 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformation Driven Seq2Seq Longitudinal Tumor and Organs-at-Risk Prediction for Radiotherapy
Jun 18, 2021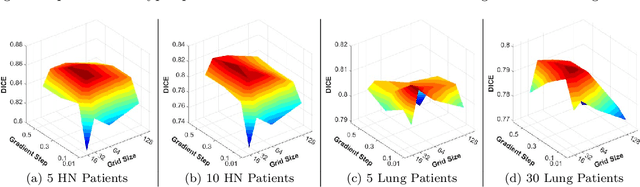
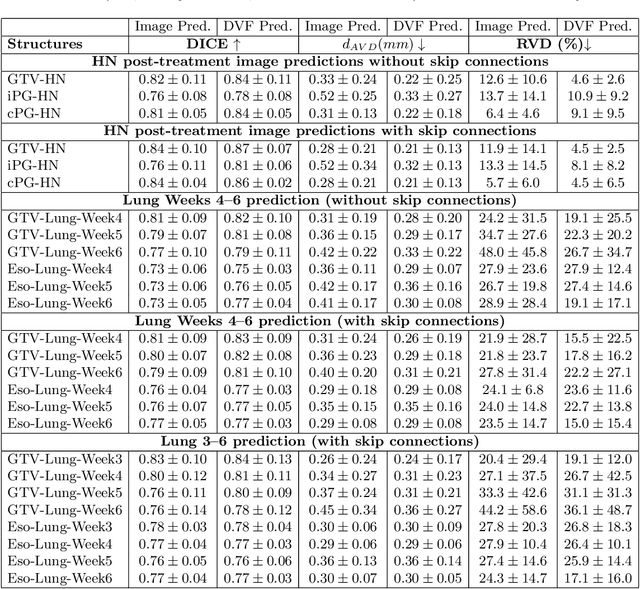
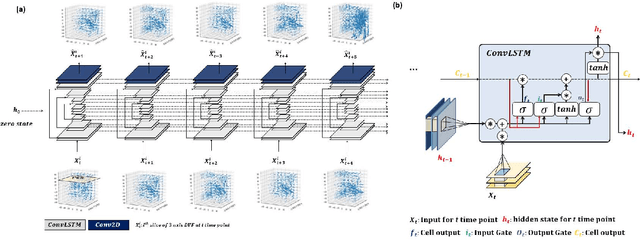
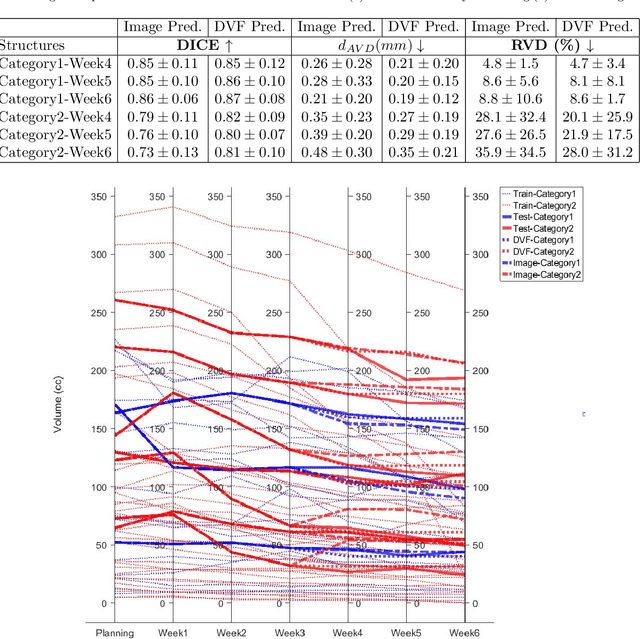
Purpose: Radiotherapy presents unique challenges and clinical requirements for longitudinal tumor and organ-at-risk (OAR) prediction during treatment. The challenges include tumor inflammation/edema and radiation-induced changes in organ geometry, whereas the clinical requirements demand flexibility in input/output sequence timepoints to update the predictions on rolling basis and the grounding of all predictions in relationship to the pre-treatment imaging information for response and toxicity assessment in adaptive radiotherapy. Methods: To deal with the aforementioned challenges and to comply with the clinical requirements, we present a novel 3D sequence-to-sequence model based on Convolution Long Short Term Memory (ConvLSTM) that makes use of series of deformation vector fields (DVF) between individual timepoints and reference pre-treatment/planning CTs to predict future anatomical deformations and changes in gross tumor volume as well as critical OARs. High-quality DVF training data is created by employing hyper-parameter optimization on the subset of the training data with DICE coefficient and mutual information metric. We validated our model on two radiotherapy datasets: a publicly available head-and-neck dataset (28 patients with manually contoured pre-, mid-, and post-treatment CTs), and an internal non-small cell lung cancer dataset (63 patients with manually contoured planning CT and 6 weekly CBCTs). Results: The use of DVF representation and skip connections overcomes the blurring issue of ConvLSTM prediction with the traditional image representation. The mean and standard deviation of DICE for predictions of lung GTV at week 4, 5, and 6 were 0.83$\pm$0.09, 0.82$\pm$0.08, and 0.81$\pm$0.10, respectively, and for post-treatment ipsilateral and contralateral parotids, were 0.81$\pm$0.06 and 0.85$\pm$0.02.
