 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Stylization of Video Objects
Jun 27, 2022
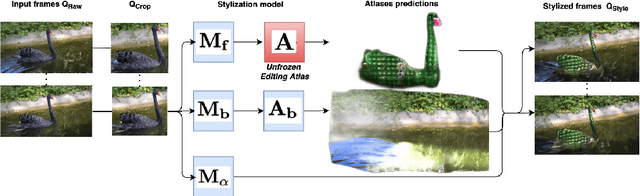
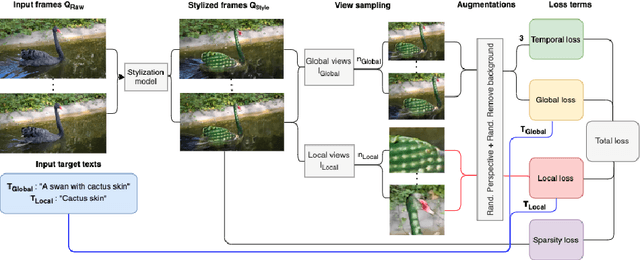

We tackle the task of stylizing video objects in an intuitive and semantic manner following a user-specified text prompt. This is a challenging task as the resulting video must satisfy multiple properties: (1) it has to be temporally consistent and avoid jittering or similar artifacts, (2) the resulting stylization must preserve both the global semantics of the object and its fine-grained details, and (3) it must adhere to the user-specified text prompt. To this end, our method stylizes an object in a video according to two target texts. The first target text prompt describes the global semantics and the second target text prompt describes the local semantics. To modify the style of an object, we harness the representational power of CLIP to get a similarity score between (1) the local target text and a set of local stylized views, and (2) a global target text and a set of stylized global views. We use a pretrained atlas decomposition network to propagate the edits in a temporally consistent manner. We demonstrate that our method can generate consistent style changes over time for a variety of objects and videos, that adhere to the specification of the target texts. We also show how varying the specificity of the target texts and augmenting the texts with a set of prefixes results in stylizations with different levels of detail. Full results are given on our project webpage: https://sloeschcke.github.io/Text-Driven-Stylization-of-Video-Objects/
Volumetric Disentanglement for 3D Scene Manipulation
Jun 06, 2022
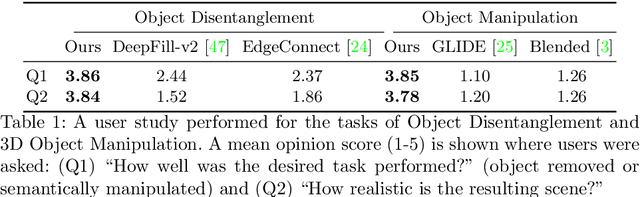
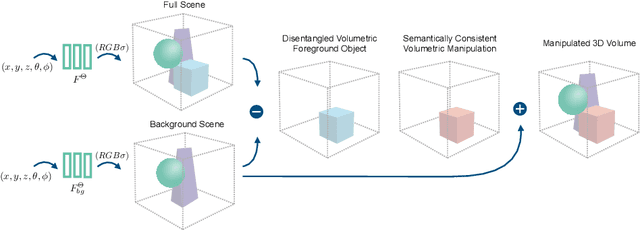
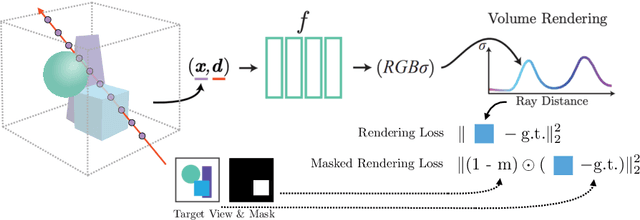
Recently, advances in differential volumetric rendering enabled significant breakthroughs in the photo-realistic and fine-detailed reconstruction of complex 3D scenes, which is key for many virtual reality applications. However, in the context of augmented reality, one may also wish to effect semantic manipulations or augmentations of objects within a scene. To this end, we propose a volumetric framework for (i) disentangling or separating, the volumetric representation of a given foreground object from the