 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubasa -- Adapting Language Models for Low-resourced Offensive Language Detection in Sinhala
Apr 02, 2025



Accurate detection of offensive language is essential for a number of applications related to social media safety. There is a sharp contrast in performance in this task between low and high-resource languages. In this paper, we adapt fine-tuning strategies that have not been previously explored for Sinhala in the downstream task of offensive language detection. Using this approach, we introduce four models: "Subasa-XLM-R", which incorporates an intermediate Pre-Finetuning step using Masked Rationale Prediction. Two variants of "Subasa-Llama" and "Subasa-Mistral", are fine-tuned versions of Llama (3.2) and Mistral (v0.3), respectively, with a task-specific strategy. We evaluate our models on the SOLD benchmark dataset for Sinhala offensive language detection. All our models outperform existing baselines. Subasa-XLM-R achieves the highest Macro F1 score (0.84) surpassing state-of-the-art large language models like GPT-4o when evaluated on the same SOLD benchmark dataset under zero-shot settings. The models and code are publicly available.
KeyXtract Twitter Model - An Essential Keywords Extraction Model for Twitter Designed using NLP Tools
Aug 09, 2017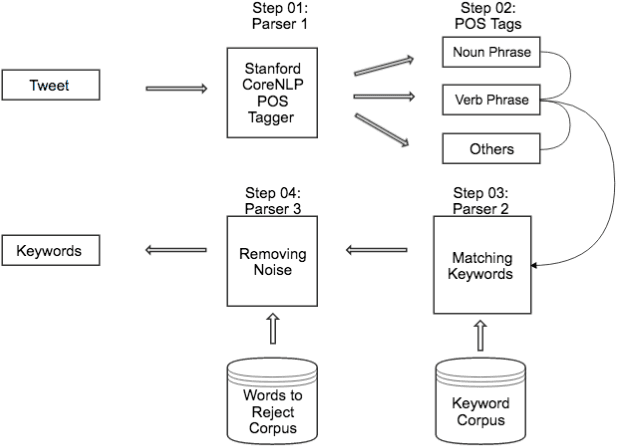
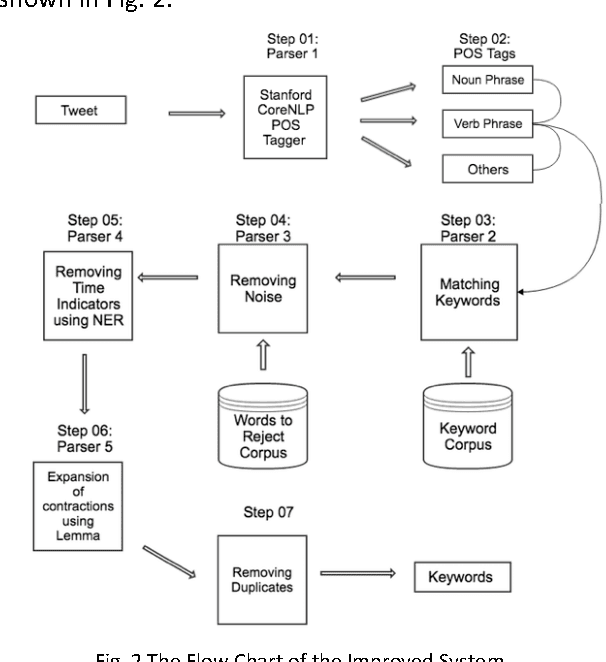
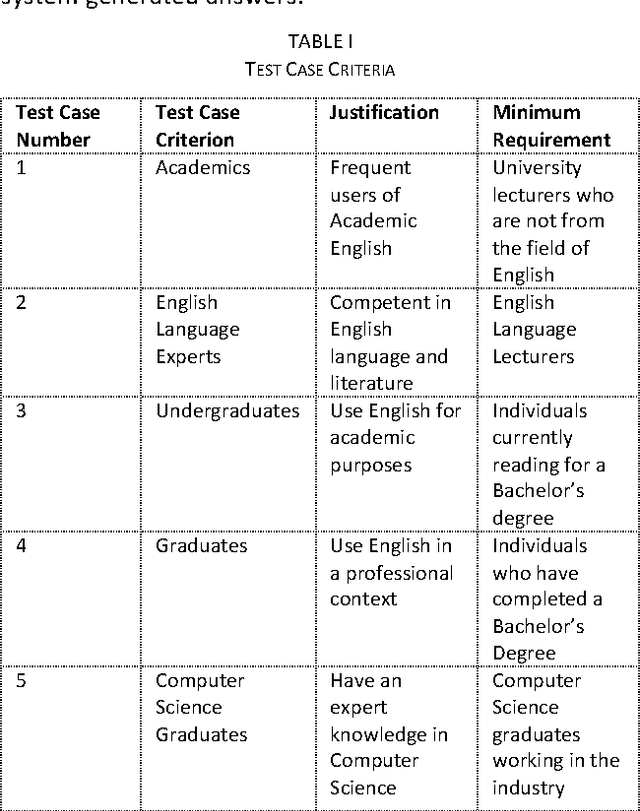
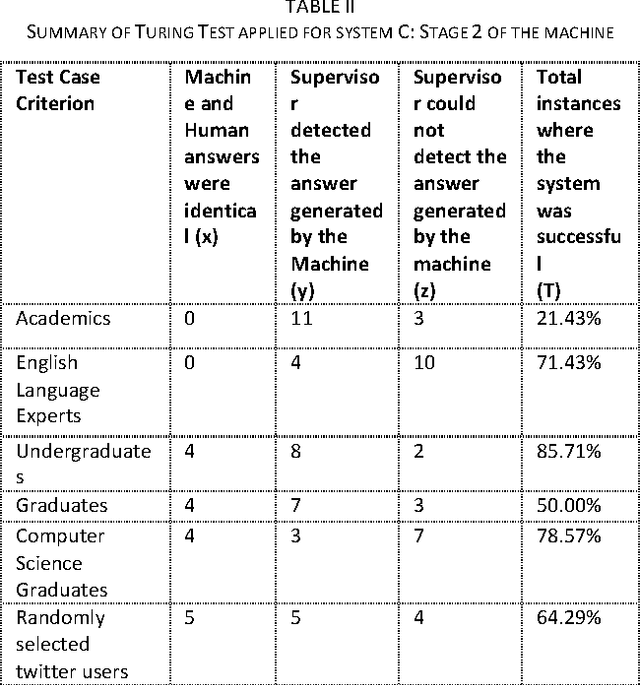
Since a tweet is limited to 140 characters, it is ambiguous and difficult for traditional Natural Language Processing (NLP) tools to analyse. This research presents KeyXtract which enhances the machine learning based Stanford CoreNLP Part-of-Speech (POS) tagger with the Twitter model to extract essential keywords from a tweet. The system was developed using rule-based parsers and two corpora. The data for the research was obtained from a Twitter profile of a telecommunication company. The system development consisted of two stages. At the initial stage, a domain specific corpus was compiled after analysing the tweets. The POS tagger extracted the Noun Phrases and Verb Phrases while the parsers removed noise and extracted any other keywords missed by the POS tagger. The system was evaluated using the Turing Test. After it was tested and compared against Stanford CoreNLP, the second stage of the system was developed addressing the shortcomings of the first stage. It was enhanced using Named Entity Recognition and Lemmatization. The second stage was also tested using the Turing test and its pass rate increased from 50.00% to 83.33%. The performance of the final system output was measured using the F1 score. Stanford CoreNLP with the Twitter model had an average F1 of 0.69 while the improved system had a F1 of 0.77. The accuracy of the system could be improved by using a complete domain specific corpus. Since the system used linguistic features of a sentence, it could be applied to other NLP tools.