 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-Goal Heuristic Search
Sep 29, 2011



This paper presents a new framework for anytime heuristic search where the task is to achieve as many goals as possible within the allocated resources. We show the inadequacy of traditional distance-estimation heuristics for tasks of this type and present alternative heuristics that are more appropriate for multiple-goal search. In particular, we introduce the marginal-utility heuristic, which estimates the cost and the benefit of exploring a subtree below a search node. We developed two methods for online learning of the marginal-utility heuristic. One is based on local similarity of the partial marginal utility of sibling nodes, and the other generalizes marginal-utility over the state feature space. We apply our adaptive and non-adaptive multiple-goal search algorithms to several problems, including focused crawling, and show their superiority over existing methods.
Learning to Order BDD Variables in Verification
Jun 30, 2011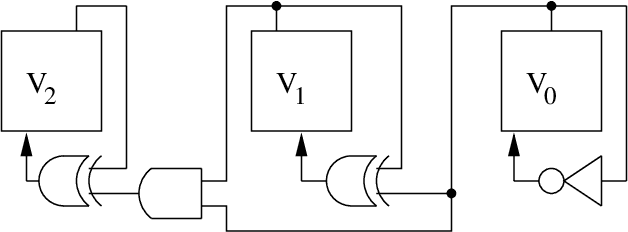

