 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the Impact of Stochasticity on the Evaluation of Deep Neural Networks for Forest-Fire Prediction
Feb 23, 2024



This paper presents the first systematic study of the evaluation of Deep Neural Networks (DNNs) for discrete dynamical systems under stochastic assumptions, with a focus on wildfire prediction. We develop a framework to study the impact of stochasticity on two classes of evaluation metrics: classification-based metrics, which assess fidelity to observed ground truth (GT), and proper scoring rules, which test fidelity-to-statistic. Our findings reveal that evaluating for fidelity-to-statistic is a reliable alternative in highly stochastic scenarios. We extend our analysis to real-world wildfire data, highlighting limitations in traditional wildfire prediction evaluation methods, and suggest interpretable stochasticity-compatible alternatives.
Brain-Inspired Spiking Neural Network for Online Unsupervised Time Series Prediction
Apr 10, 2023



Energy and data-efficient online time series prediction for predicting evolving dynamical systems are critical in several fields, especially edge AI applications that need to update continuously based on streaming data. However, current DNN-based supervised online learning models require a large amount of training data and cannot quickly adapt when the underlying system changes. Moreover, these models require continuous retraining with incoming data making them highly inefficient. To solve these issues, we present a novel Continuous Learning-based Unsupervised Recurrent Spiking Neural Network Model (CLURSNN), trained with spike timing dependent plasticity (STDP). CLURSNN makes online predictions by reconstructing the underlying dynamical system using Random Delay Embedding by measuring the membrane potential of neurons in the recurrent layer of the RSNN with the highest betweenness centrality. We also use topological data analysis to propose a novel methodology using the Wasserstein Distance between the persistence homologies of the predicted and observed time series as a loss function. We show that the proposed online time series prediction methodology outperforms state-of-the-art DNN models when predicting an evolving Lorenz63 dynamical system.
Unsupervised 3D Object Learning through Neuron Activity aware Plasticity
Feb 22, 2023We present an unsupervised deep learning model for 3D object classification. Conventional Hebbian learning, a well-known unsupervised model, suffers from loss of local features leading to reduced performance for tasks with complex geometric objects. We present a deep network with a novel Neuron Activity Aware (NeAW) Hebbian learning rule that dynamically switches the neurons to be governed by Hebbian learning or anti-Hebbian learning, depending on its activity. We analytically show that NeAW Hebbian learning relieves the bias in neuron activity, allowing more neurons to attend to the representation of the 3D objects. Empirical results show that the NeAW Hebbian learning outperforms other variants of Hebbian learning and shows higher accuracy over fully supervised models when training data is limited.
Heterogeneous Neuronal and Synaptic Dynamics for Spike-Efficient Unsupervised Learning: Theory and Design Principles
Feb 22, 2023This paper shows that the heterogeneity in neuronal and synaptic dynamics reduces the spiking activity of a Recurrent Spiking Neural Network (RSNN) while improving prediction performance, enabling spike-efficient (unsupervised) learning. We analytically show that the diversity in neurons' integration/relaxation dynamics improves an RSNN's ability to learn more distinct input patterns (higher memory capacity), leading to improved classification and prediction performance. We further prove that heterogeneous Spike-Timing-Dependent-Plasticity (STDP) dynamics of synapses reduce spiking activity but preserve memory capacity. The analytical results motivate Heterogeneous RSNN design using Bayesian optimization to determine heterogeneity in neurons and synapses to improve $\mathcal{E}$, defined as the ratio of spiking activity and memory capacity. The empirical results on time series classification and prediction tasks show that optimized HRSNN increases performance and reduces spiking activity compared to a homogeneous RSNN.
* Paper Published in ICLR 2023 (https://openreview.net/forum?id=QIRtAqoXwj)
Forecasting local behavior of multi-agent system and its application to forest fire model
Oct 28, 2022



