 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLO: A Corpus of Tweets for Examining the State of Being Alone
Jun 04, 2020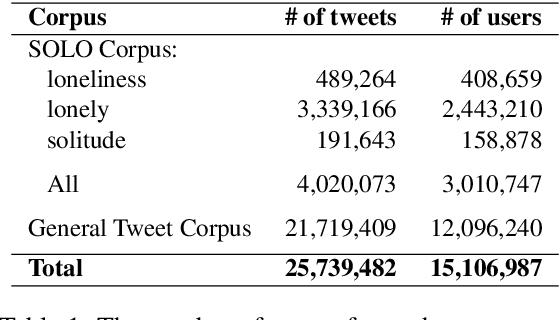
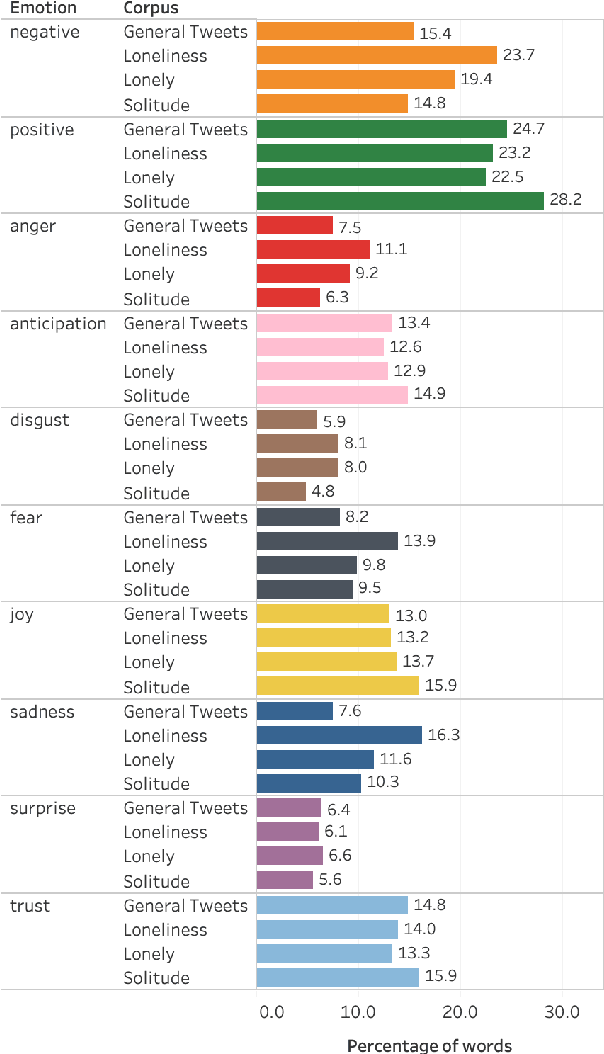

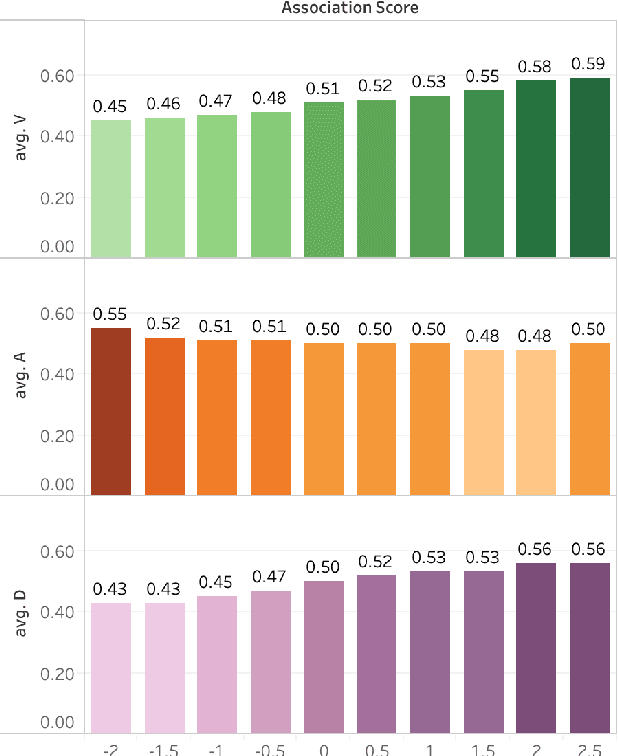
The state of being alone can have a substantial impact on our lives, though experiences with time alone diverge significantly among individuals. Psychologists distinguish between the concept of solitude, a positive state of voluntary aloneness, and the concept of loneliness, a negative state of dissatisfaction with the quality of one's social interactions. Here, for the first time, we conduct a large-scale computational analysis to explore how the terms associated with the state of being alone are used in online language. We present SOLO (State of Being Alone), a corpus of over 4 million tweets collected with query terms 'solitude', 'lonely', and 'loneliness'. We use SOLO to analyze the language and emotions associated with the state of being alone. We show that the term 'solitude' tends to co-occur with more positive, high-dominance words (e.g., enjoy, bliss) while the terms 'lonely' and 'loneliness' frequently co-occur with negative, low-dominance words (e.g., scared, depressed), which confirms the conceptual distinctions made in psychology. We also show that women are more likely to report on negative feelings of being lonely as compared to men, and there are more teenagers among the tweeters that use the word 'lonely' than among the tweeters that use the word 'solitude'.
NLP Scholar: An Interactive Visual Explorer for Natural Language Processing Literature
May 31, 2020


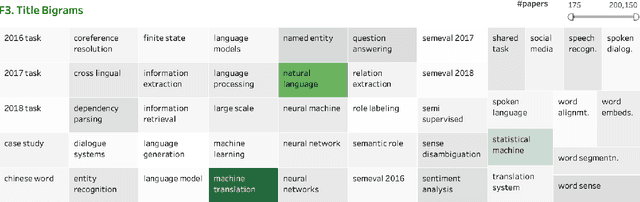