Deep Learning 3D Dose Prediction for Conventional Lung IMRT Using Consistent/Unbiased Automated Plans
Jun 07, 2021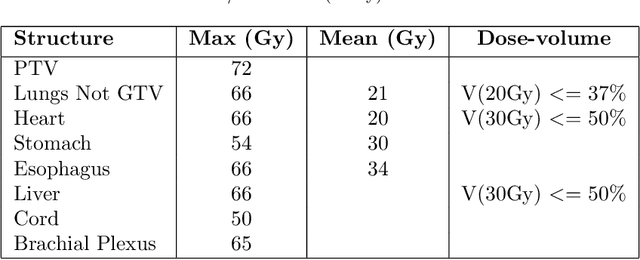
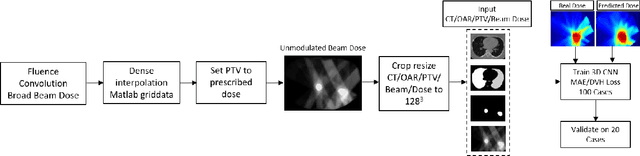
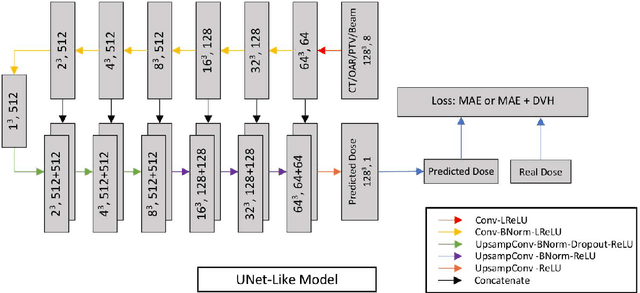

Deep learning (DL) 3D dose prediction has recently gained a lot of attention. However, the variability of plan quality in the training dataset, generated manually by planners with wide range of expertise, can dramatically effect the quality of the final predictions. Moreover, any changes in the clinical criteria requires a new set of manually generated plans by planners to build a new prediction model. In this work, we instead use consistent plans generated by our in-house automated planning system (named ``ECHO'') to train the DL model. ECHO (expedited constrained hierarchical optimization) generates consistent/unbiased plans by solving large-scale constrained optimization problems sequentially. If the clinical criteria changes, a new training data set can be easily generated offline using ECHO, with no or limited human intervention, making the DL-based prediction model easily adaptable to the changes in the clinical practice. We used 120 conventional lung patients (100 for training, 20 for testing) with different beam configurations and trained our DL-model using manually-generated as well as automated ECHO plans. We evaluated different inputs: (1) CT+(PTV/OAR)contours, and (2) CT+contours+beam configurations, and different loss functions: (1) MAE (mean absolute error), and (2) MAE+DVH (dose volume histograms). The quality of the predictions was compared using different DVH metrics as well as dose-score and DVH-score, recently introduced by the AAPM knowledge-based planning grand challenge. The best results were obtained using automated ECHO plans and CT+contours+beam as training inputs and MAE+DVH as loss function.
