 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Schedules for Parallelizing Anytime Algorithms: The Case of Shared Resources
Jun 26, 2011
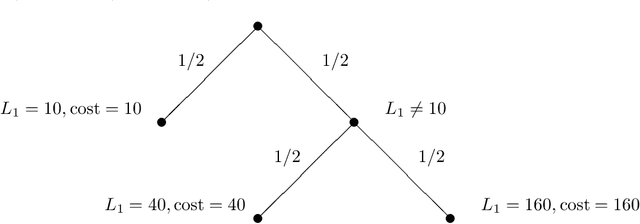
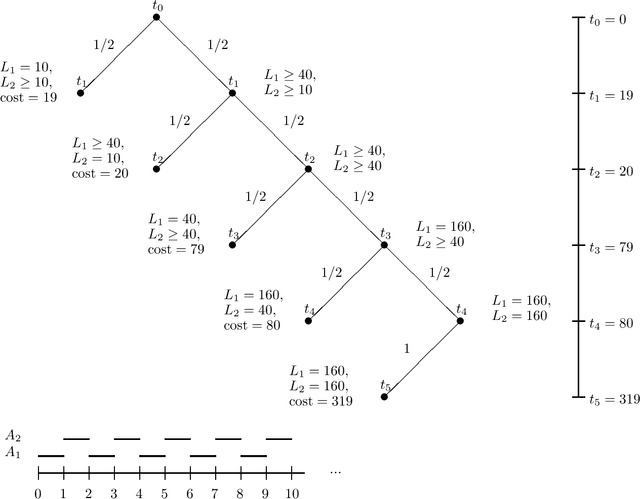
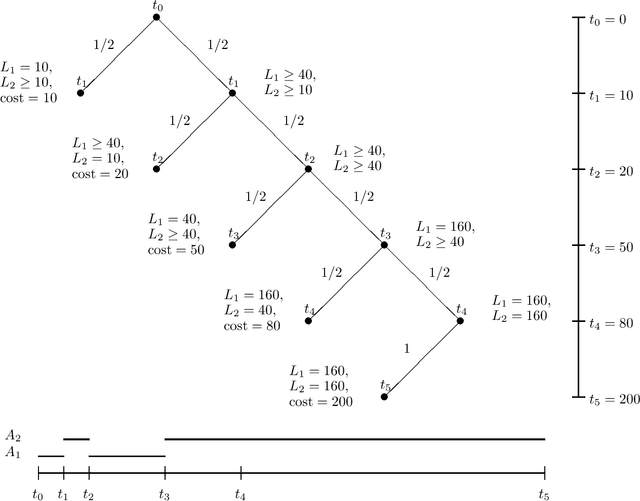
The performance of anytime algorithms can be improved by simultaneously solving several instances of algorithm-problem pairs. These pairs may include different instances of a problem (such as starting from a different initial state), different algorithms (if several alternatives exist), or several runs of the same algorithm (for non-deterministic algorithms). In this paper we present a methodology for designing an optimal scheduling policy based on the statistical characteristics of the algorithms involved. We formally analyze the case where the processes share resources (a single-processor model), and provide an algorithm for optimal scheduling. We analyze, theoretically and empirically, the behavior of our scheduling algorithm for various distribution types. Finally, we present empirical results of applying our scheduling algorithm to the Latin Square problem.
A Selective Macro-learning Algorithm and its Application to the NxN Sliding-Tile Puzzle
Jun 01, 1998One of the most common mechanisms used for speeding up problem solvers is macro-learning. Macros are sequences of basic operators acquired during problem solving. Macros are used by the problem solver as if they were basic operators. The major problem that macro-learning presents is the vast number of macros that are available for acquisition. Macros increase the branching factor of the search space and can severely degrade problem-solving efficiency. To make macro learning useful, a program must be selective in acquiring and utilizing macros. This paper describes a general method for selective acquisition of macros. Solvable training problems are generated in increasing order of difficulty. The only macros acquired are those that take the problem solver out of a local minimum to a better state. The utility of the method is demonstrated in several domains, including the domain of NxN sliding-tile puzzles. After learning on small puzzles, the system is able to efficiently solve puzzles of any size.
* See http://www.jair.org/ for an online appendix and other files accompanying this article