As part of the NLP Scholar project, we created a single unified dataset of NLP papers and their meta-information (including citation numbers), by extracting and aligning information from the ACL Anthology and Google Scholar. In this paper, we describe several interconnected interactive visualizations (dashboards) that present various aspects of the data. Clicking on an item within a visualization or entering query terms in the search boxes filters the data in all visualizations in the dashboard. This allows users to search for papers in the area of their interest, published within specific time periods, published by specified authors, etc. The interactive visualizations presented here, and the associated dataset of papers mapped to citations, have additional uses as well including understanding how the field is growing (both overall and across sub-areas), as well as quantifying the impact of different types of papers on subsequent publications.
* arXiv admin note: text overlap with arXiv:2005.00912
Sentiment Analysis: Detecting Valence, Emotions, and Other Affectual States from Text
May 25, 2020
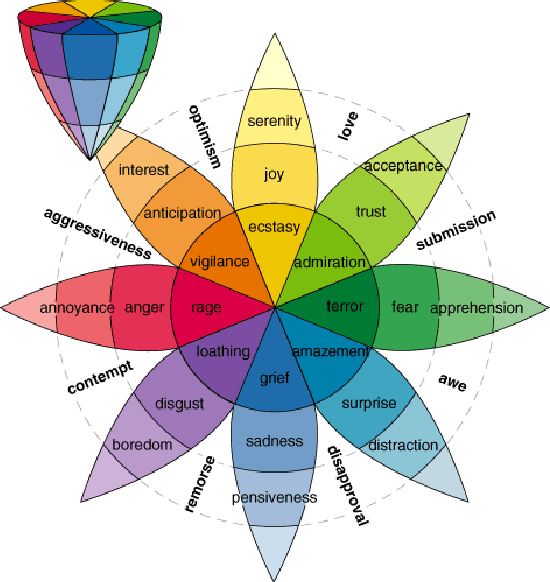
Recent advances in machine learning have led to computer systems that are human-like in behaviour. Sentiment analysis, the automatic determination of emotions in text, is allowing us to capitalize on substantial previously unattainable opportunities in commerce, public health, government policy, social sciences, and art. Further, analysis of emotions in text, from news to social media posts, is improving our understanding of not just how people convey emotions through language but also how emotions shape our behaviour. This article presents a sweeping overview of sentiment analysis research that includes: the origins of the field, the rich landscape of tasks, challenges, a survey of the methods and resources used, and applications. We also discuss discuss how, without careful fore-thought, sentiment analysis has the potential for harmful outcomes. We outline the latest lines of research in pursuit of fairness in sentiment analysis.