Multitask 3D CBCT-to-CT Translation and Organs-at-Risk Segmentation Using Physics-Based Data Augmentation
Mar 09, 2021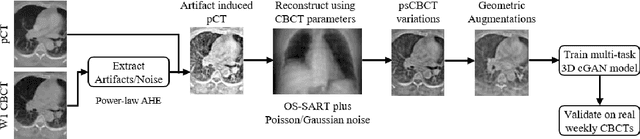
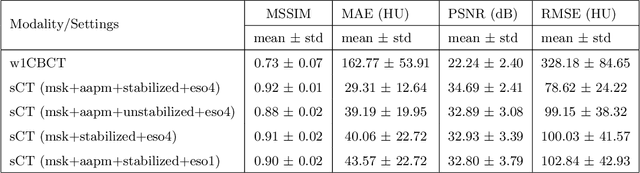
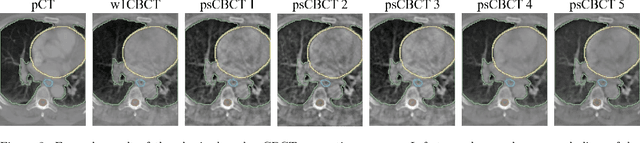
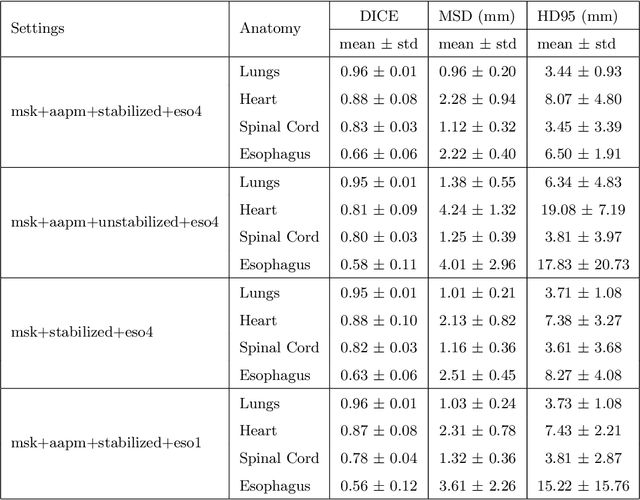
Purpose: In current clinical practice, noisy and artifact-ridden weekly cone-beam computed tomography (CBCT) images are only used for patient setup during radiotherapy. Treatment planning is done once at the beginning of the treatment using high-quality planning CT (pCT) images and manual contours for organs-at-risk (OARs) structures. If the quality of the weekly CBCT images can be improved while simultaneously segmenting OAR structures, this can provide critical information for adapting radiotherapy mid-treatment as well as for deriving biomarkers for treatment response. Methods: Using a novel physics-based data augmentation strategy, we synthesize a large dataset of perfectly/inherently registered planning CT and synthetic-CBCT pairs for locally advanced lung cancer patient cohort, which are then used in a multitask 3D deep learning framework to simultaneously segment and translate real weekly CBCT images to high-quality planning CT-like images. Results: We compared the synthetic CT and OAR segmentations generated by the model to real planning CT and manual OAR segmentations and showed promising results. The real week 1 (baseline) CBCT images which had an average MAE of 162.77 HU compared to pCT images are translated to synthetic CT images that exhibit a drastically improved average MAE of 29.31 HU and average structural similarity of 92% with the pCT images. The average DICE scores of the 3D organs-at-risk segmentations are: lungs 0.96, heart 0.88, spinal cord 0.83 and esophagus 0.66. Conclusions: We demonstrate an approach to translate artifact-ridden CBCT images to high quality synthetic CT images while simultaneously generating good quality segmentation masks for different organs-at-risk. This approach could allow clinicians to adjust treatment plans using only the routine low-quality CBCT images, potentially improving patient outcomes.
Visualizing Missing Surfaces In Colonoscopy Videos using Shared Latent Space Representations