background, and (ii) semantically manipulating the foreground object, as well as the background. Our framework takes as input a set of 2D masks specifying the desired foreground object for training views, together with the associated 2D views and poses, and produces a foreground-background disentanglement that respects the surrounding illumination, reflections, and partial occlusions, which can be applied to both training and novel views. Our method enables the separate control of pixel color and depth as well as 3D similarity transformations of both the foreground and background objects. We subsequently demonstrate the applicability of our framework on a number of downstream manipulation tasks including object camouflage, non-negative 3D object inpainting, 3D object translation, 3D object inpainting, and 3D text-based object manipulation. Full results are given in our project webpage at https://sagiebenaim.github.io/volumetric-disentanglement/
On Disentangled and Locally Fair Representations
May 05, 2022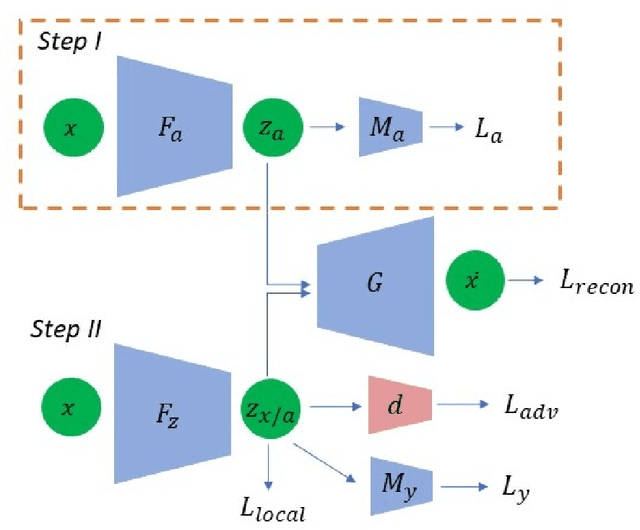
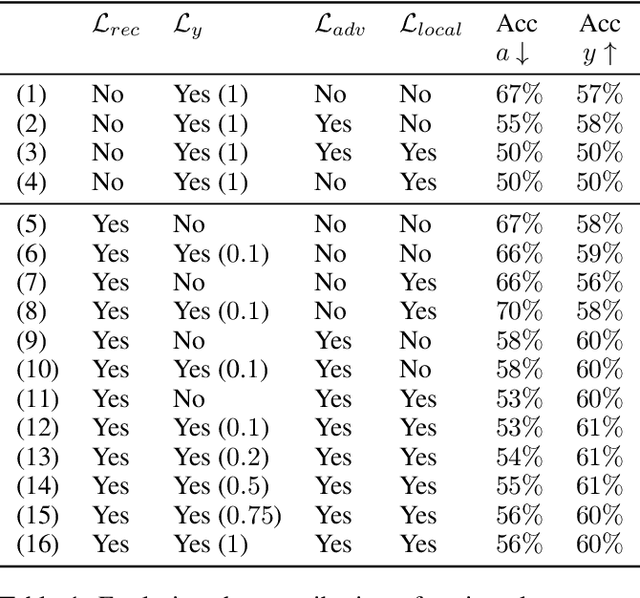
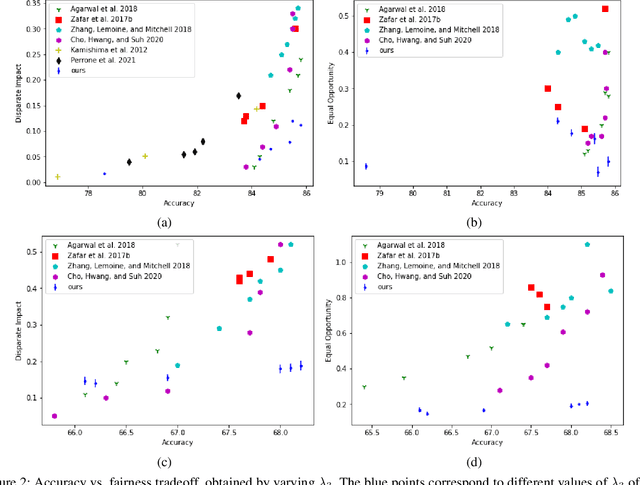
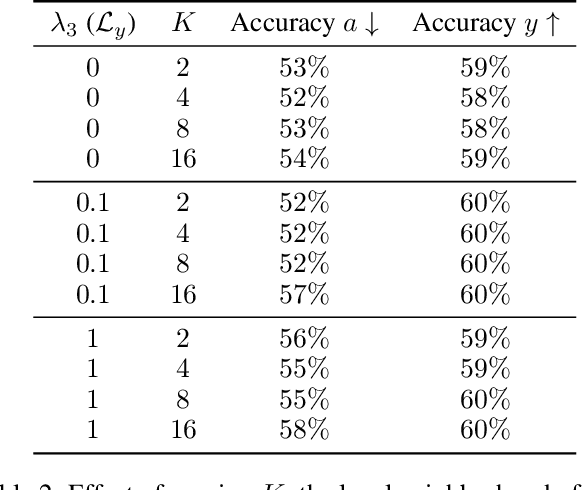
We study the problem of performing classification in a manner that is fair for sensitive groups, such as race and gender. This problem is tackled through the lens of disentangled and locally fair representations. We learn a locally fair representation, such that, under the learned representation, the neighborhood of each sample is balanced in terms of the sensitive attribute. For instance, when a decision is made to hire an individual, we ensure that the $K$ most similar hired individuals are racially balanced. Crucially, we ensure that similar individuals are found based on attributes not correlated to their race. To this end, we disentangle the embedding space into two representations. The first of which is correlated with the sensitive attribute while the second is not. We apply our local fairness objective only to the second, uncorrelated, representation. Through a set of experiments, we demonstrate the necessity of both disentangled and local fairness for obtaining fair and accurate representations. We evaluate our method on real-world settings such as predicting income and re-incarceration rate and demonstrate the advantage of our method.
