 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Rates for training Max-Margin Markov Networks
Mar 06, 2010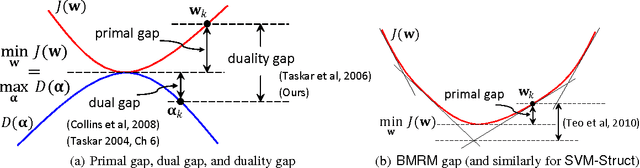
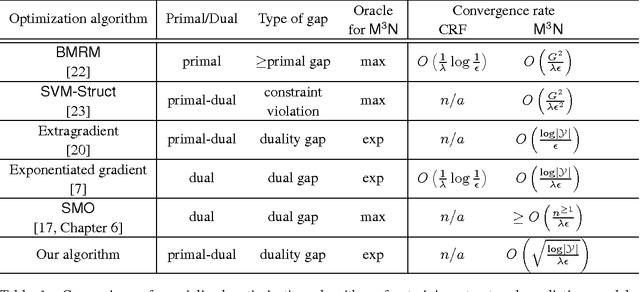

Structured output prediction is an important machine learning problem both in theory and practice, and the max-margin Markov network (\mcn) is an effective approach. All state-of-the-art algorithms for optimizing \mcn\ objectives take at least $O(1/\epsilon)$ number of iterations to find an $\epsilon$ accurate solution. Recent results in structured optimization suggest that faster rates are possible by exploiting the structure of the objective function. Towards this end \citet{Nesterov05} proposed an excessive gap reduction technique based on Euclidean projections which converges in $O(1/\sqrt{\epsilon})$ iterations on strongly convex functions. Unfortunately when applied to \mcn s, this approach does not admit graphical model factorization which, as in many existing algorithms, is crucial for keeping the cost per iteration tractable. In this paper, we present a new excessive gap reduction technique based on Bregman projections which admits graphical model factorization naturally, and converges in $O(1/\sqrt{\epsilon})$ iterations. Compared with existing algorithms, the convergence rate of our method has better dependence on $\epsilon$ and other parameters of the problem, and can be easily kernelized.
A Quasi-Newton Approach to Nonsmooth Convex Optimization Problems in Machine Learning
Feb 22, 2010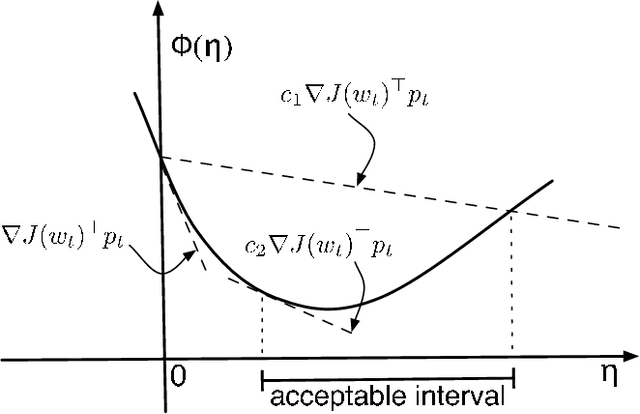
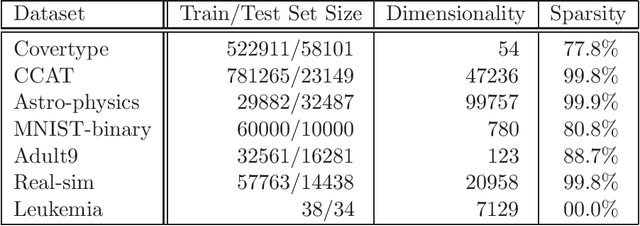
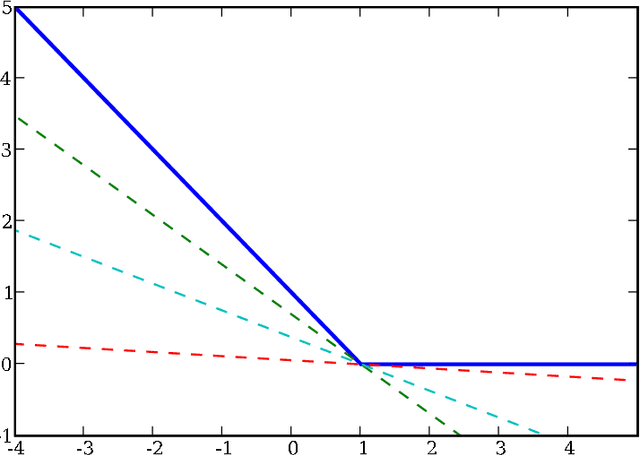
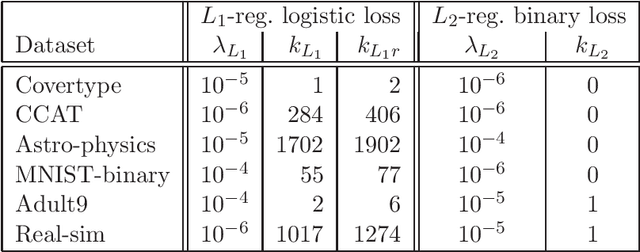
We extend the well-known BFGS quasi-Newton method and its memory-limited variant LBFGS to the optimization of nonsmooth convex objectives. This is done in a rigorous fashion by generalizing three components of BFGS to subdifferentials: the local quadratic model, the identification of a descent direction, and the Wolfe line search conditions. We prove that under some technical conditions, the resulting subBFGS algorithm is globally convergent in objective function value. We apply its memory-limited variant (subLBFGS) to L_2-regularized risk minimization with the binary hinge loss. To extend our algorithm to the multiclass and multilabel settings, we develop a new, efficient, exact line search algorithm. We prove its worst-case time complexity bounds, and show that our line search can also be used to extend a recently developed bundle method to the multiclass and multilabel settings. We also apply the direction-finding component of our algorithm to L_1-regularized risk minimization with logistic loss. In all these contexts our methods perform comparable to or better than specialized state-of-the-art solvers on a number of publicly available datasets. An open source implementation of our algorithms is freely available.