Jan 18, 2021
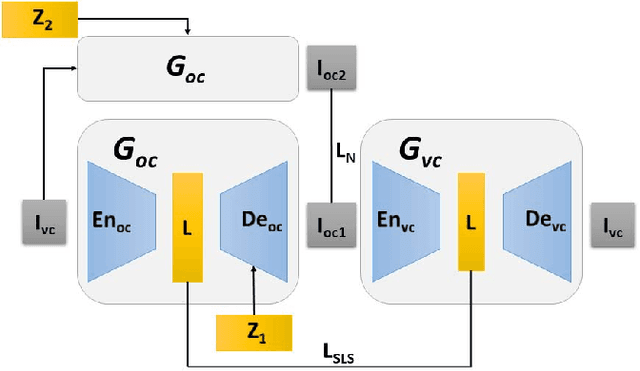
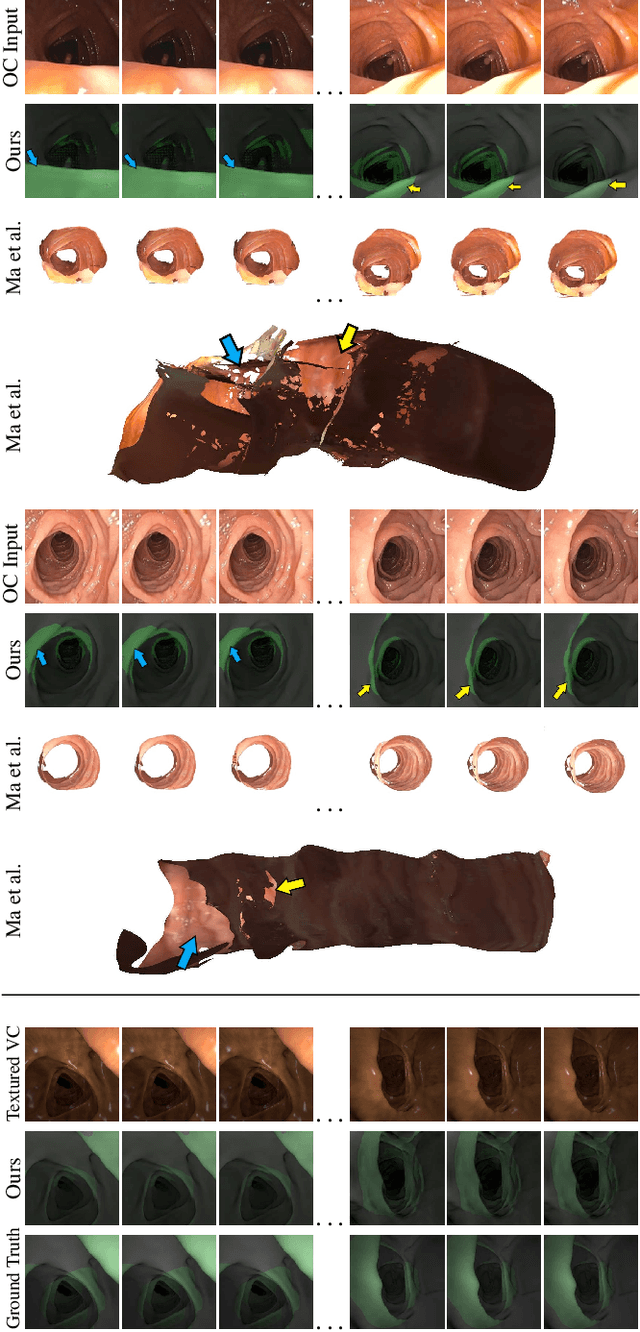
Optical colonoscopy (OC), the most prevalent colon cancer screening tool, has a high miss rate due to a number of factors, including the geometry of the colon (haustral fold and sharp bends occlusions), endoscopist inexperience or fatigue, endoscope field of view, etc. We present a framework to visualize the missed regions per-frame during the colonoscopy, and provides a workable clinical solution. Specifically, we make use of 3D reconstructed virtual colonoscopy (VC) data and the insight that VC and OC share the same underlying geometry but differ in color, texture and specular reflections, embedded in the OC domain. A lossy unpaired image-to-image translation model is introduced with enforced shared latent space for OC and VC. This shared latent space captures the geometric information while deferring the color, texture, and specular information creation to additional Gaussian noise input. This additional noise input can be utilized to generate one-to-many mappings from VC to OC and OC to OC.
Generalizable Cone Beam CT Esophagus Segmentation Using In Silico Data Augmentation
Jun 28, 2020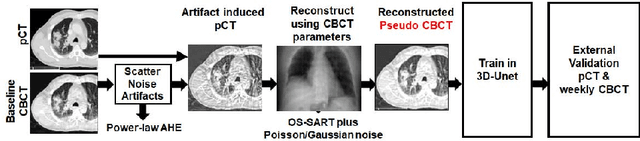
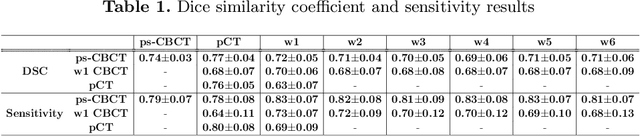
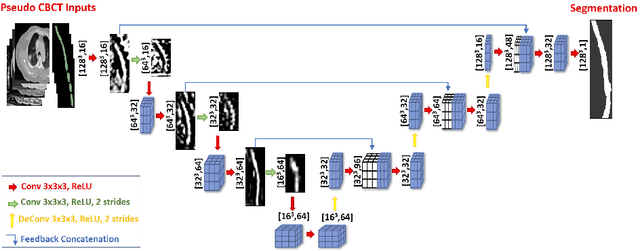

Lung cancer radiotherapy entails high quality planning computed tomography (pCT) imaging of the patient with radiation oncologist contouring of the tumor and the organs at risk (OARs) at the start of the treatment. This is followed by weekly low-quality cone beam CT (CBCT) imaging for treatment setup and qualitative visual assessment of tumor and critical OARs. In this work, we aim to make the weekly CBCT assessment quantitative by automatically segmenting the most critical OAR, esophagus, using deep learning and in silico (image-driven simulation) artifact induction to convert pCTs to pseudo-CBCTs (pCTs$+$artifacts). Specifically, for the in silico data augmentation, we make use of the critical insight that CT and CBCT have the same underlying physics and that it is easier to deteriorate the pCT to look more like CBCT (and use the accompanying