* This is the author's manuscript of what is slated to appear in the Second Edition of Emotion Measurement, 2020
PoKi: A Large Dataset of Poems by Children
May 03, 2020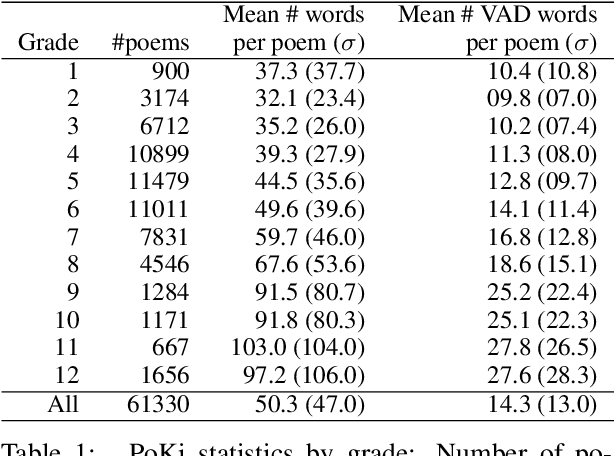
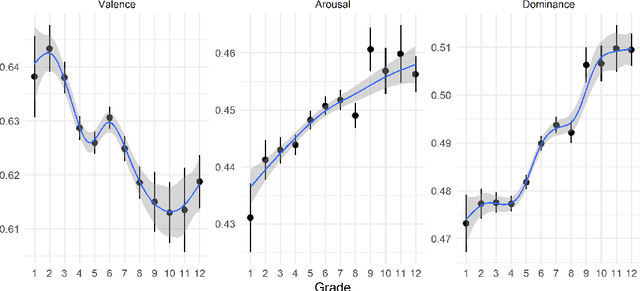
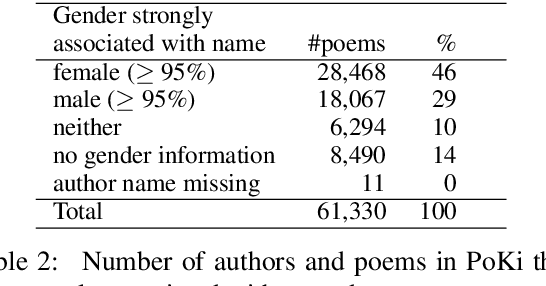
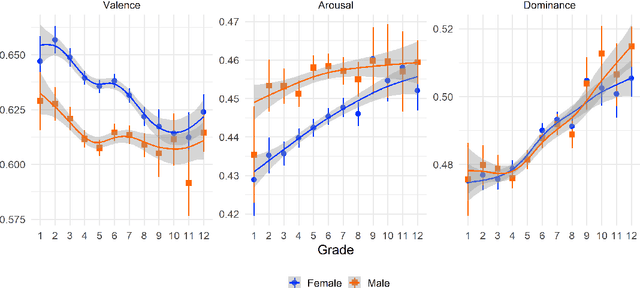
Child language studies are crucial in improving our understanding of child well-being; especially in determining the factors that impact happiness, the sources of anxiety, techniques of emotion regulation, and the mechanisms to cope with stress. However, much of this research is stymied by the lack of availability of large child-written texts. We present a new corpus of child-written text, PoKi, which includes about 62 thousand poems written by children from grades 1 to 12. PoKi is especially useful in studying child language because it comes with information about the age of the child authors (their grade). We analyze the words in PoKi along several emotion dimensions (valence, arousal, dominance) and discrete emotions (anger, fear, sadness, joy). We use non-parametric regressions to model developmental differences from early childhood to late-adolescence. Results show decreases in valence that are especially pronounced during mid-adolescence, while arousal and dominance peaked during adolescence. Gender differences in the developmental trajectory of emotions are also observed. Our results support and extend the current state of emotion development research.
