 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Text Extraction-Based Smart Knowledge Graph Composition for Integrating Lessons Learned during the Microchip Design
May 11, 2021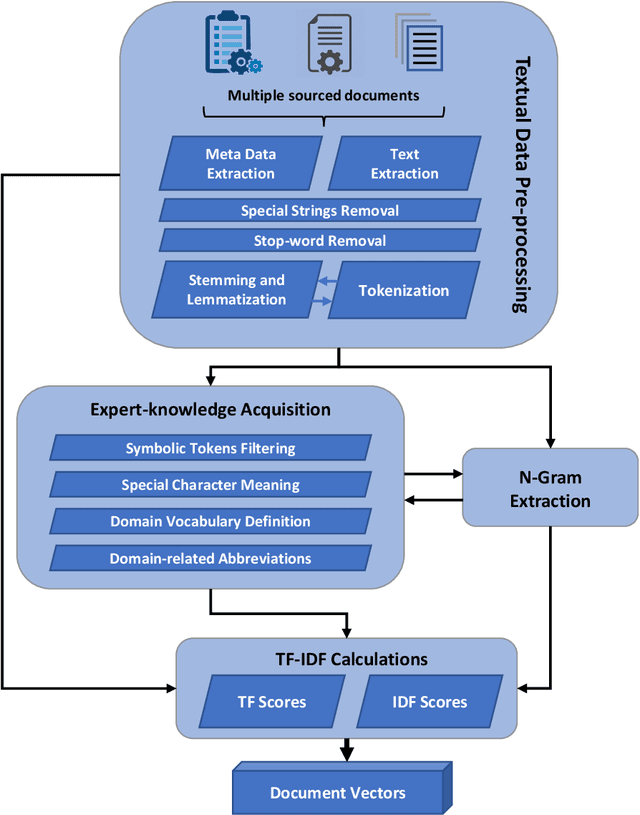
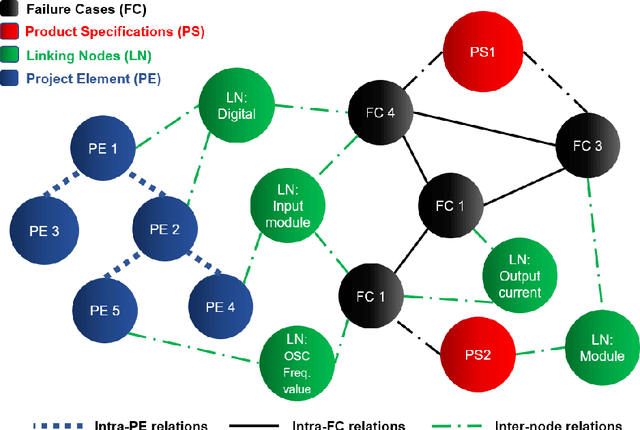

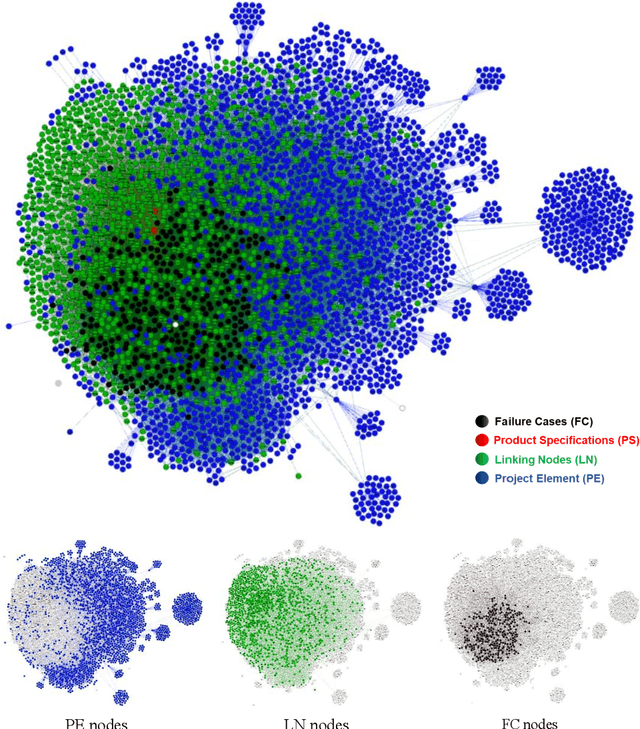
The production of microchips is a complex and thus well documented process. Therefore, available textual data about the production can be overwhelming in terms of quantity. This affects the visibility and retrieval of a certain piece of information when it is most needed. In this paper, we propose a dynamic approach to interlink the information extracted from multisource production-relevant documents through the creation of a knowledge graph. This graph is constructed in order to support searchability and enhance user's access to large-scale production information. Text mining methods are firstly utilized to extract data from multiple documentation sources. Document relations are then mined and extracted for the composition of the knowledge graph. Graph search functionality is then supported with a recommendation use-case to enhance users' access to information that is related to the initial documents. The proposed approach is tailored to and tested on microchip design-relevant documents. It enhances the visibility and findability of previous design-failure-cases during the process of a new chip design.
Analyzing the Influence of Dataset Composition for Emotion Recognition
Mar 05, 2021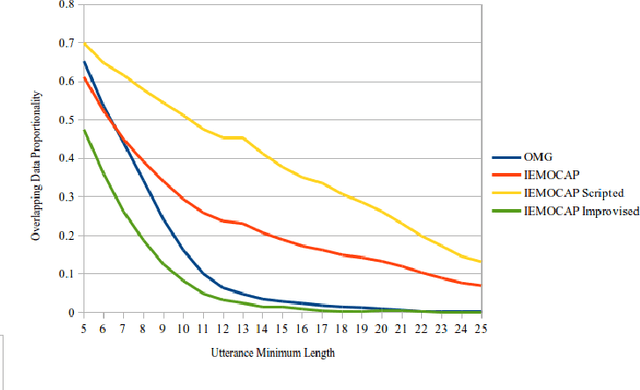

Recognizing emotions from text in multimodal architectures has yielded promising results, surpassing video and audio modalities under certain circumstances. However, the method by which multimodal data is collected can be significant for recognizing emotional features in language. In this paper, we address the influence data collection methodology has on two multimodal emotion recognition datasets, the IEMOCAP dataset and the OMG-Emotion Behavior dataset, by analyzing textual dataset compositions and emotion recognition accuracy. Experiments with the full IEMOCAP dataset indicate that the composition negatively influences generalization performance when compared to the OMG-Emotion Behavior dataset. We conclude by discussing the impact this may have on HRI experiments.