high quality manual contours for segmentation) than to synthesize CT from CBCT where the critical anatomical information may have already been lost (which leads to anatomical hallucination with the prevalent generative adversarial networks for example). Given these pseudo-CBCTs and the high quality manual contours, we introduce a modified 3D-Unet architecture and a multi-objective loss function specifically designed for segmenting soft-tissue organs such as esophagus on real weekly CBCTs. The model achieved 0.74 dice overlap (against manual contours of an experienced radiation oncologist) on weekly CBCTs and was robust and generalizable enough to also produce state-of-the-art results on pCTs, achieving 0.77 dice overlap against the previous best of 0.72. This shows that our in silico data augmentation spans the realistic noise/artifact spectrum across patient CBCT/pCT data and can generalize well across modalities (without requiring retraining or domain adaptation), eventually improving the accuracy of treatment setup and response analysis.
Multimarginal Wasserstein Barycenter for Stain Normalization and Augmentation
Jun 25, 2020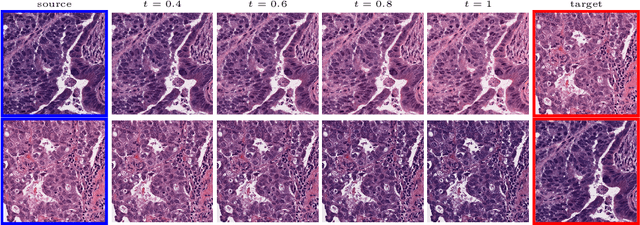
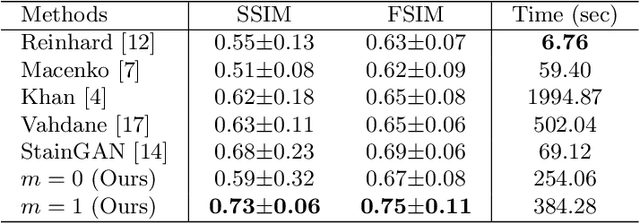
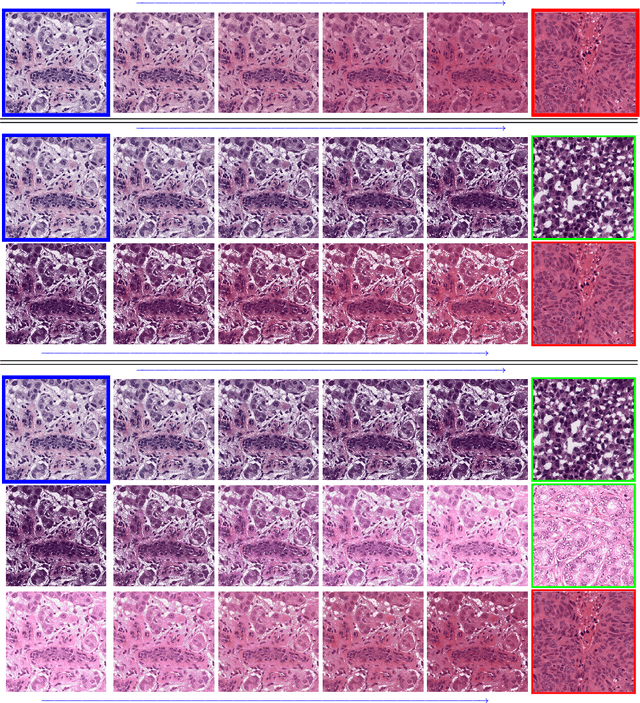
Variations in hematoxylin and eosin (H&E) stained images (due to clinical lab protocols, scanners, etc) directly impact the quality and accuracy of clinical diagnosis, and hence it is important to control for these variations for a reliable diagnosis. In this work, we present a new approach based on the multimarginal Wasserstein barycenter to normalize and augment H&E stained images given one or more references. Specifically, we provide a mathematically robust way of naturally incorporating additional images as intermediate references to drive stain normalization and augmentation simultaneously. The presented approach showed superior results quantitatively and qualitatively as compared to state-of-the-art methods for stain normalization. We further validated our stain normalization and augmentations in the nuclei segmentation task on a publicly available dataset, achieving state-of-the-art results against competing approaches.