Gender Gap in Natural Language Processing Research: Disparities in Authorship and Citations
May 03, 2020
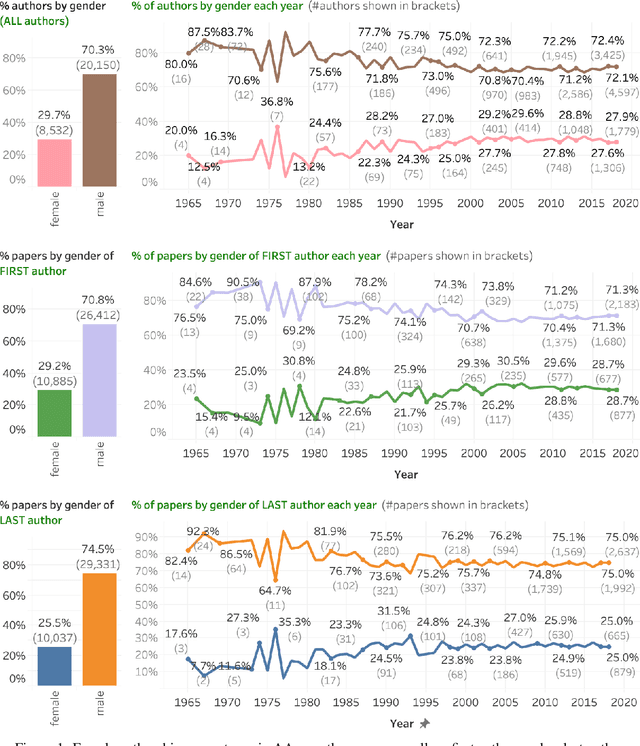
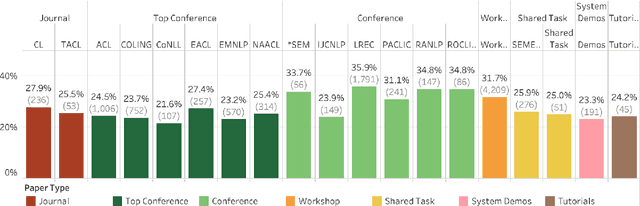
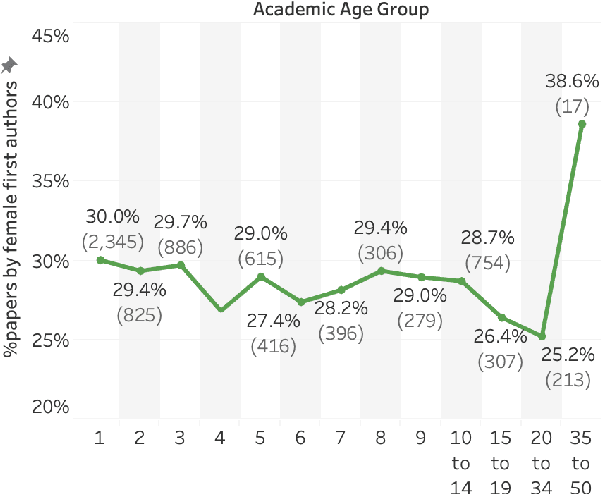
Disparities in authorship and citations across genders can have substantial adverse consequences not just on the disadvantaged gender, but also on the field of study as a whole. In this work, we examine female first author percentages and the citations to their papers in Natural Language Processing. We find that only about 29% of first authors are female and only about 25% of last authors are female. Notably, this percentage has not improved since the mid 2000s. We also show that, on average, female first authors are cited less than male first authors, even when controlling for experience and area of research. We hope that recording citation and participation gaps across demographic groups will improve awareness of gender gaps and encourage more inclusiveness and fairness in research.