Lower Bounds for BMRM and Faster Rates for Training SVMs
Sep 08, 2009
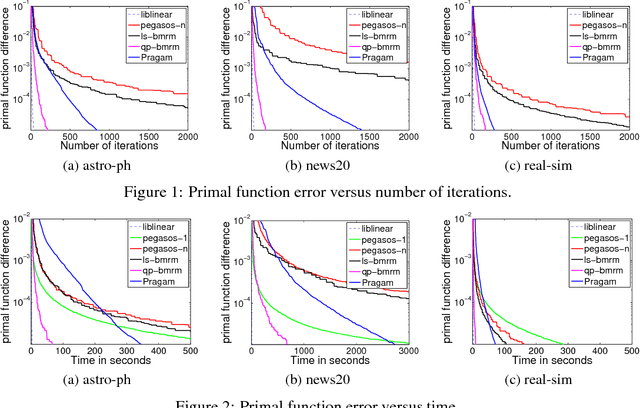
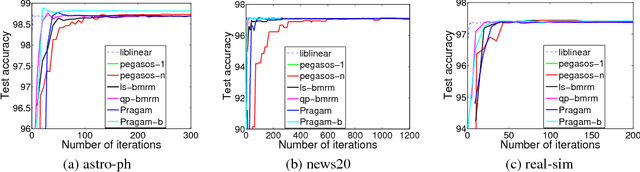
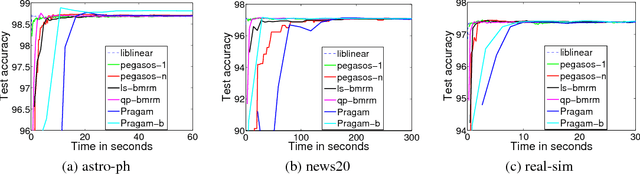
Regularized risk minimization with the binary hinge loss and its variants lies at the heart of many machine learning problems. Bundle methods for regularized risk minimization (BMRM) and the closely related SVMStruct are considered the best general purpose solvers to tackle this problem. It was recently shown that BMRM requires $O(1/\epsilon)$ iterations to converge to an $\epsilon$ accurate solution. In the first part of the paper we use the Hadamard matrix to construct a regularized risk minimization problem and show that these rates cannot be improved. We then show how one can exploit the structure of the objective function to devise an algorithm for the binary hinge loss which converges to an $\epsilon$ accurate solution in $O(1/\sqrt{\epsilon})$ iterations.
Graph Kernels
Jul 01, 2008
We present a unified framework to study graph kernels, special cases of which include the random walk graph kernel \citep{GaeFlaWro03,BorOngSchVisetal05}, marginalized graph kernel \citep{KasTsuIno03,KasTsuIno04,MahUedAkuPeretal04}, and geometric kernel on graphs \citep{Gaertner02}. Through extensions of linear algebra to Reproducing Kernel Hilbert Spaces (RKHS) and reduction to a Sylvester equation, we construct an algorithm that improves the time complexity of kernel computation from $O(n^6)$ to $O(n^3)$. When the graphs are sparse, conjugate gradient solvers or fixed-point iterations bring our algorithm into the sub-cubic domain. Experiments on graphs from bioinformatics and other application domains show that it is often more than a thousand times faster than previous approaches. We then explore connections between diffusion kernels \citep{KonLaf02}, regularization on graphs \citep{SmoKon03}, and graph kernels, and use these connections to propose new graph kernels. Finally, we show that rational kernels \citep{CorHafMoh02,CorHafMoh03,CorHafMoh04} when specialized to graphs reduce to the random walk graph kernel.
* http://jmlr.csail.mit.edu/papers/v11/vishwanathan10a.html