 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Bounds for Unsupervised Cross-Domain Mapping with WGANs
Paper and Code
Jul 26, 2018
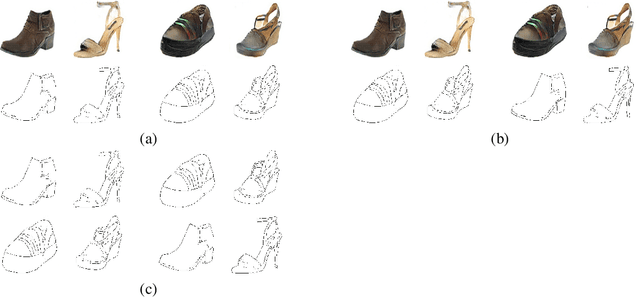

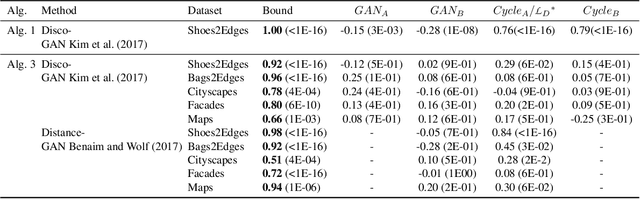
The recent empirical success of cross-domain mapping algorithms, between two domains that share common characteristics, is not well-supported by theoretical justifications. This lacuna is especially troubling, given the clear ambiguity in such mappings. We work with the adversarial training method called the Wasserstein GAN. We derive a novel generalization bound, which limits the risk between the learned mapping $h$ and the target mapping $y$, by a sum of two terms: (i) the risk between $h$ and the most distant alternative mapping that was learned by the same cross-domain mapping algorithm, and (ii) the minimal Wasserstein GAN divergence between the target domain and the domain obtained by applying a hypothesis $h^*$ on the samples of the source domain, where $h^*$ is a hypothesis selected by the same algorithm. The bound is directly related to Occam's razor and it encourages the selection of the minimal architecture that supports a small Wasserstein GAN divergence. From the bound, we derive algorithms for hyperparameter selection and early stopping in cross-domain mapping GANs. We also demonstrate a novel capability of estimating confidence in the mapping of every specific sample. Lastly, we show how non-minimal architectures can be effectively trained by an inverted knowledge distillation in which a minimal architecture is used to train a larger one, leading to higher quality outputs.