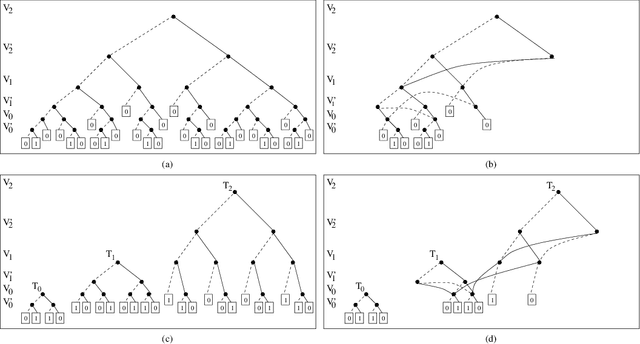

The size and complexity of software and hardware systems have significantly increased in the past years. As a result, it is harder to guarantee their correct behavior. One of the most successful methods for automated verification of finite-state systems is model checking. Most of the current model-checking systems use binary decision diagrams (BDDs) for the representation of the tested model and in the verification process of its properties. Generally, BDDs allow a canonical compact representation of a boolean function (given an order of its variables). The more compact the BDD is, the better performance one gets from the verifier. However, finding an optimal order for a BDD is an NP-complete problem. Therefore, several heuristic methods based on expert knowledge have been developed for variable ordering. We propose an alternative approach in which the variable ordering algorithm gains 'ordering experience' from training models and uses the learned knowledge for finding good orders. Our methodology is based on offline learning of pair precedence classifiers from training models, that is, learning which variable pair permutation is more likely to lead to a good order. For each training model, a number of training sequences are evaluated. Every training model variable pair permutation is then tagged based on its performance on the evaluated orders. The tagged permutations are then passed through a feature extractor and are given as examples to a classifier creation algorithm. Given a model for which an order is requested, the ordering algorithm consults each precedence classifier and constructs a pair precedence table which is used to create the order. Our algorithm was integrated with SMV, which is one of the most widely used verification systems. Preliminary empirical evaluation of our methodology, using real benchmark models, shows performance that is better than random ordering and is competitive with existing algorithms that use expert knowledge. We believe that in sub-domains of models (alu, caches, etc.) our system will prove even more valuable. This is because it features the ability to learn sub-domain knowledge, something that no other ordering algorithm does.
Optimal Schedules for Parallelizing Anytime Algorithms: The Case of Shared Resources
Jun 26, 2011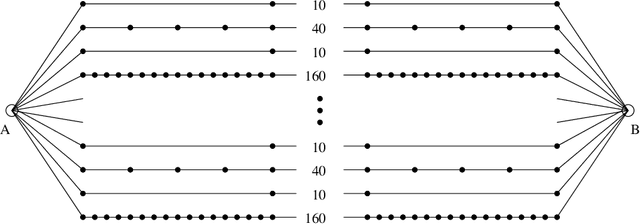
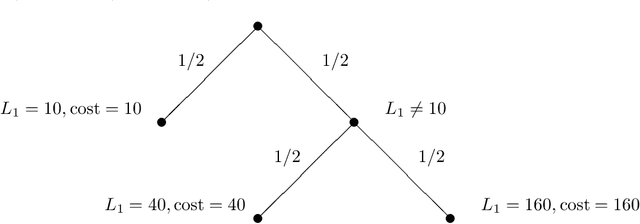
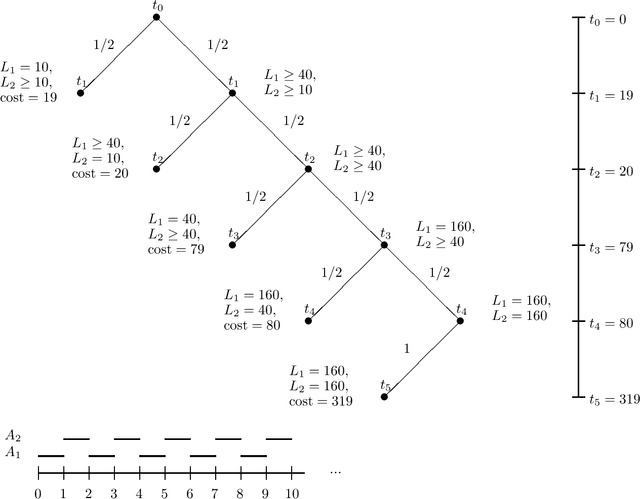
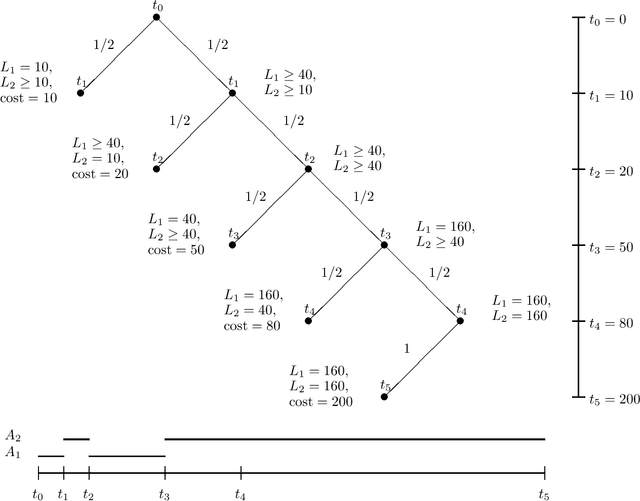
The performance of anytime algorithms can be improved by simultaneously solving several instances of algorithm-problem pairs. These pairs may include different instances of a problem (such as starting from a different initial state), different algorithms (if several alternatives exist), or several runs of the same algorithm (for non-deterministic algorithms). In this paper we present a methodology for designing an optimal scheduling policy based on the statistical characteristics of the algorithms involved. We formally analyze the case where the processes share resources (a single-processor model), and provide an algorithm for optimal scheduling. We analyze, theoretically and empirically, the behavior of our scheduling algorithm for various distribution types. Finally, we present empirical results of applying our scheduling algorithm to the Latin Square problem.
The Divide-and-Conquer Subgoal-Ordering Algorithm for Speeding up Logic Inference
May 27, 2011It is common to view programs as a combination of logic and control: the logic part defines what the program must do, the control part -- how to do it. The Logic Programming paradigm was developed with the intention of separating the logic from the control. Recently, extensive research has been conducted on automatic generation of control for logic programs. Only a few of these works considered the issue of automatic generation of control for improving the efficiency of logic programs. In this paper we present a novel algorithm for automatic finding of lowest-cost subgoal orderings. The algorithm works using the divide-and-conquer strategy. The given set of subgoals is partitioned into smaller sets, based on co-occurrence of free variables. The subsets are ordered recursively and merged, yielding a provably optimal order. We experimentally demonstrate the utility of the algorithm by testing it in several domains, and discuss the possibilities of its cooperation with other existing methods.
A Selective Macro-learning Algorithm and its Application to the NxN Sliding-Tile Puzzle
Jun 01, 1998One of the most common mechanisms used for speeding up problem solvers is macro-learning. Macros are sequences of basic operators acquired during problem solving. Macros are used by the problem solver as if they were basic operators. The major problem that macro-learning presents is the vast number of macros that are available for acquisition. Macros increase the branching factor of the search space and can severely degrade problem-solving efficiency. To make macro learning useful, a program must be selective in acquiring and utilizing macros. This paper describes a general method for selective acquisition of macros. Solvable training problems are generated in increasing order of difficulty. The only macros acquired are those that take the problem solver out of a local minimum to a better state. The utility of the method is demonstrated in several domains, including the domain of NxN sliding-tile puzzles. After learning on small puzzles, the system is able to efficiently solve puzzles of any size.
* See http://www.jair.org/ for an online appendix and other files accompanying this article