 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Timbre-Painting and Articulation Generation
Sep 07, 2020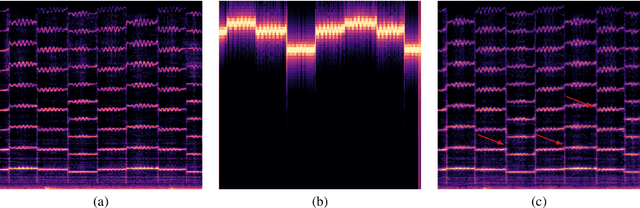
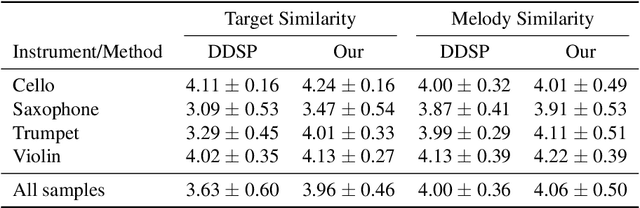
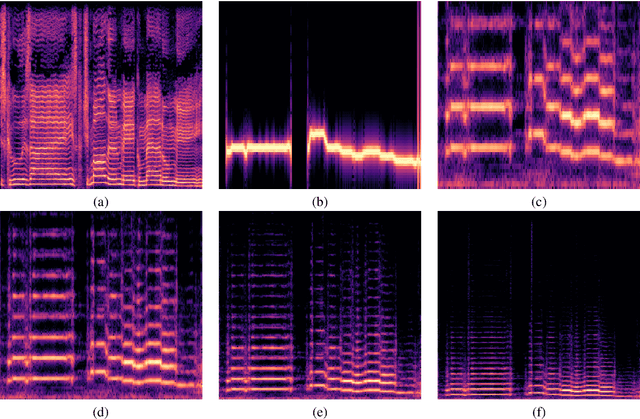
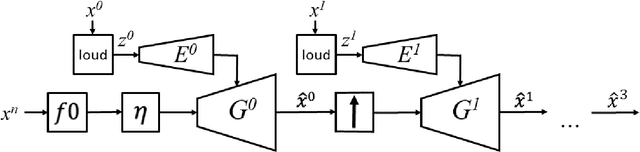
We present a fast and high-fidelity method for music generation, based on specified f0 and loudness, such that the synthesized audio mimics the timbre and articulation of a target instrument. The generation process consists of learned source-filtering networks, which reconstruct the signal at increasing resolutions. The model optimizes a multi-resolution spectral loss as the reconstruction loss, an adversarial loss to make the audio sound more realistic, and a perceptual f0 loss to align the output to the desired input pitch contour. The proposed architecture enables high-quality fitting of an instrument, given a sample that can be as short as a few minutes, and the method demonstrates state-of-the-art timbre transfer capabilities. Code and audio samples are shared at https://github.com/mosheman5/timbre_painting.
Audio Denoising with Deep Network Priors
Apr 16, 2019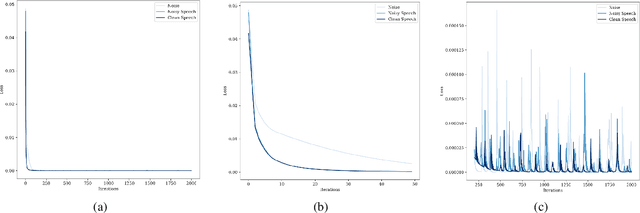
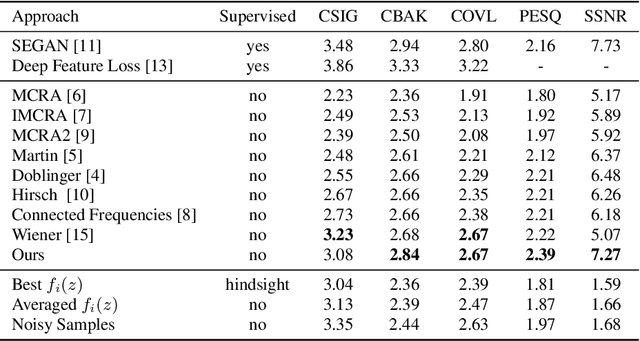
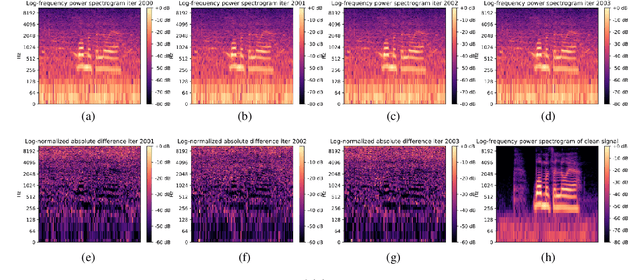

We present a method for audio denoising that combines processing done in both the time domain and the time-frequency domain. Given a noisy audio clip, the method trains a deep neural network to fit this signal. Since the fitting is only partly successful and