 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2015 Task 10: Sentiment Analysis in Twitter
Dec 05, 2019

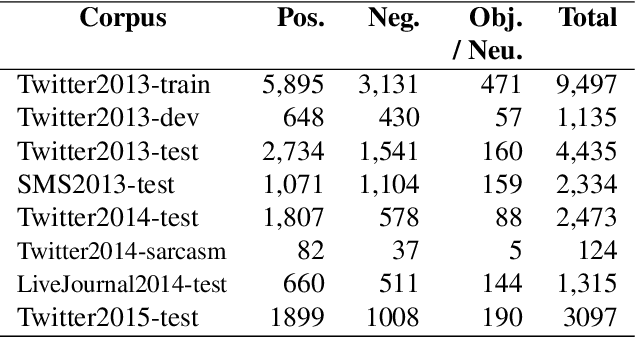
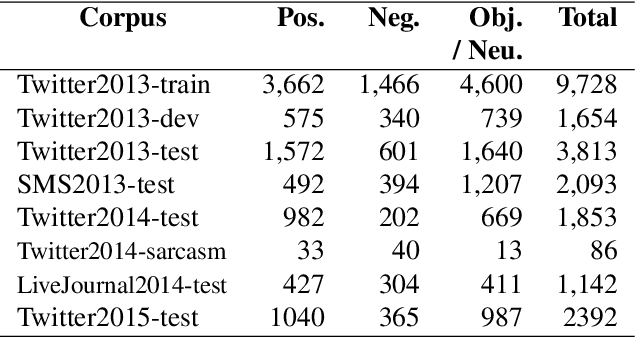
In this paper, we describe the 2015 iteration of the SemEval shared task on Sentiment Analysis in Twitter. This was the most popular sentiment analysis shared task to date with more than 40 teams participating in each of the last three years. This year's shared task competition consisted of five sentiment prediction subtasks. Two were reruns from previous years: (A) sentiment expressed by a phrase in the context of a tweet, and (B) overall sentiment of a tweet. We further included three new subtasks asking to predict (C) the sentiment towards a topic in a single tweet, (D) the overall sentiment towards a topic in a set of tweets, and (E) the degree of prior polarity of a phrase.
* Sentiment analysis, sentiment towards a topic, quantification, microblog sentiment analysis; Twitter opinion mining
Distributional Measures as Proxies for Semantic Relatedness
Mar 08, 2012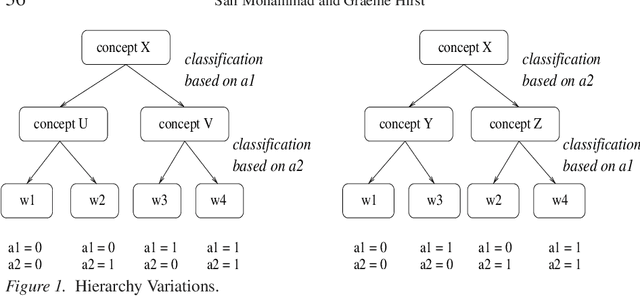


The automatic ranking of word pairs as per their semantic relatedness and ability to mimic human notions of semantic relatedness has widespread applications. Measures that rely on raw data (distributional measures) and those that use knowledge-rich ontologies both exist. Although extensive studies have been performed to compare ontological measures with human judgment, the distributional measures have primarily been evaluated by indirect means. This paper is a detailed study of some of the major distributional measures; it lists their respective merits and limitations. New measures that overcome these drawbacks, that are more in line with the human notions of semantic relatedness, are suggested. The paper concludes with an exhaustive comparison of the distributional and ontology-based measures. Along the way, significant research problems are identified. Work on these problems may lead to a better understanding of how semantic relatedness is to be measured.