 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRe: Context-Robust Remasking for Diffusion Language Models
Feb 04, 2026Standard decoding in Masked Diffusion Models (MDMs) is hindered by context rigidity: tokens are retained based on transient high confidence, often ignoring that early predictions lack full context. This creates cascade effects where initial inconsistencies misguide the remaining generation. Existing revision strategies attempt to mitigate this by relying on static confidence scores, but these signals are inherently myopic; inconsistent tokens can appear confident to the model itself. We propose Context-Robust Remasking (CoRe), a training-free framework for inference-time revision. Rather than trusting static token probabilities, CoRe identifies context-brittle tokens by probing their sensitivity to targeted masked-context perturbations. We formalize revision as a robust optimization objective over context shifts and efficiently approximate this objective to prioritize unstable tokens for revision. On LLaDA-8B-Base, CoRe delivers consistent improvements across reasoning and code benchmarks, outperforming compute-matched baselines and improving MBPP by up to 9.2 percentage points.
The Telephone Game: Evaluating Semantic Drift in Unified Models
Sep 04, 2025Employing a single, unified model (UM) for both visual understanding (image-to-text: I2T) and and visual generation (text-to-image: T2I) has opened a new direction in Visual Language Model (VLM) research. While UMs can also support broader unimodal tasks (e.g., text-to-text, image-to-image), we focus on the core cross-modal pair T2I and I2T, as consistency between understanding and generation is critical for downstream use. Existing evaluations consider these capabilities in isolation: FID and GenEval for T2I, and benchmarks such as MME, MMBench for I2T. These single-pass metrics do not reveal whether a model that understands a concept can also render it, nor whether meaning is preserved when cycling between image and text modalities. To address this, we introduce the Unified Consistency Framework for Unified Models (UCF-UM), a cyclic evaluation protocol that alternates I2T and T2I over multiple generations to quantify semantic drift. UCF formulates 3 metrics: (i) Mean Cumulative Drift (MCD), an embedding-based measure of overall semantic loss; (ii) Semantic Drift Rate (SDR), that summarizes semantic decay rate; and (iii) Multi-Generation GenEval (MGG), an object-level compliance score extending GenEval. To assess generalization beyond COCO, which is widely used in training; we create a new benchmark ND400, sampled from NoCaps and DOCCI and evaluate on seven recent models. UCF-UM reveals substantial variation in cross-modal stability: some models like BAGEL maintain semantics over many alternations, whereas others like Vila-u drift quickly despite strong single-pass scores. Our results highlight cyclic consistency as a necessary complement to standard I2T and T2I evaluations, and provide practical metrics to consistently assess unified model's cross-modal stability and strength of their shared representations. Code: https://github.com/mollahsabbir/Semantic-Drift-in-Unified-Models
LILA-BOTI : Leveraging Isolated Letter Accumulations By Ordering Teacher Insights for Bangla Handwriting Recognition
May 23, 2022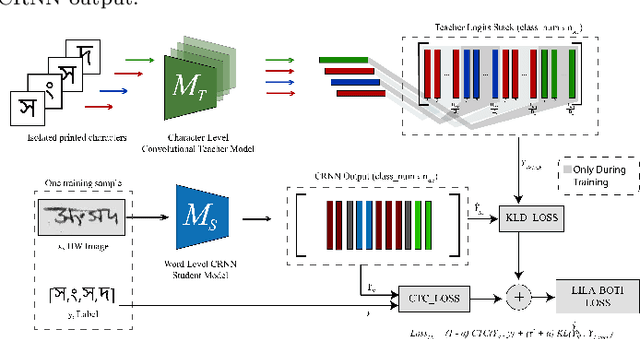
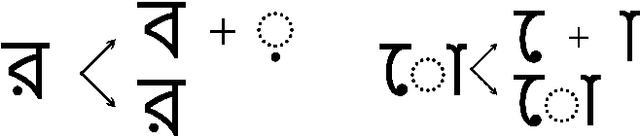
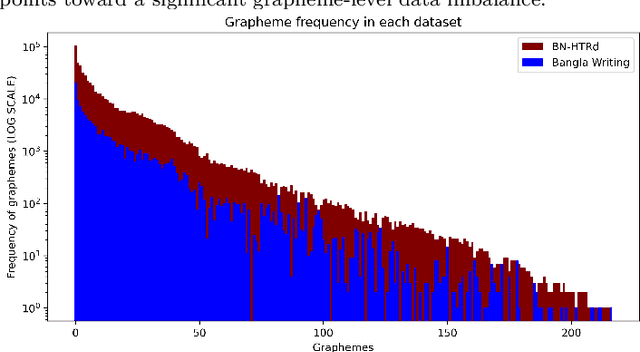
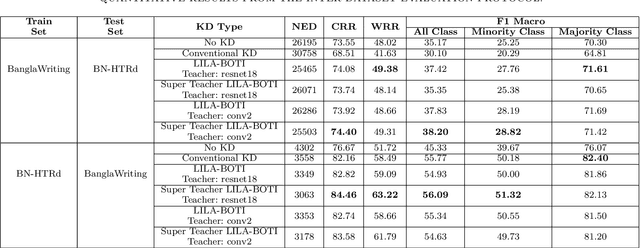
Word-level handwritten optical character recognition (OCR) remains a challenge for morphologically rich languages like Bangla. The complexity arises from the existence of a large number of alphabets, the presence of several diacritic forms, and the appearance of complex conjuncts. The difficulty is exacerbated by the fact that some graphemes occur infrequently but remain indispensable, so addressing the class imbalance is required for satisfactory results. This paper addresses this issue by introducing two knowledge distillation methods: Leveraging Isolated Letter Accumulations By Ordering Teacher Insights (LILA-BOTI) and Super Teacher LILA-BOTI. In both cases, a Convolutional Recurrent Neural Network (CRNN) student model is trained with the dark knowledge gained from a printed isolated character recognition teacher model. We conducted inter-dataset testing on \emph{BN-HTRd} and \emph{BanglaWriting} as our evaluation protocol, thus setting up a challenging problem where the results would better reflect the performance on unseen data. Our evaluations achieved up to a 3.5% increase in the F1-Macro score for the minor classes and up to 4.5% increase in our overall word recognition rate when compared with the base model (No KD) and conventional KD.