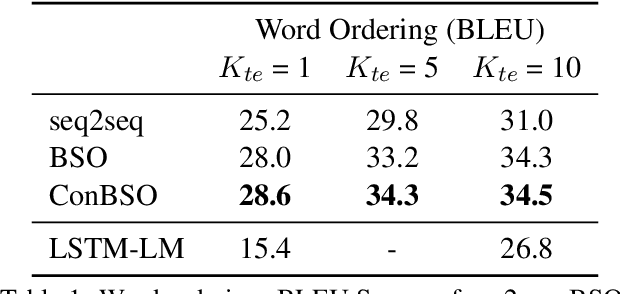
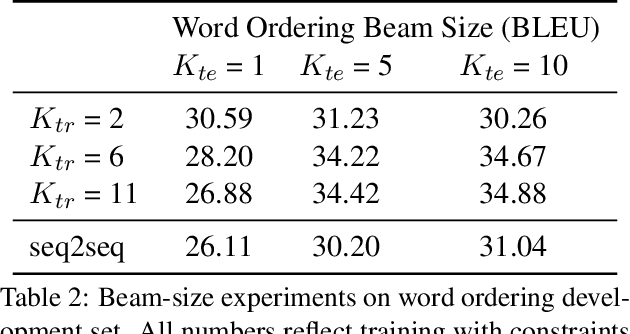

Sequence-to-Sequence (seq2seq) modeling has rapidly become an important general-purpose NLP tool that has proven effective for many text-generation and sequence-labeling tasks. Seq2seq builds on deep neural language modeling and inherits its remarkable accuracy in estimating local, next-word distributions. In this work, we introduce a model and beam-search training scheme, based on the work of Daume III and Marcu (2005), that extends seq2seq to learn global sequence scores. This structured approach avoids classical biases associated with local training and unifies the training loss with the test-time usage, while preserving the proven model architecture of seq2seq and its efficient training approach. We show that our system outperforms a highly-optimized attention-based seq2seq system and other baselines on three different sequence to sequence tasks: word ordering, parsing, and machine translation.
Learning Global Features for Coreference Resolution
Apr 11, 2016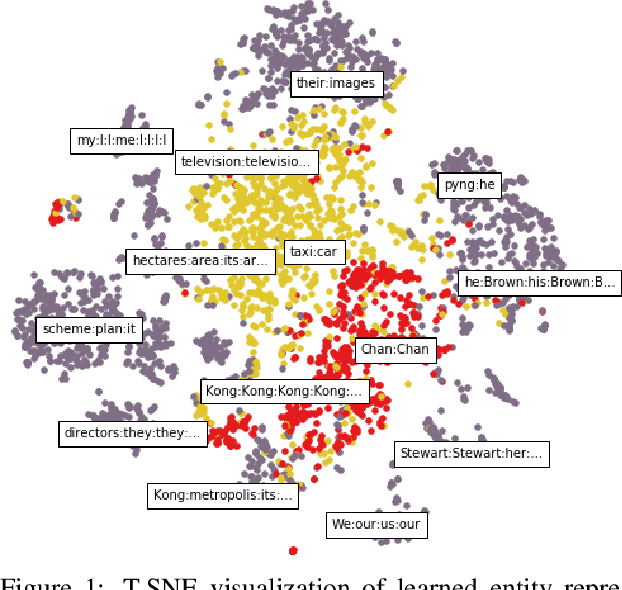
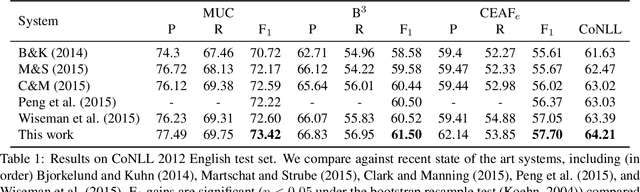

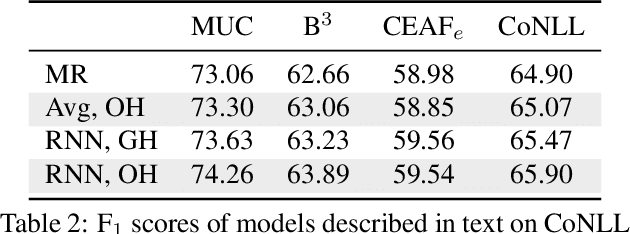
There is compelling evidence that coreference prediction would benefit from modeling global information about entity-clusters. Yet, state-of-the-art performance can be achieved with systems treating each mention prediction independently, which we attribute to the inherent difficulty of crafting informative cluster-level features. We instead propose to use recurrent neural networks (RNNs) to learn latent, global representations of entity clusters directly from their mentions. We show that such representations are especially useful for the prediction of pronominal mentions, and can be incorporated into an end-to-end coreference system that outperforms the state of the art without requiring any additional search.