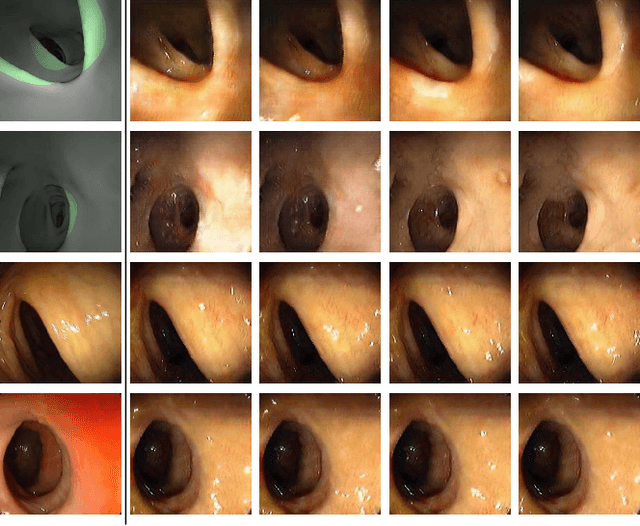
Augmenting Colonoscopy using Extended and Directional CycleGAN for Lossy Image Translation
Mar 27, 2020
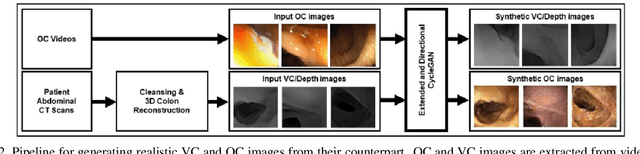
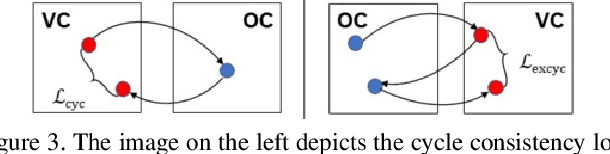
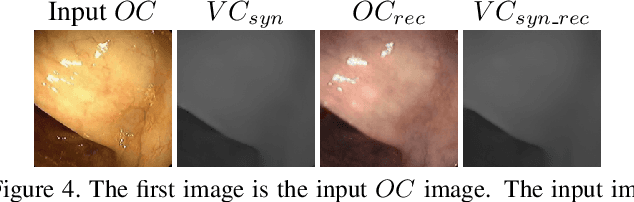
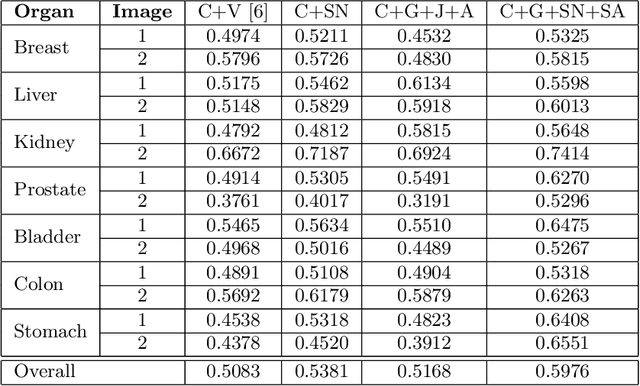
Colorectal cancer screening modalities, such as optical colonoscopy (OC) and virtual colonoscopy (VC), are critical for diagnosing and ultimately removing polyps (precursors of colon cancer). The non-invasive VC is normally used to inspect a 3D reconstructed colon (from CT scans) for polyps and if found, the OC procedure is performed to physically traverse the colon via endoscope and remove these polyps. In this paper, we present a deep learning framework, Extended and Directional CycleGAN, for lossy unpaired image-to-image translation between OC and VC to augment OC video sequences with scale-consistent depth information from VC, and augment VC with patient-specific textures, color and specular highlights from OC (e.g, for realistic polyp synthesis). Both OC and VC contain structural information, but it is obscured in OC by additional patient-specific texture and specular highlights, hence making the translation from OC to VC lossy. The existing CycleGAN approaches do not handle lossy transformations. To address this shortcoming, we introduce an extended cycle consistency loss, which compares the geometric structures from OC in the VC domain. This loss removes the need for the CycleGAN to embed OC information in the VC domain. To handle a stronger removal of the textures and lighting, a Directional Discriminator is introduced to differentiate the direction of translation (by creating paired information for the discriminator), as opposed to the standard CycleGAN which is direction-agnostic. Combining the extended cycle consistency loss and the Directional Discriminator, we show state-of-the-art results on scale-consistent depth inference for phantom, textured VC and for real polyp and normal colon video sequences. We also present results for realistic pendunculated and flat polyp synthesis from bumps introduced in 3D VC models.