Examining Citations of Natural Language Processing Literature
May 02, 2020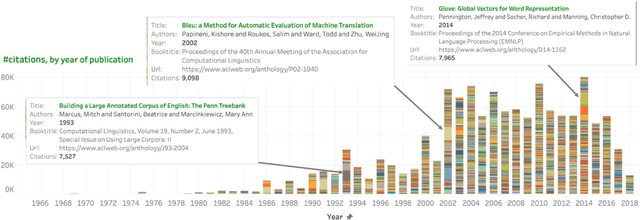

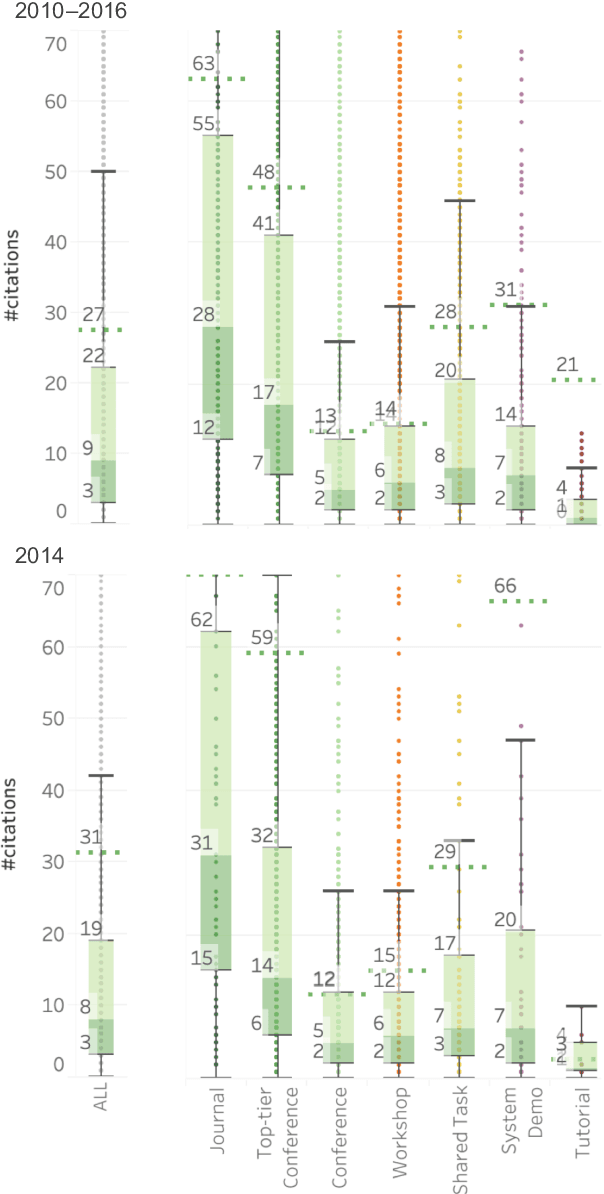
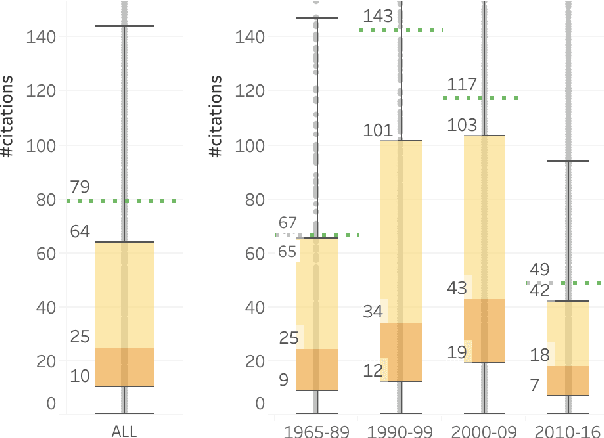
We extracted information from the ACL Anthology (AA) and Google Scholar (GS) to examine trends in citations of NLP papers. We explore questions such as: how well cited are papers of different types (journal articles, conference papers, demo papers, etc.)? how well cited are papers from different areas of within NLP? etc. Notably, we show that only about 56\% of the papers in AA are cited ten or more times. CL Journal has the most cited papers, but its citation dominance has lessened in recent years. On average, long papers get almost three times as many citations as short papers; and papers on sentiment classification, anaphora resolution, and entity recognition have the highest median citations. The analyses presented here, and the associated dataset of NLP papers mapped to citations, have a number of uses including: understanding how the field is growing and quantifying the impact of different types of papers.
