 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Mining-Based Techniques for Software Fault Localization
May 23, 2025This chapter illustrates the basic concepts of fault localization using a data mining technique. It utilizes the Trityp program to illustrate the general method. Formal concept analysis and association rule are two well-known methods for symbolic data mining. In their original inception, they both consider data in the form of an object-attribute table. In their original inception, they both consider data in the form of an object-attribute table. The chapter considers a debugging process in which a program is tested against different test cases. Two attributes, PASS and FAIL, represent the issue of the test case. The chapter extends the analysis of data mining for fault localization for the multiple fault situations. It addresses how data mining can be further applied to fault localization for GUI components. Unlike traditional software, GUI test cases are usually event sequences, and each individual event has a unique corresponding event handler.
MADIL: An MDL-based Framework for Efficient Program Synthesis in the ARC Benchmark
May 02, 2025Artificial Intelligence (AI) has achieved remarkable success in specialized tasks but struggles with efficient skill acquisition and generalization. The Abstraction and Reasoning Corpus (ARC) benchmark evaluates intelligence based on minimal training requirements. While Large Language Models (LLMs) have recently improved ARC performance, they rely on extensive pre-training and high computational costs. We introduce MADIL (MDL-based AI), a novel approach leveraging the Minimum Description Length (MDL) principle for efficient inductive learning. MADIL performs pattern-based decomposition, enabling structured generalization. While its performance (7% at ArcPrize 2024) remains below LLM-based methods, it offers greater efficiency and interpretability. This paper details MADIL's methodology, its application to ARC, and experimental evaluations.
Tackling the Abstraction and Reasoning Corpus (ARC) with Object-centric Models and the MDL Principle
Nov 01, 2023The Abstraction and Reasoning Corpus (ARC) is a challenging benchmark, introduced to foster AI research towards human-level intelligence. It is a collection of unique tasks about generating colored grids, specified by a few examples only. In contrast to the transformation-based programs of existing work, we introduce object-centric models that are in line with the natural programs produced by humans. Our models can not only perform predictions, but also provide joint descriptions for input/output pairs. The Minimum Description Length (MDL) principle is used to efficiently search the large model space. A diverse range of tasks are solved, and the learned models are similar to the natural programs. We demonstrate the generality of our approach by applying it to a different domain.
KG-MDL: Mining Graph Patterns in Knowledge Graphs with the MDL Principle
Sep 22, 2023Nowadays, increasingly more data are available as knowledge graphs (KGs). While this data model supports advanced reasoning and querying, they remain difficult to mine due to their size and complexity. Graph mining approaches can be used to extract patterns from KGs. However this presents two main issues. First, graph mining approaches tend to extract too many patterns for a human analyst to interpret (pattern explosion). Second, real-life KGs tend to differ from the graphs usually treated in graph mining: they are multigraphs, their vertex degrees tend to follow a power-law, and the way in which they model knowledge can produce spurious patterns. Recently, a graph mining approach named GraphMDL+ has been proposed to tackle the problem of pattern explosion, using the Minimum Description Length (MDL) principle. However, GraphMDL+, like other graph mining approaches, is not suited for KGs without adaptations. In this paper we propose KG-MDL, a graph pattern mining approach based on the MDL principle that, given a KG, generates a human-sized and descriptive set of graph patterns, and so in a parameter-less and anytime way. We report on experiments on medium-sized KGs showing that our approach generates sets of patterns that are both small enough to be interpreted by humans and descriptive of the KG. We show that the extracted patterns highlight relevant characteristics of the data: both of the schema used to create the data, and of the concrete facts it contains. We also discuss the issues related to mining graph patterns on knowledge graphs, as opposed to other types of graph data.
First Steps of an Approach to the ARC Challenge based on Descriptive Grid Models and the Minimum Description Length Principle
Dec 01, 2021


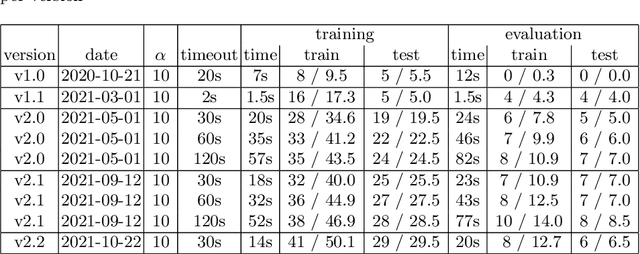
The Abstraction and Reasoning Corpus (ARC) was recently introduced by Fran\c{c}ois Chollet as a tool to measure broad intelligence in both humans and machines. It is very challenging, and the best approach in a Kaggle competition could only solve 20% of the tasks, relying on brute-force search for chains of hand-crafted transformations. In this paper, we present the first steps exploring an approach based on descriptive grid models and the Minimum Description Length (MDL) principle. The grid models describe the contents of a grid, and support both parsing grids and generating grids. The MDL principle is used to guide the search for good models, i.e. models that compress the grids the most. We report on our progress over a year, improving on the general approach and the models. Out of the 400 training tasks, our performance increased from 5 to 29 solved tasks, only using 30s computation time per task. Our approach not only predicts the output grids, but also outputs an intelligible model and explanations for how the model was incrementally built.