is able to better capture the underlying clean signal than the noise, the output of the network helps to disentangle the clean audio from the rest of the signal. The method is completely unsupervised and only trains on the specific audio clip that is being denoised. Our experiments demonstrate favorable performance in comparison to the literature methods, and our code and audio samples are available at https: //github.com/mosheman5/DNP. Index Terms: Audio denoising; Unsupervised learning
Semi-Supervised Monaural Singing Voice Separation With a Masking Network Trained on Synthetic Mixtures
Dec 14, 2018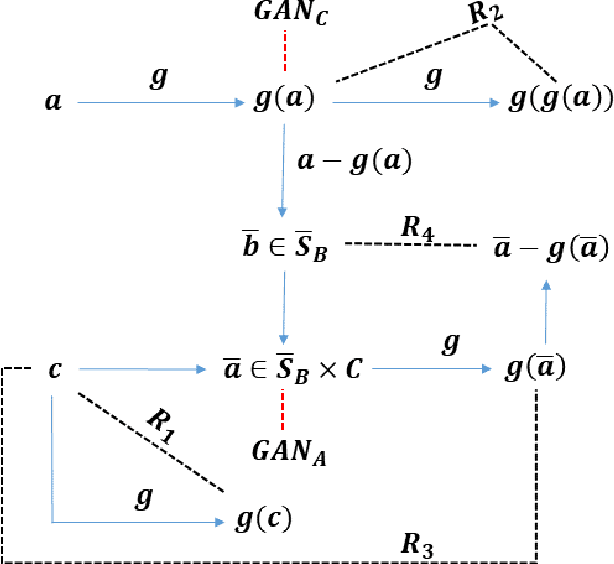

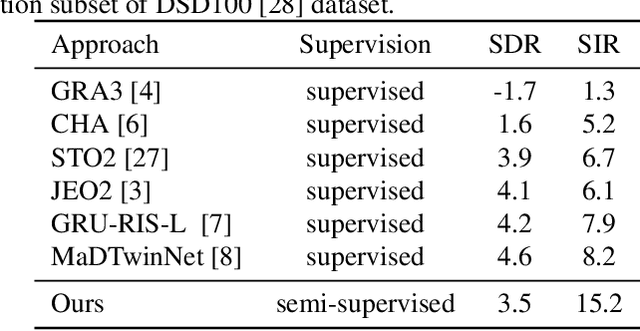
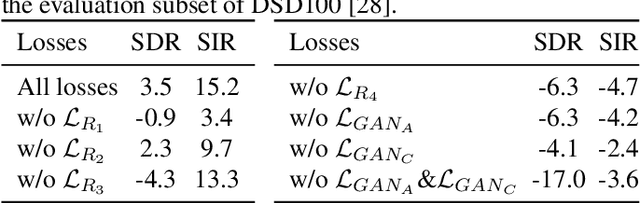
We study the problem of semi-supervised singing voice separation, in which the training data contains a set of samples of mixed music (singing and instrumental) and an unmatched set of instrumental music. Our solution employs a single mapping function g, which, applied to a mixed sample, recovers the underlying instrumental music, and, applied to an instrumental sample, returns the same sample. The network g is trained using purely instrumental samples, as well as on synthetic mixed samples that are created by mixing reconstructed singing voices with random instrumental samples. Our results indicate that we are on a par with or better than fully supervised methods, which are also provided with training samples of unmixed singing voices, and are better than other recent semi-supervised methods.