The State of NLP Literature: A Diachronic Analysis of the ACL Anthology
Nov 08, 2019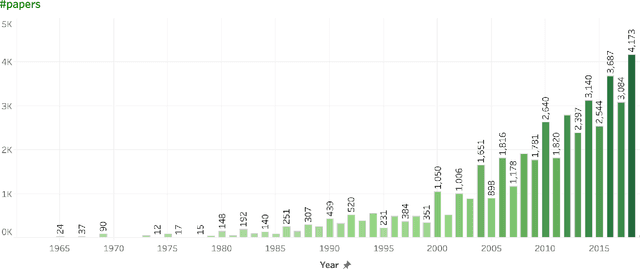
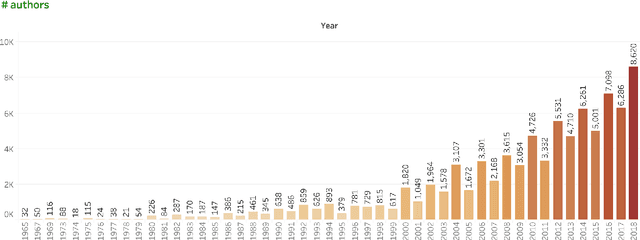
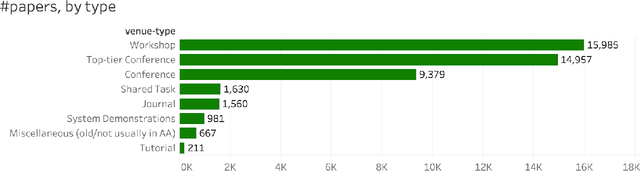
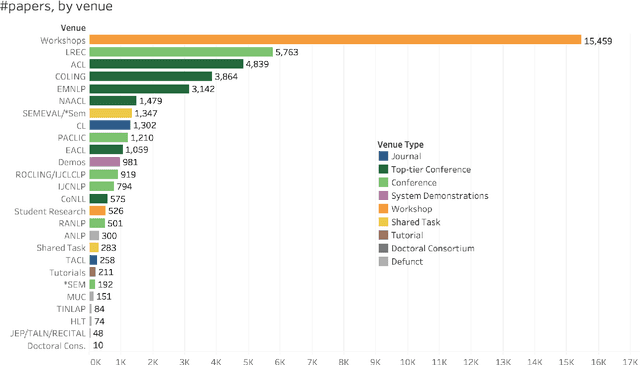
The ACL Anthology (AA) is a digital repository of tens of thousands of articles on Natural Language Processing (NLP). This paper examines the literature as a whole to identify broad trends in productivity, focus, and impact. It presents the analyses in a sequence of questions and answers. The goal is to record the state of the AA literature: who and how many of us are publishing? what are we publishing on? where and in what form are we publishing? and what is the impact of our publications? The answers are usually in the form of numbers, graphs, and inter-connected visualizations. Special emphasis is laid on the demographics and inclusiveness of NLP publishing. Notably, we find that only about 30% of first authors are female, and that this percentage has not improved since the year 2000. We also show that, on average, female first authors are cited less than male first authors, even when controlling for experience. We hope that recording citation and participation gaps across demographic groups will encourage more inclusiveness and fairness in research.