Locally Shifted Attention With Early Global Integration
Dec 22, 2021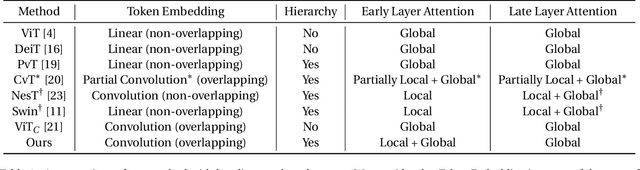

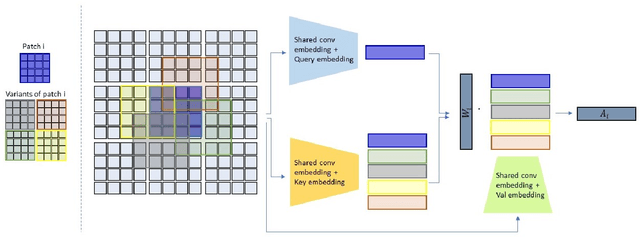
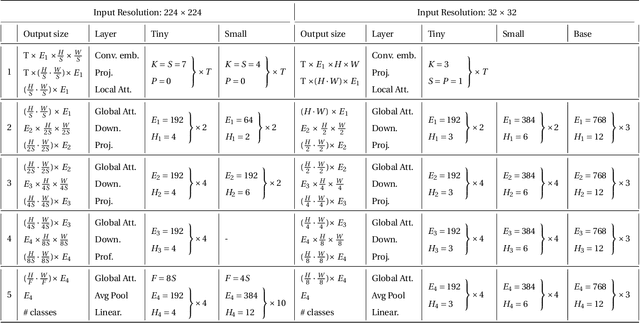
Recent work has shown the potential of transformers for computer vision applications. An image is first partitioned into patches, which are then used as input tokens for the attention mechanism. Due to the expensive quadratic cost of the attention mechanism, either a large patch size is used, resulting in coarse-grained global interactions, or alternatively, attention is applied only on a local region of the image, at the expense of long-range interactions. In this work, we propose an approach that allows for both coarse global interactions and fine-grained local interactions already at early layers of a vision transformer. At the core of our method is the application of local and global attention layers. In the local attention layer, we apply attention to each patch and its local shifts, resulting in virtually located local patches, which are not bound to a single, specific location. These virtually located patches are then used in a global attention layer. The separation of the attention layer into local and global counterparts allows for a low computational cost in the number of patches, while still supporting data-dependent localization already at the first layer, as opposed to the static positioning in other visual transformers. Our method is shown to be superior to both convolutional and transformer-based methods for image classification on CIFAR10, CIFAR100, and ImageNet. Code is available at: https://github.com/shellysheynin/Locally-SAG-Transformer.
