 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me Why You Feel That Way: Processing Compositional Dependency for Tree-LSTM Aspect Sentiment Triplet Extraction
Mar 10, 2021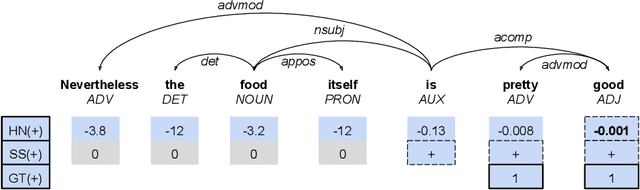
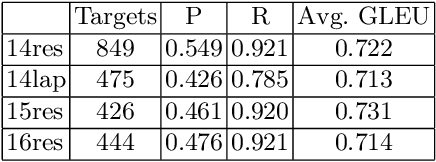
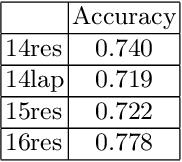
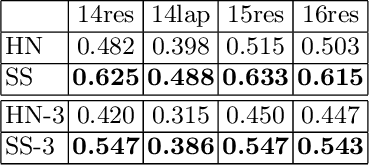
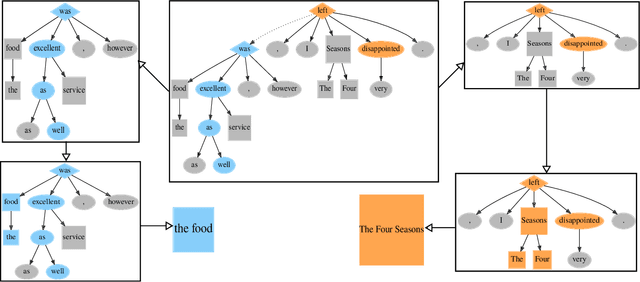
Sentiment analysis has transitioned from classifying the sentiment of an entire sentence to providing the contextual information of what targets exist in a sentence, what sentiment the individual targets have, and what the causal words responsible for that sentiment are. However, this has led to elaborate requirements being placed on the datasets needed to train neural networks on the joint triplet task of determining an entity, its sentiment, and the causal words for that sentiment. Requiring this kind of data for training systems is problematic, as they suffer from stacking subjective annotations and domain over-fitting leading to poor model generalisation when applied in new contexts. These problems are also likely to be compounded as we attempt to jointly determine additional contextual elements in the future. To mitigate these problems, we present a hybrid neural-symbolic method utilising a Dependency Tree-LSTM's compositional sentiment parse structure and complementary symbolic rules to correctly extract target-sentiment-cause triplets from sentences without the need for triplet training data. We show that this method has the potential to perform in line with state-of-the-art approaches while also simplifying the data required and providing a degree of interpretability through the Tree-LSTM.
Leveraging Recursive Processing for Neural-Symbolic Affect-Target Associations
Mar 05, 2021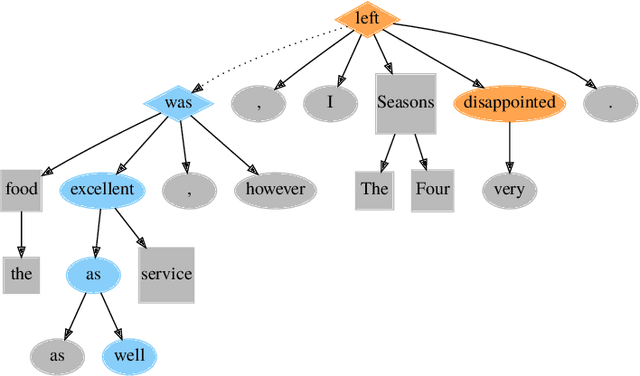
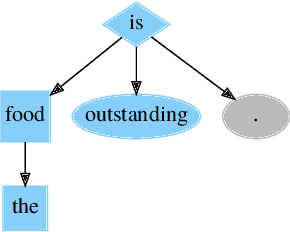
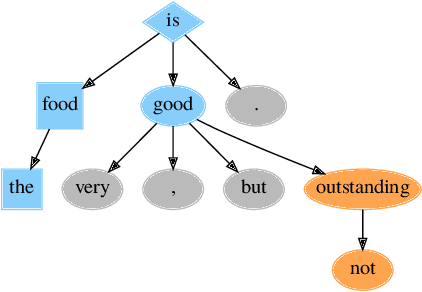
Explaining the outcome of deep learning decisions based on affect is challenging but necessary if we expect social companion robots to interact with users on an emotional level. In this paper, we present a commonsense approach that utilizes an interpretable hybrid neural-symbolic system to associate extracted targets, noun chunks determined to be associated with the expressed emotion, with affective labels from a natural language expression. We leverage a pre-trained neural network that is well adapted to tree and sub-tree processing, the Dependency Tree-LSTM, to learn the affect labels of dynamic targets, determined through symbolic rules, in natural language. We find that making use of the unique properties of the recursive network provides higher accuracy and interpretability when compared to other unstructured and sequential methods for determining target-affect associations in an aspect-based sentiment analysis task.
Analyzing the Influence of Dataset Composition for Emotion Recognition
Mar 05, 2021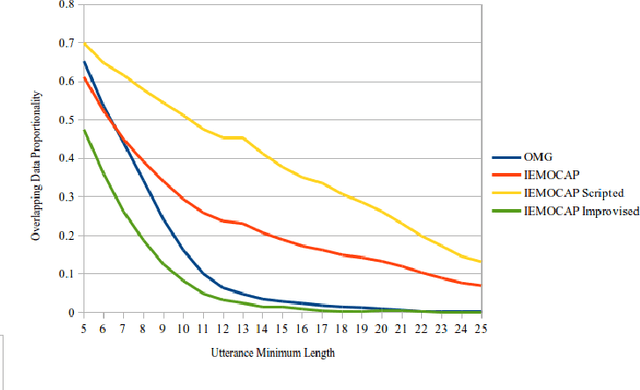

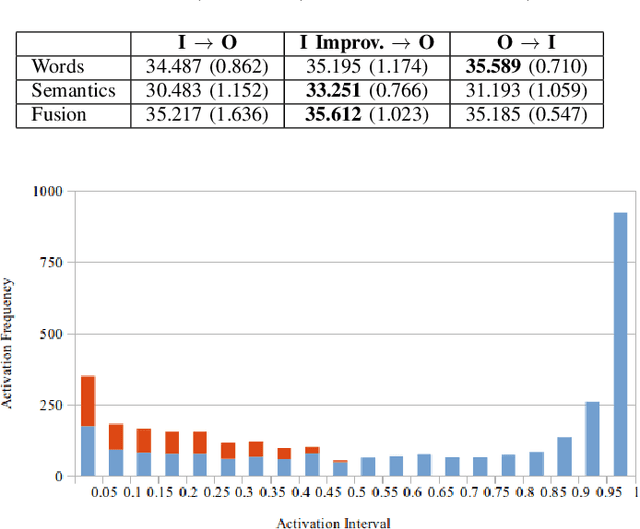
Recognizing emotions from text in multimodal architectures has yielded promising results, surpassing video and audio modalities under certain circumstances. However, the method by which multimodal data is collected can be significant for recognizing emotional features in language. In this paper, we address the influence data collection methodology has on two multimodal emotion recognition datasets, the IEMOCAP dataset and the OMG-Emotion Behavior dataset, by analyzing textual dataset compositions and emotion recognition accuracy. Experiments with the full IEMOCAP dataset indicate that the composition negatively influences generalization performance when compared to the OMG-Emotion Behavior dataset. We conclude by discussing the impact this may have on HRI experiments.