 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCase-Base Neural Networks: survival analysis with time-varying, higher-order interactions
Jan 16, 2023Neural network-based survival methods can model data-driven covariate interactions. While these methods have led to better predictive performance than regression-based approaches, they cannot model both time-varying interactions and complex baseline hazards. To address this, we propose Case-Base Neural Networks (CBNN) as a new approach that combines the case-base sampling framework with flexible architectures. Our method naturally accounts for censoring and does not require method specific hyperparameters. Using a novel sampling scheme and data augmentation, we incorporate time directly into a feed-forward neural network. CBNN predicts the probability of an event occurring at a given moment and estimates the hazard function. We compare the performance of CBNN to survival methods based on regression and neural networks in two simulations and two real data applications. We report two time-dependent metrics for each model. In the simulations and real data applications, CBNN provides a more consistent predictive performance across time and outperforms the competing neural network approaches. For a simple simulation with an exponential hazard model, CBNN outperforms the other neural network methods. For a complex simulation, which highlights the ability of CBNN to model both a complex baseline hazard and time-varying interactions, CBNN outperforms all competitors. The first real data application shows CBNN outperforming all neural network competitors, while a second real data application shows competitive performance. We highlight the benefit of combining case-base sampling with deep learning to provide a simple and flexible modeling framework for data-driven, time-varying interaction modeling of survival outcomes. An R package is available at https://github.com/Jesse-Islam/cbnn.
Improving Convergence for Nonconvex Composite Programming
Oct 12, 2020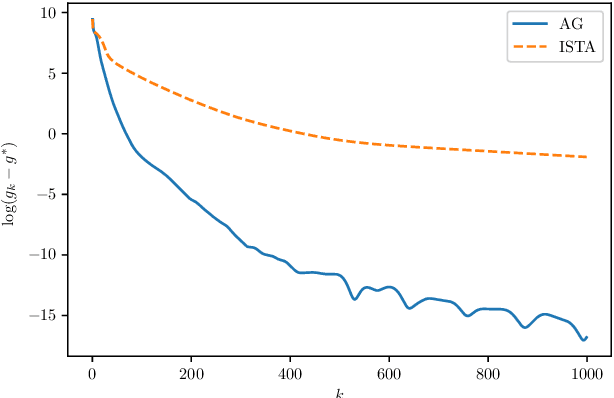
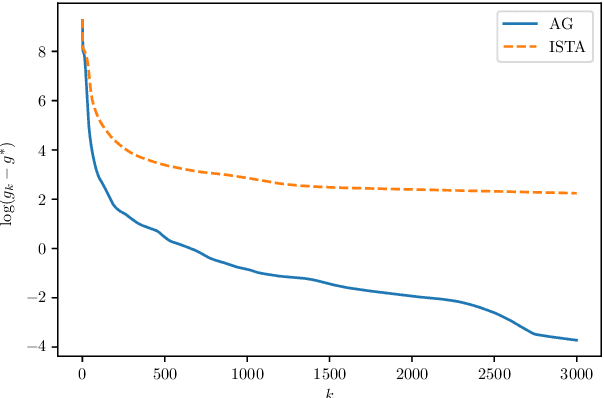
High-dimensional nonconvex problems are popular in today's machine learning and statistical genetics research. Recently, Ghadimi and Lan [1] proposed an algorithm to optimize nonconvex high-dimensional problems. There are several parameters in their algorithm that are to be set before running the algorithm. It is not trivial how to choose these parameters nor there is, to the best of our knowledge, an explicit rule on how to select the parameters to make the algorithm converges faster. We analyze Ghadimi and Lan's algorithm to gain an interpretation based on the inequality constraints for convergence and the upper bound for the norm of the gradient analogue. Our interpretation of their algorithm suggests this to be a damped Nesterov's acceleration scheme. Based on this, we propose an approach on how to select the parameters to improve convergence of the algorithm. Our numerical studies using high-dimensional nonconvex sparse learning problems, motivated by image denoising and statistical genetics applications, show that convergence can be made, on average, considerably faster than that of the conventional ISTA algorithm for such optimization problems with over $10000$ variables should the parameters be chosen using our proposed approach.