Text2Mesh: Text-Driven Neural Stylization for Meshes
Dec 06, 2021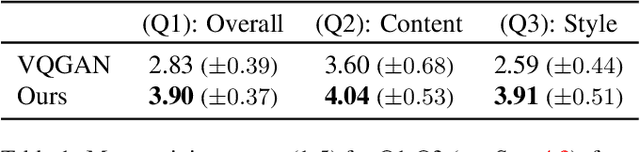


In this work, we develop intuitive controls for editing the style of 3D objects. Our framework, Text2Mesh, stylizes a 3D mesh by predicting color and local geometric details which conform to a target text prompt. We consider a disentangled representation of a 3D object using a fixed mesh input (content) coupled with a learned neural network, which we term neural style field network. In order to modify style, we obtain a similarity score between a text prompt (describing style) and a stylized mesh by harnessing the representational power of CLIP. Text2Mesh requires neither a pre-trained generative model nor a specialized 3D mesh dataset. It can handle low-quality meshes (non-manifold, boundaries, etc.) with arbitrary genus, and does not require UV parameterization. We demonstrate the ability of our technique to synthesize a myriad of styles over a wide variety of 3D meshes.
Image-Based CLIP-Guided Essence Transfer
Oct 26, 2021


The conceptual blending of two signals is a semantic task that may underline both creativity and intelligence. We propose to perform such blending in a way that incorporates two latent spaces: that of the generator network and that of the semantic network. For the first network, we employ the powerful StyleGAN generator, and for the second, the powerful image-language matching network of CLIP. The new method creates a blending operator that is optimized to be simultaneously additive in both latent spaces. Our results demonstrate that this leads to blending that is much more natural than what can be obtained in each space separately.
JOKR: Joint Keypoint Representation for Unsupervised Cross-Domain Motion Retargeting
Jun 17, 2021

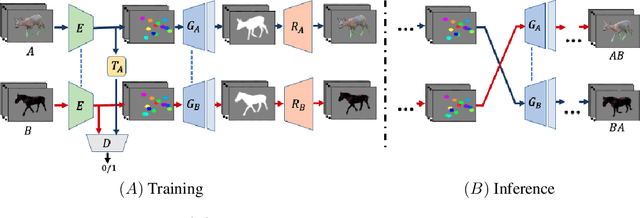
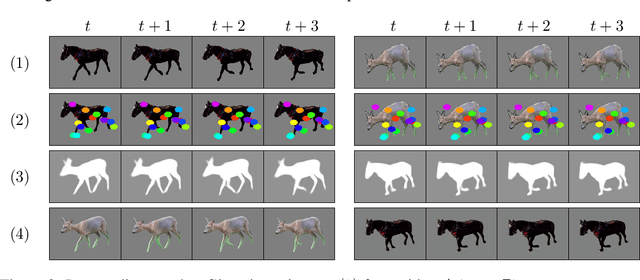
The task of unsupervised motion retargeting in videos has seen substantial advancements through the use of deep neural networks. While early works concentrated on specific object priors such as a human face or body, recent work considered the unsupervised case. When the source and target videos, however, are of different shapes, current methods fail. To alleviate this problem, we introduce JOKR - a JOint Keypoint Representation that captures the motion common to both the source and target videos, without requiring any object prior or data collection. By employing a domain confusion term, we enforce the unsupervised keypoint representations of both videos to be indistinguishable. This encourages disentanglement between the parts of the motion that are common to the two domains, and their distinctive appearance and motion, enabling the generation of videos that capture the motion of the one while depicting the style of the other. To enable cases where the objects are of different proportions or orientations, we apply a learned affine transformation between the JOKRs. This augments the representation to be affine invariant, and in practice broadens the variety of possible retargeting pairs. This geometry-driven representation enables further intuitive control, such as temporal coherence and manual editing. Through comprehensive experimentation, we demonstrate the applicability of our method to different challenging cross-domain video pairs. We evaluate our method both qualitatively and quantitatively, and demonstrate that our method handles various cross-domain scenarios, such as different animals, different flowers, and humans. We also demonstrate superior temporal coherency and visual quality compared to state-of-the-art alternatives, through statistical metrics and a user study. Source code and videos can be found at https://rmokady.github.io/JOKR/ .
