 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Road Surface Classification Using Machine Learning on Production Vehicle Signals During Cruising
Jun 01, 2026Knowledge of real-time road slipperiness, or even better, a refined estimate of peak grip potential, is a critical input for vehicle warning and intervention control systems. Typically, friction is estimated through dynamics-based recursive estimators by calculating the slip slope; however, its efficacy is heavily constrained by the vehicle dynamic scenario. When the vehicle is cruising and there is little to no slip, these methods become ineffective due to the inability of present-day production-grade sensors, such as wheel speed sensors, and methods to either measure or accurately estimate micro slip, which is crucial for distinguishing different surfaces. To address this challenge, the correlation between vehicle signals and road surface condition during cruising needs to be uncovered using machine learning. In this paper, a feature-based framework and an end-to-end data-driven framework are used to correlate the statistics of vehicle dynamics behavior with the condition of the road surface and perform binary classification into grip, dry or damp, and slip, snow or ice, conditions. A sliding-window approach is adopted to batch a short buffered window of wheel speeds, wheel torques, longitudinal acceleration, steering angle, and yaw rate, which are fed into a machine learning module for predicting the road state. Validation results on public-road data show scenarios where the data-driven method identifies the road surface correctly even during cruising, showing promise for accurate data-driven friction-related state estimators in the field of tire and vehicle dynamics.
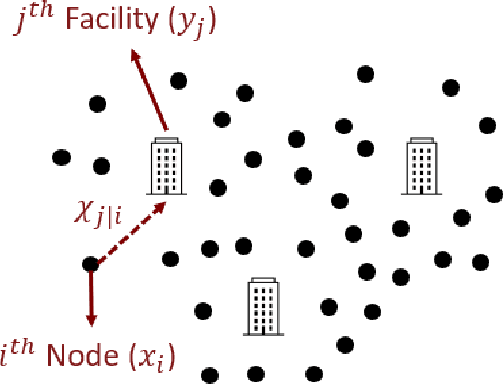
Parametrized Multi-Agent Routing via Deep Attention Models
Jul 30, 2025We propose a scalable deep learning framework for parametrized sequential decision-making (ParaSDM), where multiple agents jointly optimize discrete action policies and shared continuous parameters. A key subclass of this setting arises in Facility-Location and Path Optimization (FLPO), where multi-agent systems must simultaneously determine optimal routes and facility locations, aiming to minimize the cumulative transportation cost within the network. FLPO problems are NP-hard due to their mixed discrete-continuous structure and highly non-convex objective. To address this, we integrate the Maximum Entropy Principle (MEP) with a neural policy model called the Shortest Path Network (SPN)-a permutation-invariant encoder-decoder that approximates the MEP solution while enabling efficient gradient-based optimization over shared parameters. The SPN achieves up to 100$\times$ speedup in policy inference and gradient computation compared to MEP baselines, with an average optimality gap of approximately 6% across a wide range of problem sizes. Our FLPO approach yields over 10$\times$ lower cost than metaheuristic baselines while running significantly faster, and matches Gurobi's optimal cost with annealing at a 1500$\times$ speedup-establishing a new state of the art for ParaSDM problems. These results highlight the power of structured deep models for solving large-scale mixed-integer optimization tasks.
Sequence Generation via Subsequence Similarity: Theory and Application to UAV Identification
Jan 20, 2023



The ability to generate synthetic sequences is crucial for a wide range of applications, and recent advances in deep learning architectures and generative frameworks have greatly facilitated this process. Particularly, unconditional one-shot generative models constitute an attractive line of research that focuses on capturing the internal information of a single image, video, etc. to generate samples with similar contents. Since many of those one-shot models are shifting toward efficient non-deep and non-adversarial approaches, we examine the versatility of a one-shot generative model for augmenting whole datasets. In this work, we focus on how similarity at the subsequence level affects similarity at the sequence level, and derive bounds on the optimal transport of real and generated sequences based on that of corresponding subsequences. We use a one-shot generative model to sample from the vicinity of individual sequences and generate subsequence-similar ones and demonstrate the improvement of this approach by applying it to the problem of Unmanned Aerial Vehicle (UAV) identification using limited radio-frequency (RF) signals. In the context of UAV identification, RF fingerprinting is an effective method for distinguishing legitimate devices from malicious ones, but heterogenous environments and channel impairments can impose data scarcity and affect the performance of classification models. By using subsequence similarity to augment sequences of RF data with a low ratio (5\%-20\%) of training dataset, we achieve significant improvements in performance metrics such as accuracy, precision, recall, and F1 score.
Orthogonal Non-negative Matrix Factorization: a Maximum-Entropy-Principle Approach
Oct 06, 2022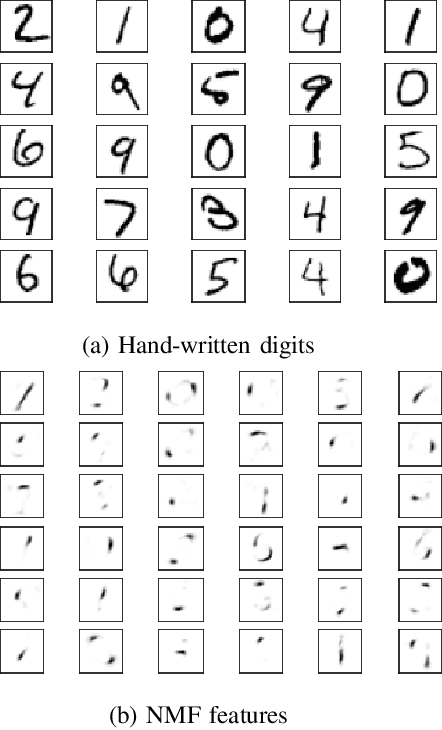


In this paper, we introduce a new methodology to solve the orthogonal non-negative matrix factorization (ONMF) problem, where the objective is to approximate an input data matrix by the product of two non-negative matrices, the features matrix and the mixing matrix, while one of them is orthogonal. We show how the ONMF can be interpreted as a specific facility-location problem (FLP), and adapt a maximum-entropy-principle based solution for FLP to the ONMF problem. The proposed approach guarantees orthogonality of the features or the mixing matrix, while ensuring that both of the matrix factors are non-negative. Also, the features (mixing) matrix has exactly one non-zero element across each row (column), providing the maximum sparsity of the orthogonal factor. This enables a semantic interpretation of the underlying data matrix using non-overlapping features. The experiments on synthetic data and a standard microarray dataset demonstrate significant improvements in terms of sparsity and orthogonality scores of features (mixing) matrices, while achieving approximately the same or better (up to 3%) reconstruction errors.