LMap: Shape-Preserving Local Mappings for Biomedical Visualization
Oct 25, 2018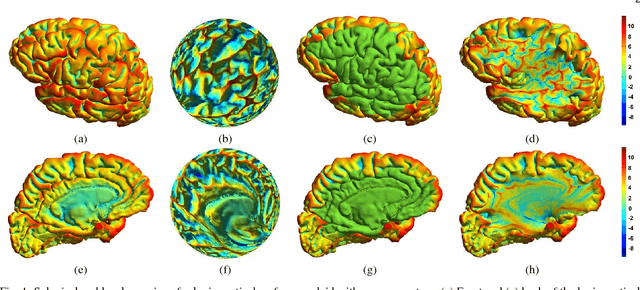
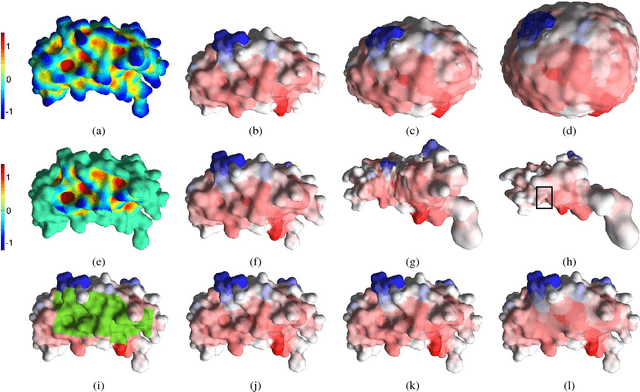
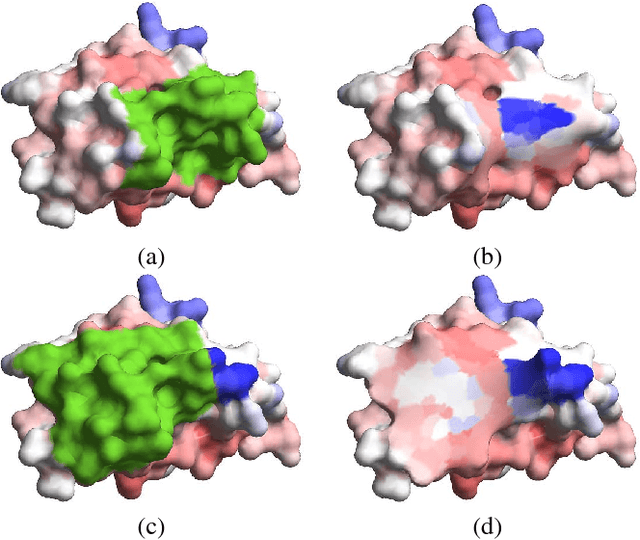

Visualization of medical organs and biological structures is a challenging task because of their complex geometry and the resultant occlusions. Global spherical and planar mapping techniques simplify the complex geometry and resolve the occlusions to aid in visualization. However, while resolving the occlusions these techniques do not preserve the geometric context, making them less suitable for mission-critical biomedical visualization tasks. In this paper, we present a shape-preserving local mapping technique for resolving occlusions locally while preserving the overall geometric context. More specifically, we present a novel visualization algorithm, LMap, for conformally parameterizing and deforming a selected local region-of-interest (ROI) on an arbitrary surface. The resultant shape-preserving local mappings help to visualize complex surfaces while preserving the overall geometric context. The algorithm is based on the robust and efficient extrinsic Ricci flow technique, and uses the dynamic Ricci flow algorithm to guarantee the existence of a local map for a selected ROI on an arbitrary surface. We show the effectiveness and efficacy of our method in three challenging use cases: (1) multimodal brain visualization, (2) optimal coverage of virtual colonoscopy centerline flythrough, and (3) molecular surface visualization.