The Natural Selection of Words: Finding the Features of Fitness
Aug 19, 2019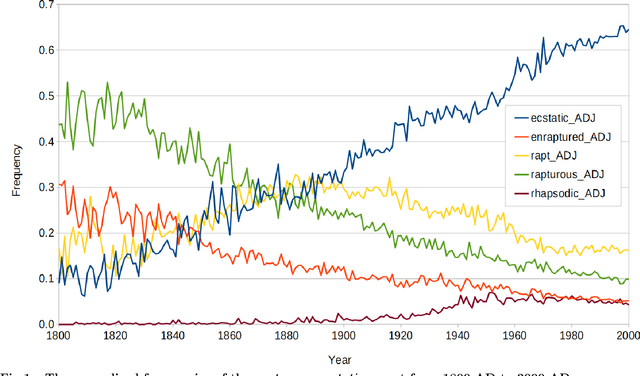
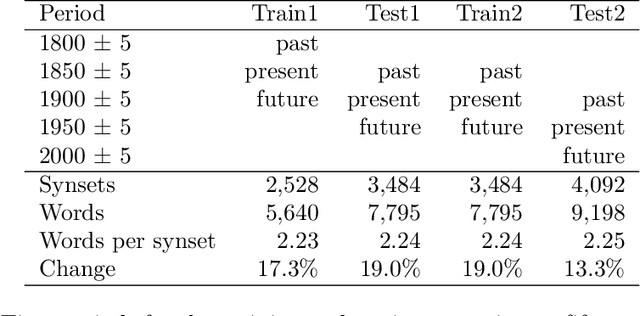
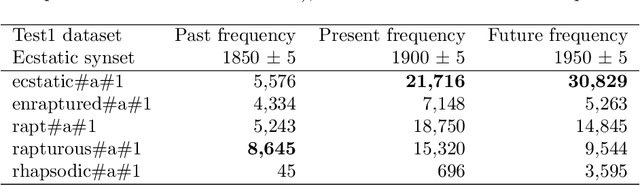
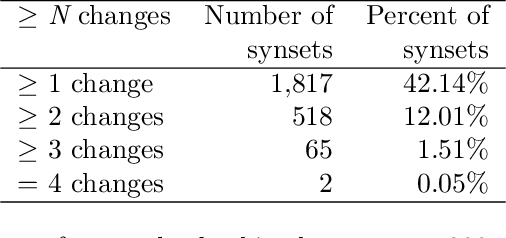
We introduce a dataset for studying the evolution of words, constructed from WordNet and the Google Books Ngram Corpus. The dataset tracks the evolution of 4,000 synonym sets (synsets), containing 9,000 English words, from 1800 AD to 2000 AD. We present a supervised learning algorithm that is able to predict the future leader of a synset: the word in the synset that will have the highest frequency. The algorithm uses features based on a word's length, the characters in the word, and the historical frequencies of the word. It can predict change of leadership (including the identity of the new leader) fifty years in the future, with an F-score considerably above random guessing. Analysis of the learned models provides insight into the causes of change in the leader of a synset. The algorithm confirms observations linguists have made, such as the trend to replace the -ise suffix with -ize, the rivalry between the -ity and -ness suffixes, and the struggle between economy (shorter words are easier to remember and to write) and clarity (longer words are more distinctive and less likely to be confused with one another). The results indicate that integration of the Google Books Ngram Corpus with WordNet has significant potential for improving our understanding of how language evolves.