In this paper, we study a CNN-LSTM model to forecast the state of a specific agent in a large multi-agent system. The proposed model consists of a CNN encoder to represent the system into a low-dimensional vector, a LSTM module to learn the agent dynamics in the vector space, and a MLP decoder to predict the future state of an agent. A forest fire model is considered as an example where we need to predict when a specific tree agent will be burning. We observe that the proposed model achieves higher AUC with less computation than a frame-based model and significantly saves computational costs such as the activation than ConvLSTM.
Learning Point Processes using Recurrent Graph Network
Aug 11, 2022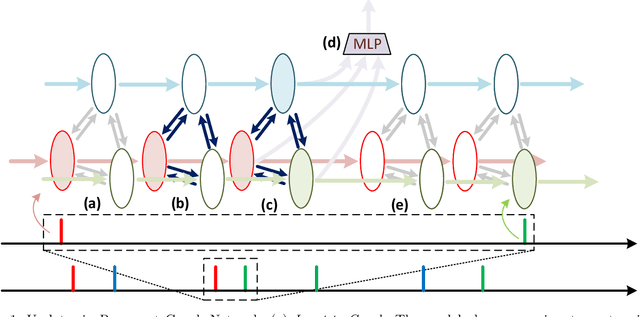
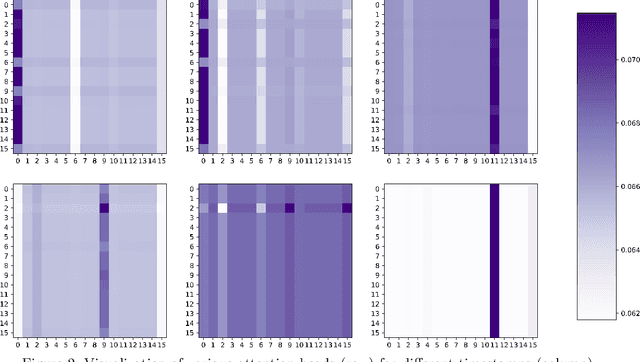
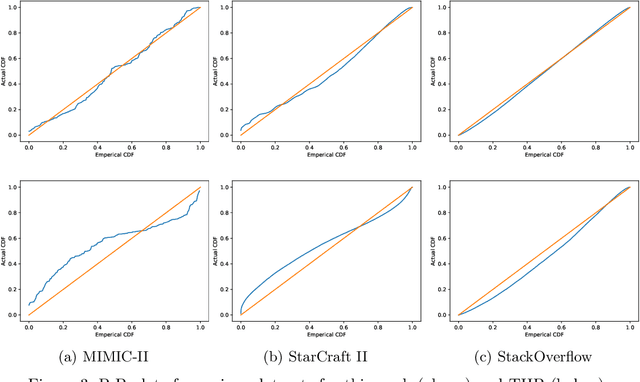

We present a novel Recurrent Graph Network (RGN) approach for predicting discrete marked event sequences by learning the underlying complex stochastic process. Using the framework of Point Processes, we interpret a marked discrete event sequence as the superposition of different sequences each of a unique type. The nodes of the Graph Network use LSTM to incorporate past information whereas a Graph Attention Network (GAT Network) introduces strong inductive biases to capture the interaction between these different types of events. By changing the self-attention mechanism from attending over past events to attending over event types, we obtain a reduction in time and space complexity from $\mathcal{O}(N^2)$ (total number of events) to $\mathcal{O}(|\mathcal{Y}|^2)$ (number of event types). Experiments show that the proposed approach improves performance in log-likelihood, prediction and goodness-of-fit tasks with lower time and space complexity compared to state-of-the art Transformer based architectures.
Radar Guided Dynamic Visual Attention for Resource-Efficient RGB Object Detection
Jun 03, 2022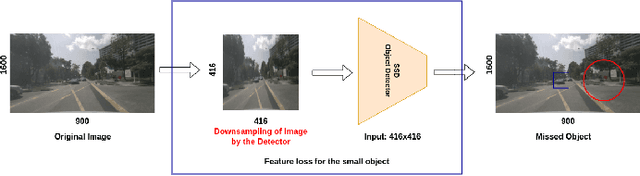

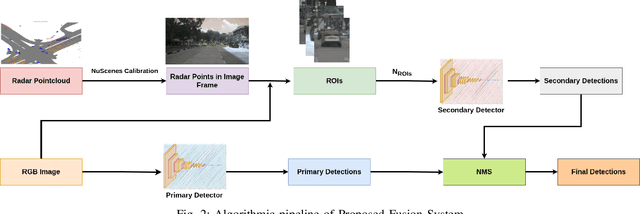

An autonomous system's perception engine must provide an accurate understanding of the environment for it to make decisions. Deep learning based object detection networks experience degradation in the performance and robustness for small and far away objects due to a reduction in object's feature map as we move to higher layers of the network. In this work, we propose a novel radar-guided spatial attention for RGB images to improve the perception quality of autonomous vehicles operating in a dynamic environment. In particular, our method improves the perception of small and long range objects, which are often not detected by the object detectors in RGB mode. The proposed method consists of two RGB object detectors, namely the Primary detector and a lightweight Secondary detector. The primary detector takes a full RGB image and generates primary detections. Next, the radar proposal framework creates regions of interest (ROIs) for object proposals by projecting the radar point cloud onto the 2D RGB image. These ROIs are cropped and fed to the secondary detector to generate secondary detections which are then fused with the primary detections via non-maximum suppression. This method helps in recovering the small objects by preserving the object's spatial features through an increase in their receptive field. We evaluate our fusion method on the challenging nuScenes dataset and show that our fusion method with SSD-lite as primary and secondary detector improves the baseline primary yolov3 detector's recall by 14% while requiring three times fewer computational resources.
RADNet: A Deep Neural Network Model for Robust Perception in Moving Autonomous Systems
Apr 30, 2022

