 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIC: Self-Supervised Learning with Iterative Clustering for Human Action Videos
Jun 25, 2022
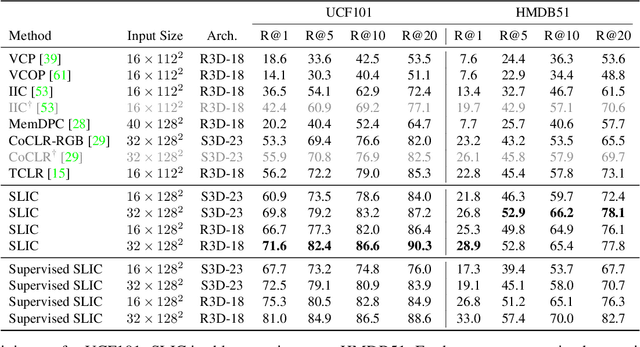
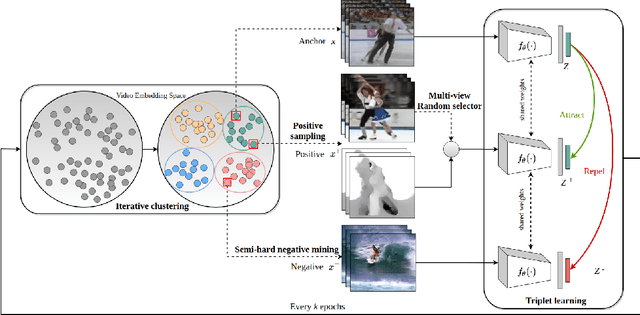
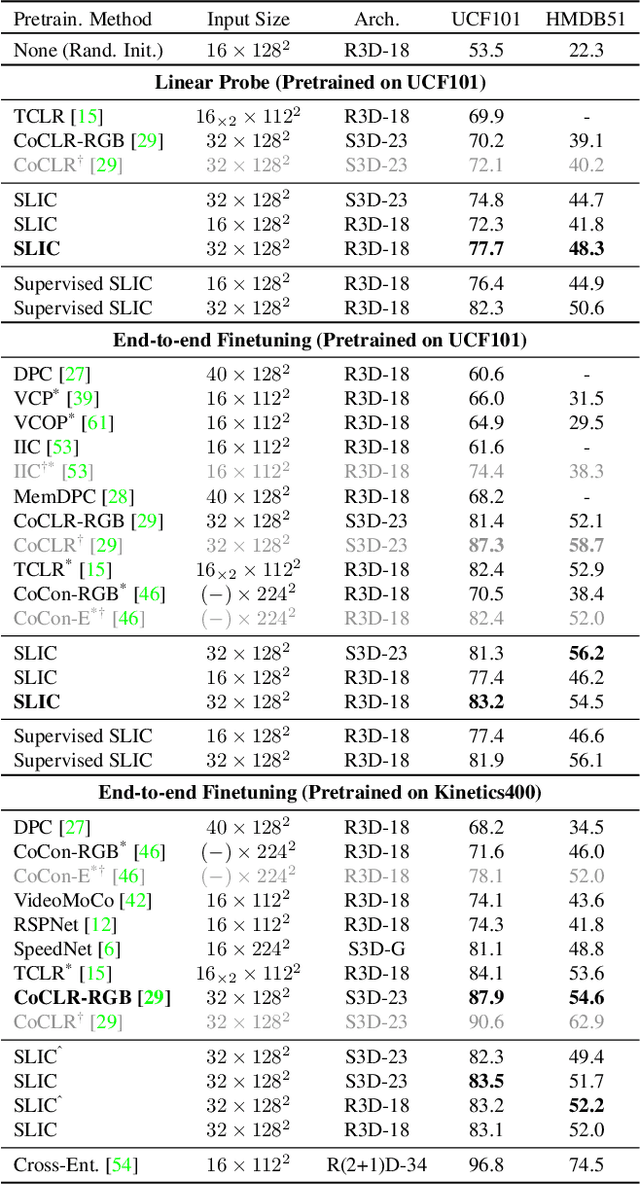
Self-supervised methods have significantly closed the gap with end-to-end supervised learning for image classification. In the case of human action videos, however, where both appearance and motion are significant factors of variation, this gap remains significant. One of the key reasons for this is that sampling pairs of similar video clips, a required step for many self-supervised contrastive learning methods, is currently done conservatively to avoid false positives. A typical assumption is that similar clips only occur temporally close within a single video, leading to insufficient examples of motion similarity. To mitigate this, we propose SLIC, a clustering-based self-supervised contrastive learning method for human action videos. Our key contribution is that we improve upon the traditional intra-video positive sampling by using iterative clustering to group similar video instances. This enables our method to leverage pseudo-labels from the cluster assignments to sample harder positives and negatives. SLIC outperforms state-of-the-art video retrieval baselines by +15.4% on top-1 recall on UCF101 and by +5.7% when directly transferred to HMDB51. With end-to-end finetuning for action classification, SLIC achieves 83.2% top-1 accuracy (+0.8%) on UCF101 and 54.5% on HMDB51 (+1.6%). SLIC is also competitive with the state-of-the-art in action classification after self-supervised pretraining on Kinetics400.