IEST: WASSA-2018 Implicit Emotions Shared Task
Sep 05, 2018
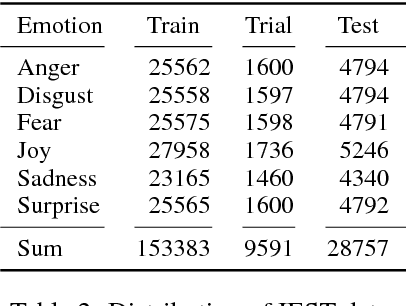
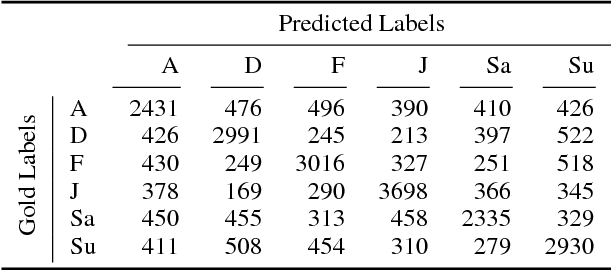
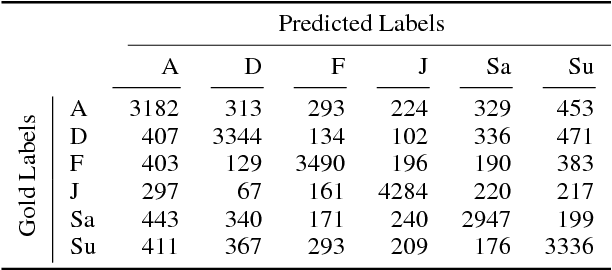
Past shared tasks on emotions use data with both overt expressions of emotions (I am so happy to see you!) as well as subtle expressions where the emotions have to be inferred, for instance from event descriptions. Further, most datasets do not focus on the cause or the stimulus of the emotion. Here, for the first time, we propose a shared task where systems have to predict the emotions in a large automatically labeled dataset of tweets without access to words denoting emotions. Based on this intention, we call this the Implicit Emotion Shared Task (IEST) because the systems have to infer the emotion mostly from the context. Every tweet has an occurrence of an explicit emotion word that is masked. The tweets are collected in a manner such that they are likely to include a description of the cause of the emotion - the stimulus. Altogether, 30 teams submitted results which range from macro F1 scores of 21 % to 71 %. The baseline (MaxEnt bag of words and bigrams) obtains an F1 score of 60 % which was available to the participants during the development phase. A study with human annotators suggests that automatic methods outperform human predictions, possibly by honing into subtle textual clues not used by humans. Corpora, resources, and results are available at the shared task website at http://implicitemotions.wassa2018.com.
NRC-Canada at SMM4H Shared Task: Classifying Tweets Mentioning Adverse Drug Reactions and Medication Intake
May 11, 2018

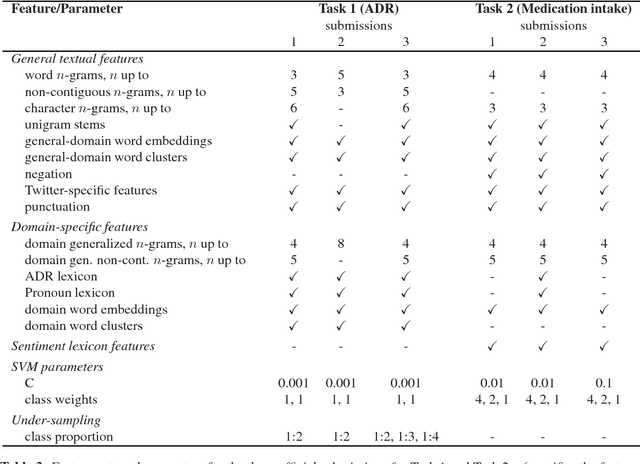
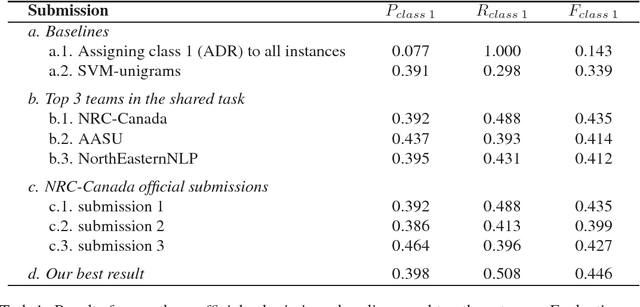
Our team, NRC-Canada, participated in two shared tasks at the AMIA-2017 Workshop on Social Media Mining for Health Applications (SMM4H): Task 1 - classification of tweets mentioning adverse drug reactions, and Task 2 - classification of tweets describing personal medication intake. For both tasks, we trained Support Vector Machine classifiers using a variety of surface-form, sentiment, and domain-specific features. With nine teams participating in each task, our submissions ranked first on Task 1 and third on Task 2. Handling considerable class imbalance proved crucial for Task 1. We applied an under-sampling technique to reduce class imbalance (from about 1:10 to 1:2). Standard n-gram features, n-grams generalized over domain terms, as well as general-domain and domain-specific word embeddings had a substantial impact on the overall performance in both tasks. On the other hand, including sentiment lexicon features did not result in any improvement.