Identity and Attribute Preserving Thumbnail Upscaling
May 30, 2021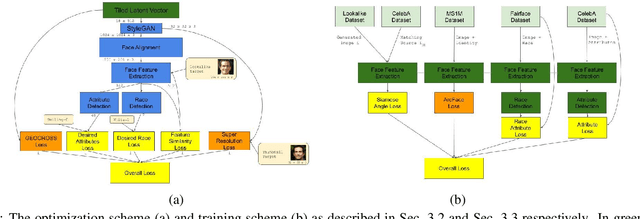
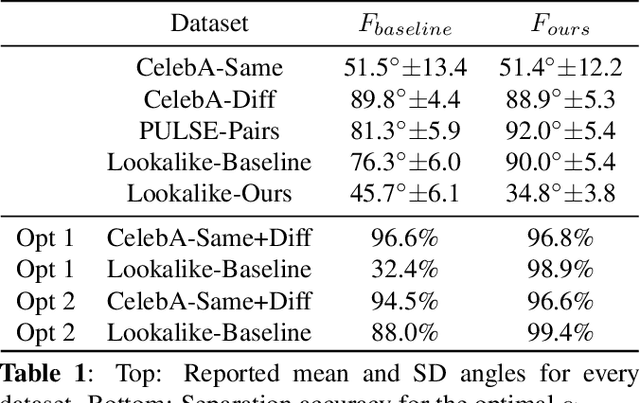


We consider the task of upscaling a low resolution thumbnail image of a person, to a higher resolution image, which preserves the person's identity and other attributes. Since the thumbnail image is of low resolution, many higher resolution versions exist. Previous approaches produce solutions where the person's identity is not preserved, or biased solutions, such as predominantly Caucasian faces. We address the existing ambiguity by first augmenting the feature extractor to better capture facial identity, facial attributes (such as smiling or not) and race, and second, use this feature extractor to generate high-resolution images which are identity preserving as well as conditioned on race and facial attributes. Our results indicate an improvement in face similarity recognition and lookalike generation as well as in the ability to generate higher resolution images which preserve an input thumbnail identity and whose race and attributes are maintained.
A Hierarchical Transformation-Discriminating Generative Model for Few Shot Anomaly Detection
Apr 29, 2021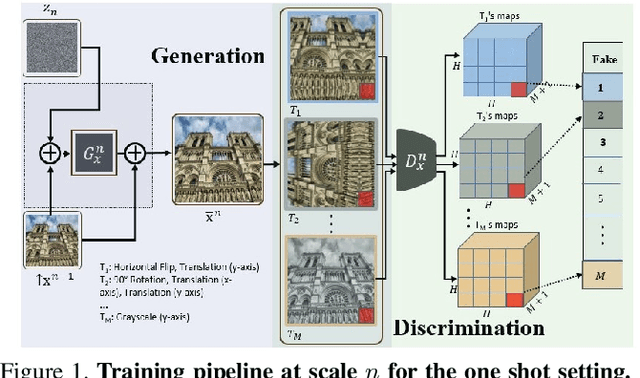
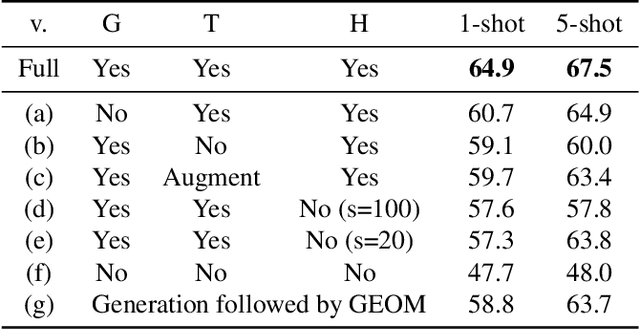
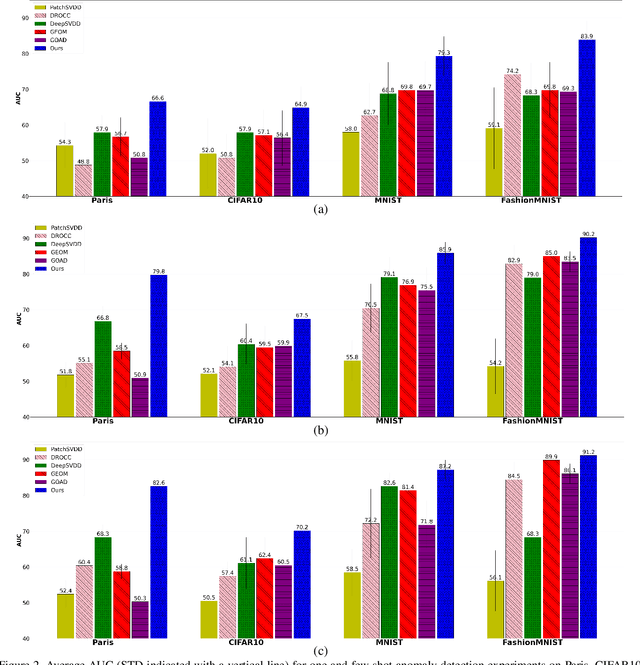

Anomaly detection, the task of identifying unusual samples in data, often relies on a large set of training samples. In this work, we consider the setting of few-shot anomaly detection in images, where only a few images are given at training. We devise a hierarchical generative model that captures the multi-scale patch distribution of each training image. We further enhance the representation of our model by using image transformations and optimize scale-specific patch-discriminators to distinguish between real and fake patches of the image, as well as between different transformations applied to those patches. The anomaly score is obtained by aggregating the patch-based votes of the correct transformation across scales and image regions. We demonstrate the superiority of our method on both the one-shot and few-shot settings, on the datasets of Paris, CIFAR10, MNIST and FashionMNIST as well as in the setting of defect detection on MVTec. In all cases, our method outperforms the recent baseline methods.