* IEEE Transactions on Visualization and Computer Graphics, 24(12): 3111-3122, 2018 (12 pages, 11 figures)
C2A: Crowd Consensus Analytics for Virtual Colonoscopy
Oct 21, 2018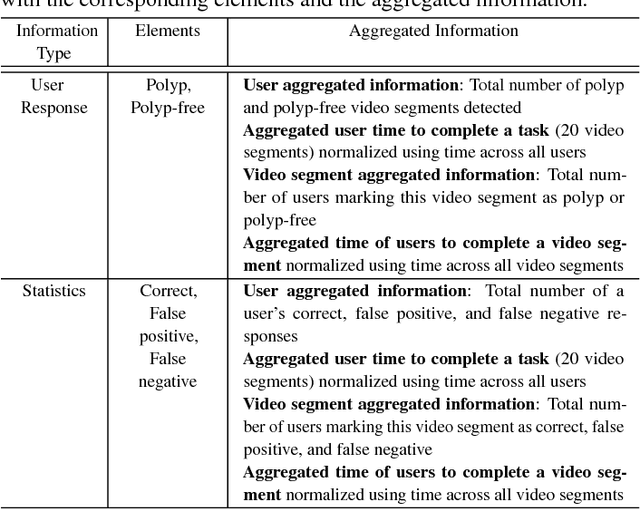
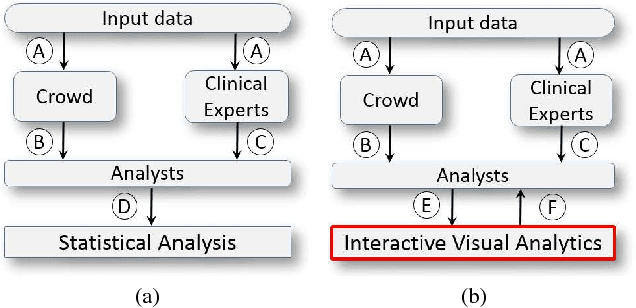
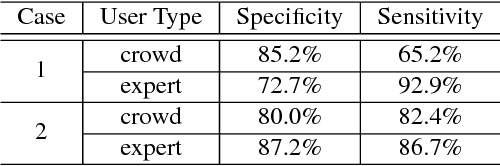
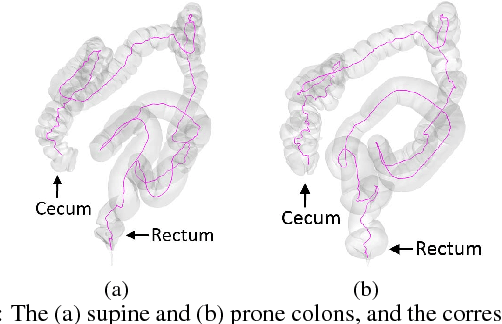
We present a medical crowdsourcing visual analytics platform called C{$^2$}A to visualize, classify and filter crowdsourced clinical data. More specifically, C$^2$A is used to build consensus on a clinical diagnosis by visualizing crowd responses and filtering out anomalous activity. Crowdsourcing medical applications have recently shown promise where the non-expert users (the crowd) were able to achieve accuracy similar to the medical experts. This has the potential to reduce interpretation/reading time and possibly improve accuracy by building a consensus on the findings beforehand and letting the medical experts make the final diagnosis. In this paper, we focus on a virtual colonoscopy (VC) application with the clinical technicians as our target users, and the radiologists acting as consultants and classifying segments as benign or malignant. In particular, C$^2$A is used to analyze and explore crowd responses on video segments, created from fly-throughs in the virtual colon. C$^2$A provides several interactive visualization components to build crowd consensus on video segments, to detect anomalies in the crowd data and in the VC video segments, and finally, to improve the non-expert user's work quality and performance by A/B testing for the optimal crowdsourcing platform and application-specific parameters. Case studies and domain experts feedback demonstrate the effectiveness of our framework in improving workers' output quality, the potential to reduce the radiologists' interpretation time, and hence, the potential to improve the traditional clinical workflow by marking the majority of the video segments as benign based on the crowd consensus.
* IEEE Conference on Visual Analytics Science and Technology (VAST), pp. 21-30, 2016 (10 pages, 11 figures)
Visualization Framework for Colonoscopy Videos
Oct 21, 2018We present a visualization framework for annotating and comparing colonoscopy videos, where these annotations can then be used for semi-automatic report generation at the end of the procedure. Currently, there are approximately 14 million colonoscopies performed every year in the US. In this work, we create a visualization tool to deal with the deluge of colonoscopy videos in a more effective way. We present an interactive visualization framework for the annotation and tagging of colonoscopy videos in an easy and intuitive way. These annotations and tags can later be used for report generation for electronic medical records and for comparison at an individual as well as group level. We also present important use cases and medical expert feedback for our visualization framework.
* SPIE Medical Imaging, 2016 (7 pages, 5 figures)