 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Language Priors in Visual Question Answering with Adversarial Regularization
Oct 08, 2018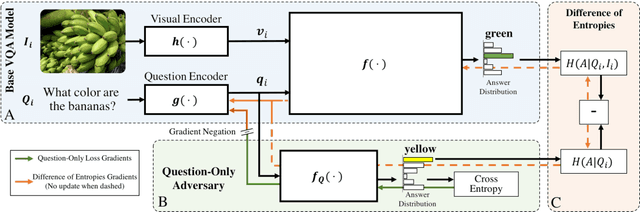
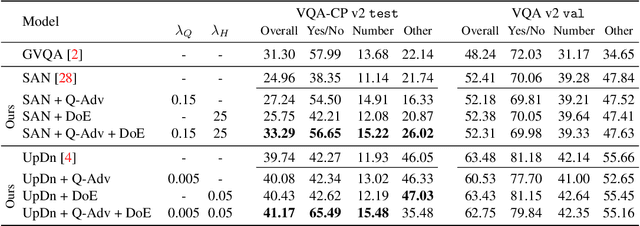
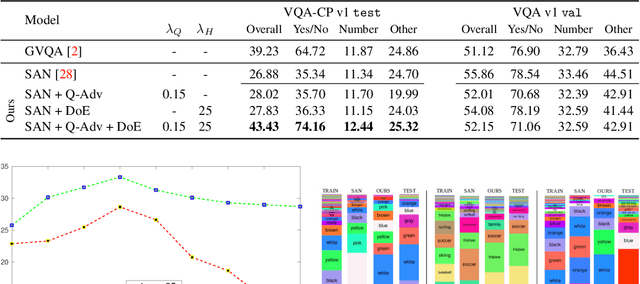

Modern Visual Question Answering (VQA) models have been shown to rely heavily on superficial correlations between question and answer words learned during training such as overwhelmingly reporting the type of room as kitchen or the sport being played as tennis, irrespective of the image. Most alarmingly, this shortcoming is often not well reflected during evaluation because the same strong priors exist in test distributions; however, a VQA system that fails to ground questions in image content would likely perform poorly in real-world settings. In this work, we present a novel regularization scheme for VQA that reduces this effect. We introduce a question-only model that takes as input the question encoding from the VQA model and must leverage language biases in order to succeed. We then pose training as an adversarial game between the VQA model and this question-only adversary -- discouraging the VQA model from capturing language biases in its question encoding. Further,we leverage this question-only model to estimate the increase in model confidence after considering the image, which we maximize explicitly to encourage visual grounding. Our approach is a model agnostic training procedure and simple to implement. We show empirically that it can improve performance significantly on a bias-sensitive split of the VQA dataset for multiple base models -- achieving state-of-the-art on this task. Further, on standard VQA tasks, our approach shows significantly less drop in accuracy compared to existing bias-reducing VQA models.
Deep Generative Filter for Motion Deblurring
Sep 11, 2017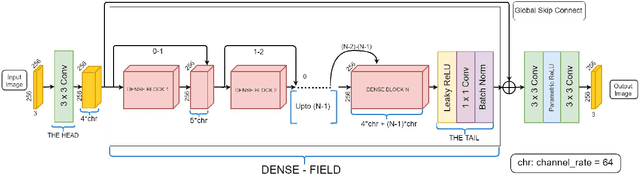
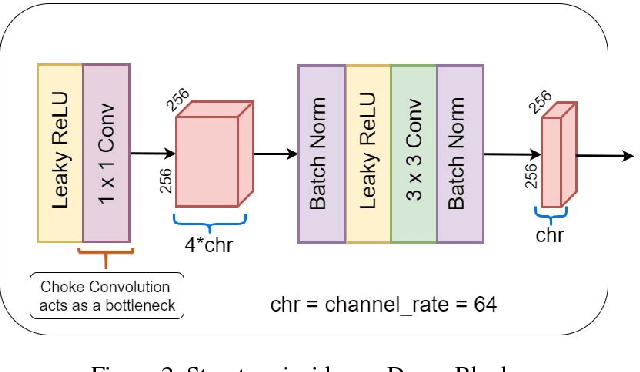

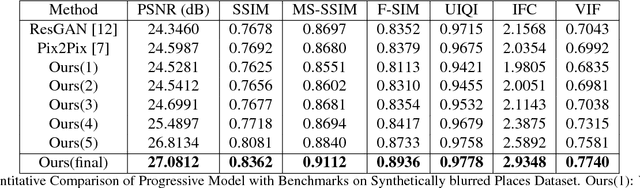
Removing blur caused by camera shake in images has always been a challenging problem in computer vision literature due to its ill-posed nature. Motion blur caused due to the relative motion between the camera and the object in 3D space induces a spatially varying blurring effect over the entire image. In this paper, we propose a novel deep filter based on Generative Adversarial Network (GAN) architecture integrated with global skip connection and dense architecture in order to tackle this problem. Our model, while bypassing the process of blur kernel estimation, significantly reduces the test time which is necessary for practical applications. The experiments on the benchmark datasets prove the effectiveness of the proposed method which outperforms the state-of-the-art blind deblurring algorithms both quantitatively and qualitatively.