Permuted AdaIN: Enhancing the Representation of Local Cues in Image Classifiers
Oct 09, 2020
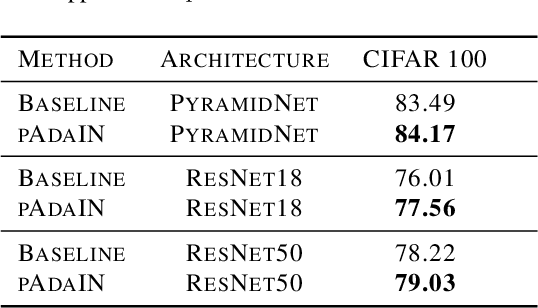
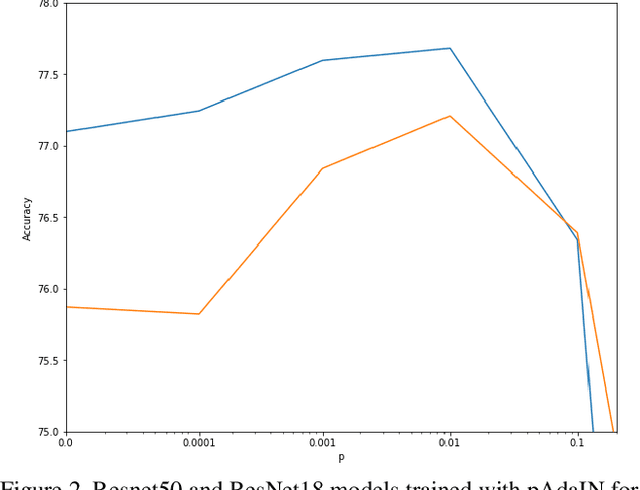
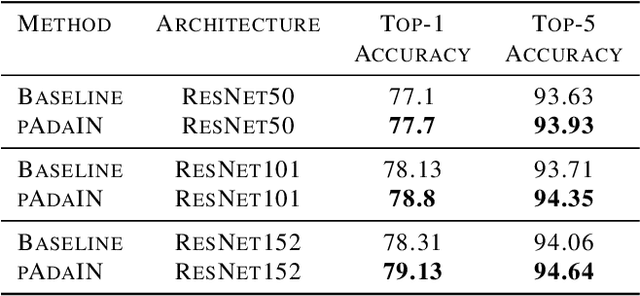
Recent work has shown that convolutional neural network classifiers overly rely on texture at the expense of shape cues, which adversely affects the classifier's performance in shifted domains. In this work, we make a similar but different distinction between local image cues, including shape and texture, and global image statistics. We provide a method that enhances the representation of local cues in the hidden layers of image classifiers. Our method, called Permuted Adaptive Instance Normalization (pAdaIN), samples a random permutation $\pi$ that rearranges the samples in a given batch. Adaptive Instance Normalization (AdaIN) is then applied between the activations of each (non-permuted) sample $i$ and the corresponding activations of the sample $\pi(i)$, thus swapping statistics between the samples of the batch. Since the global image statistics are distorted, this swapping procedure causes the network to rely on the local image cues. By choosing the random permutation with probability $p$ and the identity permutation otherwise, one can control the strength of this effect. With the correct choice of $p$, selected without considering the test data, our method consistently outperforms baseline methods in image classification, as well as in the setting of domain generalization.