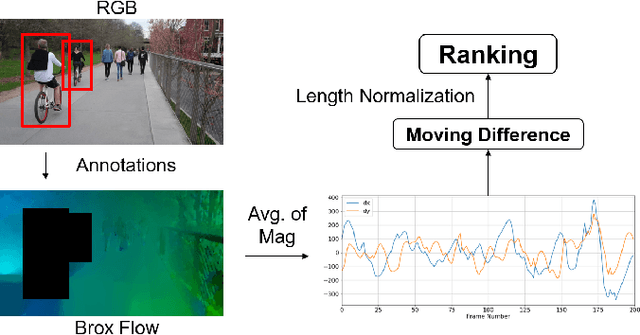
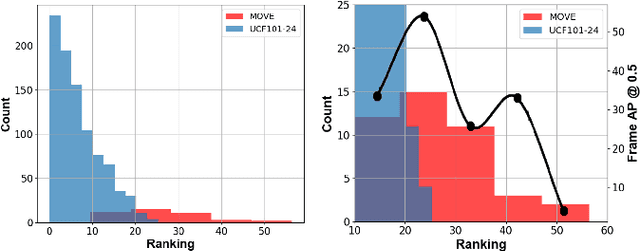
Interactive autonomous applications require robustness of the perception engine to artifacts in unconstrained videos. In this paper, we examine the effect of camera motion on the task of action detection. We develop a novel ranking method to rank videos based on the degree of global camera motion. For the high ranking camera videos we show that the accuracy of action detection is decreased. We propose an action detection pipeline that is robust to the camera motion effect and verify it empirically. Specifically, we do actor feature alignment across frames and couple global scene features with local actor-specific features. We do feature alignment using a novel formulation of the Spatio-temporal Sampling Network (STSN) but with multi-scale offset prediction and refinement using a pyramid structure. We also propose a novel input dependent weighted averaging strategy for fusing local and global features. We show the applicability of our network on our dataset of moving camera videos with high camera motion (MOVE dataset) with a 4.1% increase in frame mAP and 17% increase in video mAP.
Unraveled Multilevel Transformation Networks for Predicting Sparsely-Observed Spatiotemporal Dynamics
Mar 16, 2022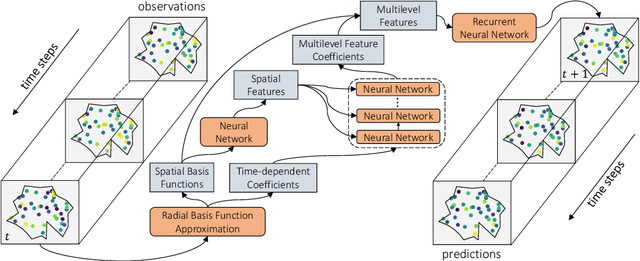

