 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA DSP-Free Carrier Phase Recovery System using 16-Offset-QAM Laser Forwarded Links for 400Gb/s and Beyond
May 24, 2025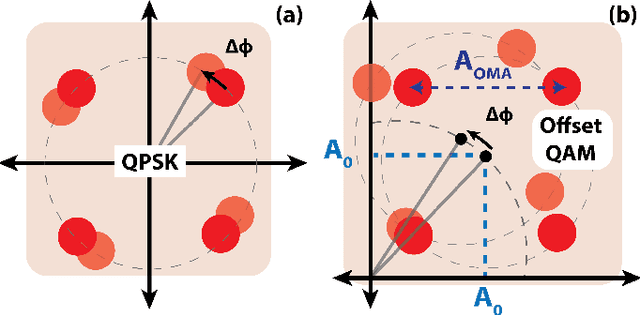
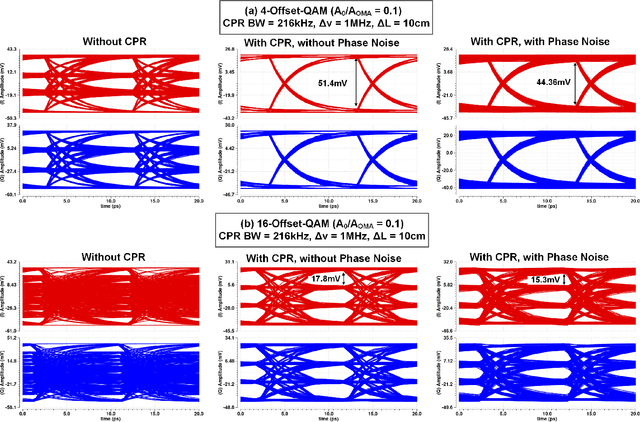
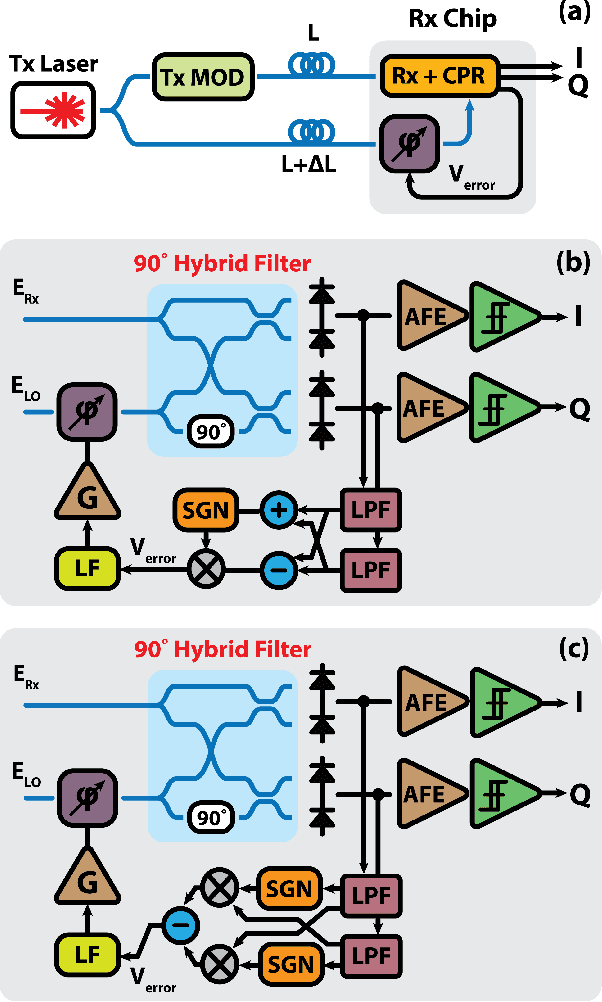
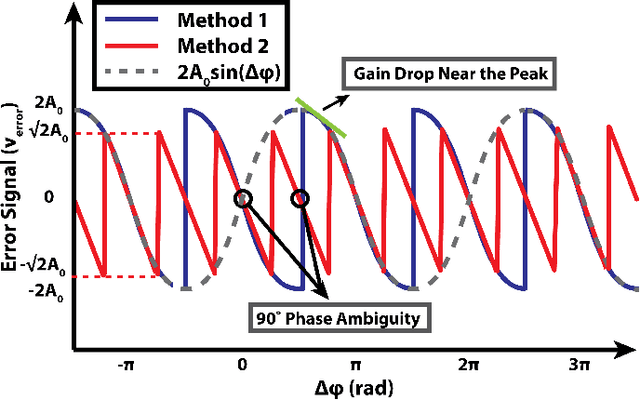
Optical interconnects are becoming a major bottleneck in scaling up future GPU racks and network switches within data centers. Although 200 Gb/s optical transceivers using PAM-4 modulation have been demonstrated, achieving higher data rates and energy efficiencies requires high-order coherent modulations like 16-QAM. Current coherent links rely on energy-intensive digital signal processing (DSP) for channel impairment compensation and carrier phase recovery (CPR), which consumes approximately 50pJ/b - 10x higher than future intra-data center requirements. For shorter links, simpler or DSP-free CPR methods can significantly reduce power and complexity. While Costas loops enable CPR for QPSK, they face challenges in scaling to higher-order modulations (e.g., 16/64-QAM) due to varying symbol amplitudes. In this work, we propose an optical coherent link architecture using laser forwarding and a novel DSP-free CPR system using offset-QAM modulation. The proposed analog CPR feedback loop is highly scalable, capable of supporting arbitrary offset-QAM modulations without requiring architectural modifications. This scalability is achieved through its phase error detection mechanism, which operates independently of the data rate and modulation type. We validated this method using GlobalFoundry's monolithic 45nm silicon photonics PDK models, with circuit- and system-level implementation at 100GBaud in the O-band. We will investigate the feedback loop dynamics, circuit-level implementations, and phase-noise performance of the proposed CPR loop. Our method can be adopted to realize low-power QAM optical interconnects for future coherent-lite pluggable transceivers as well as co-packaged optics (CPO) applications.
A 10.8mW Mixed-Signal Simulated Bifurcation Ising Solver using SRAM Compute-In-Memory with 0.6us Time-to-Solution
Apr 14, 2025Combinatorial optimization problems are funda- mental for various fields ranging from finance to wireless net- works. This work presents a simulated bifurcation (SB) Ising solver in CMOS for NP-hard optimization problems. Analog domain computing led to a superior implementation of this algorithm as inherent and injected noise is required in SB Ising solvers. The architecture novelties include the use of SRAM compute-in-memory (CIM) to accelerate bifurcation as well as the generation and injection of optimal decaying noise in the analog domain. We propose a novel 10-T SRAM cell capable of performing ternary multiplication. When measured with 60- node, 50% density, random, binary MAXCUT graphs, this all- to-all connected Ising solver reliably achieves above 93% of the ground state solution in 0.6us with 10.8mW average power in TSMC 180nm CMOS. Our chip achieves an order of magnitude improvement in time-to-solution and power compared to previously proposed Ising solvers in CMOS and other platforms.