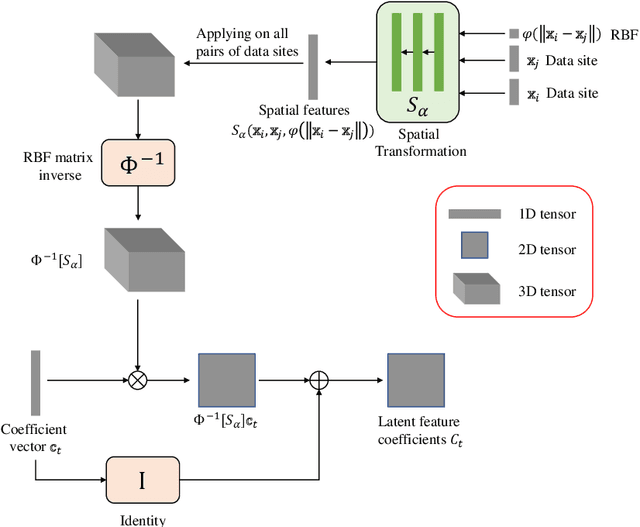

In this paper, we address the problem of predicting complex, nonlinear spatiotemporal dynamics when available data is recorded at irregularly-spaced sparse spatial locations. Most of the existing deep learning models for modeling spatiotemporal dynamics are either designed for data in a regular grid or struggle to uncover the spatial relations from sparse and irregularly-spaced data sites. We propose a deep learning model that learns to predict unknown spatiotemporal dynamics using data from sparsely-distributed data sites. We base our approach on Radial Basis Function (RBF) collocation method which is often used for meshfree solution of partial differential equations (PDEs). The RBF framework allows us to unravel the observed spatiotemporal function and learn the spatial interactions among data sites on the RBF-space. The learned spatial features are then used to compose multilevel transformations of the raw observations and predict its evolution in future time steps. We demonstrate the advantage of our approach using both synthetic and real-world climate data.
$μ$DARTS: Model Uncertainty-Aware Differentiable Architecture Search
Jul 24, 2021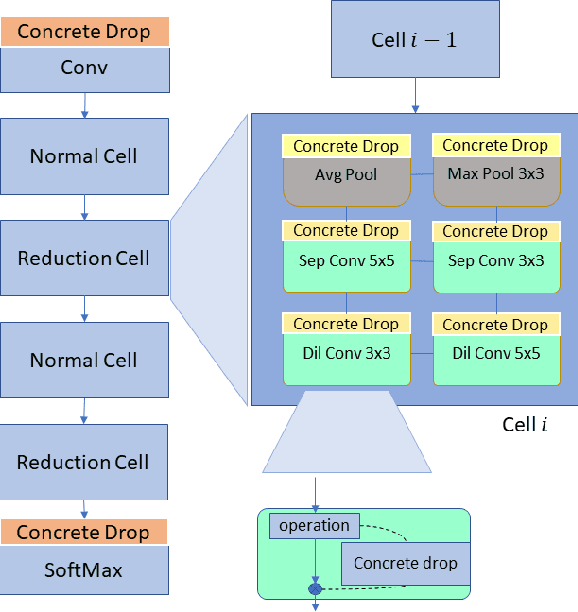
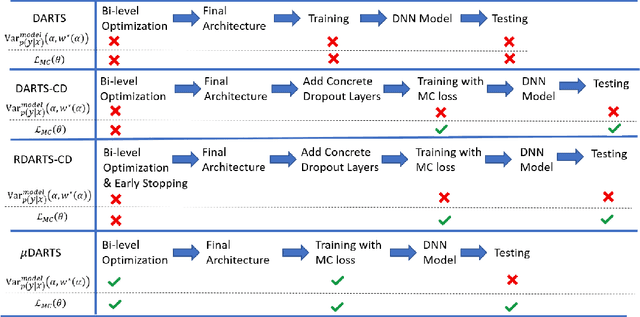
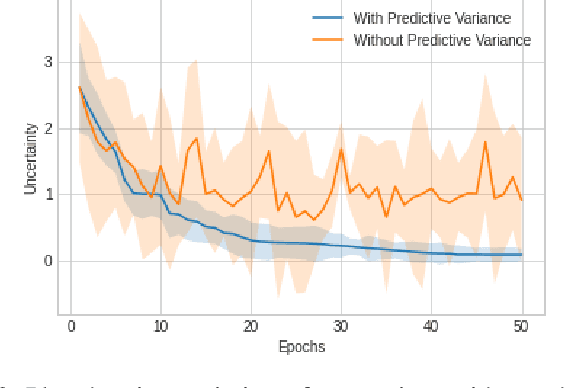
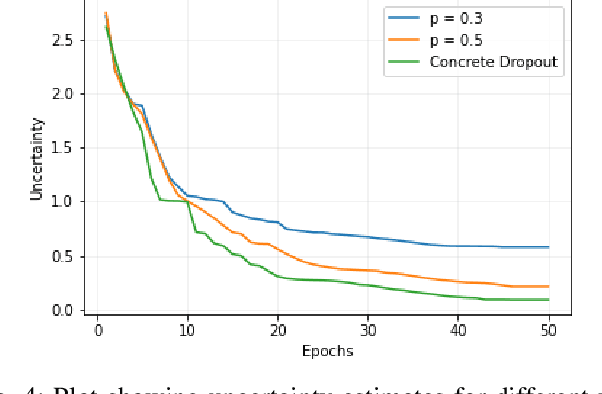
We present a Model Uncertainty-aware Differentiable ARchiTecture Search ($\mu$DARTS) that optimizes neural networks to simultaneously achieve high accuracy and low uncertainty. We introduce concrete dropout within DARTS cells and include a Monte-Carlo regularizer within the training loss to optimize the concrete dropout probabilities. A predictive variance term is introduced in the validation loss to enable searching for architecture with minimal model uncertainty. The experiments on CIFAR10, CIFAR100, SVHN, and ImageNet verify the effectiveness of $\mu$DARTS in improving accuracy and reducing uncertainty compared to existing DARTS methods. Moreover, the final architecture obtained from $\mu$DARTS shows higher robustness to noise at the input image and model parameters compared to the architecture obtained from existing DARTS methods.