 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning and the Global Workspace Theory
Dec 04, 2020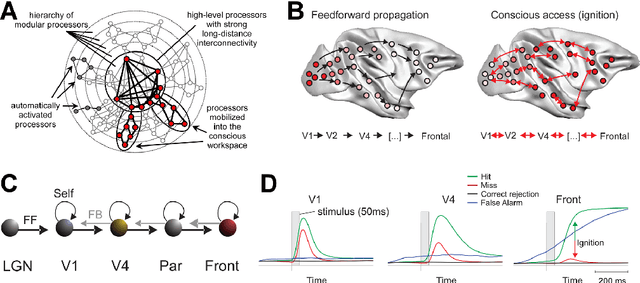
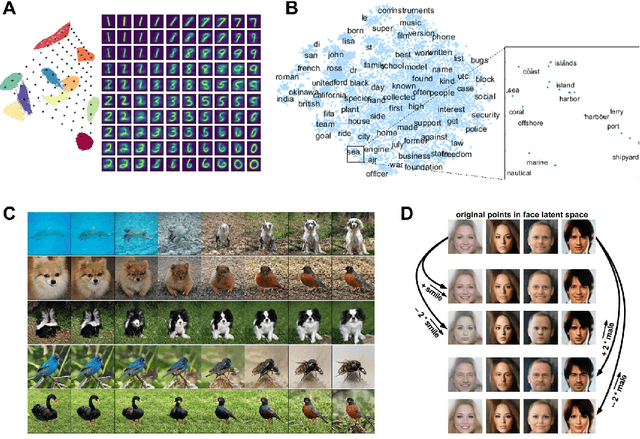

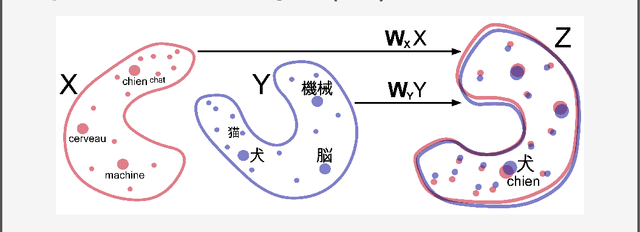
Recent advances in deep learning have allowed Artificial Intelligence (AI) to reach near human-level performance in many sensory, perceptual, linguistic or cognitive tasks. There is a growing need, however, for novel, brain-inspired cognitive architectures. The Global Workspace theory refers to a large-scale system integrating and distributing information among networks of specialized modules to create higher-level forms of cognition and awareness. We argue that the time is ripe to consider explicit implementations of this theory using deep learning techniques. We propose a roadmap based on unsupervised neural translation between multiple latent spaces (neural networks trained for distinct tasks, on distinct sensory inputs and/or modalities) to create a unique, amodal global latent workspace (GLW). Potential functional advantages of GLW are reviewed.
Non-trivial informational closure of a Bayesian hyperparameter
Oct 05, 2020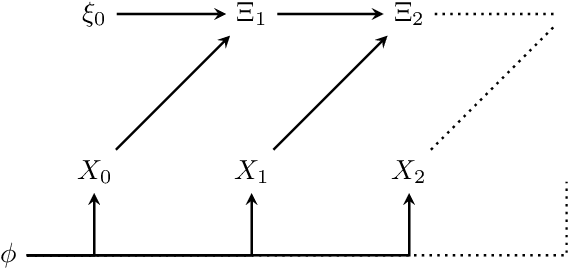
We investigate the non-trivial informational closure (NTIC) of a Bayesian hyperparameter inferring the underlying distribution of an identically and independently distributed finite random variable. For this we embed both the Bayesian hyper-parameter updating process and the random data process into a Markov chain. The original publication by Bertschinger et al. (2006) mentioned that NTIC may be able to capture an abstract notion of modeling that is agnostic to the specific internal structure of and existence of explicit representations within the modeling process. The Bayesian hyperparameter is of interest since it has a well defined interpretation as a model of the data process and at the same time its dynamics can be specified without reference to this interpretation. On the one hand we show explicitly that the NTIC of the hyperparameter increases indefinitely over time. On the other hand we attempt to establish a connection between a quantity that is a feature of the interpretation of the hyperparameter as a model, namely the information gain, and the one-step pointwise NTIC which is a quantity that does not depend on this interpretation. We find that in general we cannot use the one-step pointwise NTIC as an indicator for information gain. We hope this exploratory work can lead to further rigorous studies of the relation between NTIC and modeling.
A unified strategy for implementing curiosity and empowerment driven reinforcement learning
Jun 18, 2018
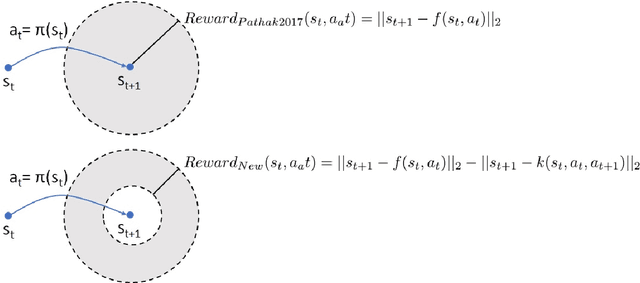
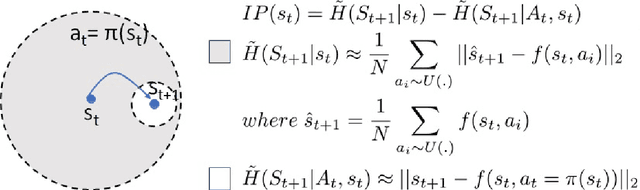
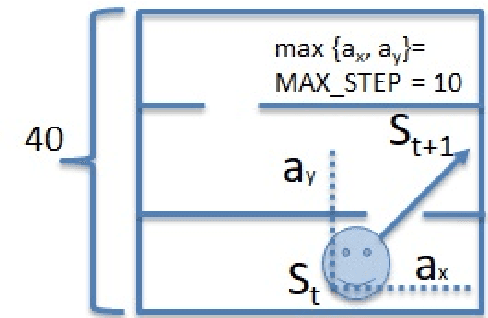
Although there are many approaches to implement intrinsically motivated artificial agents, the combined usage of multiple intrinsic drives remains still a relatively unexplored research area. Specifically, we hypothesize that a mechanism capable of quantifying and controlling the evolution of the information flow between the agent and the environment could be the fundamental component for implementing a higher degree of autonomy into artificial intelligent agents. This paper propose a unified strategy for implementing two semantically orthogonal intrinsic motivations: curiosity and empowerment. Curiosity reward informs the agent about the relevance of a recent agent action, whereas empowerment is implemented as the opposite information flow from the agent to the environment that quantifies the agent's potential of controlling its own future. We show that an additional homeostatic drive is derived from the curiosity reward, which generalizes and enhances the information gain of a classical curious/heterostatic reinforcement learning agent. We show how a shared internal model by curiosity and empowerment facilitates a more efficient training of the empowerment function. Finally, we discuss future directions for further leveraging the interplay between these two intrinsic rewards.
Boredom-driven curious learning by Homeo-Heterostatic Value Gradients
Jun 05, 2018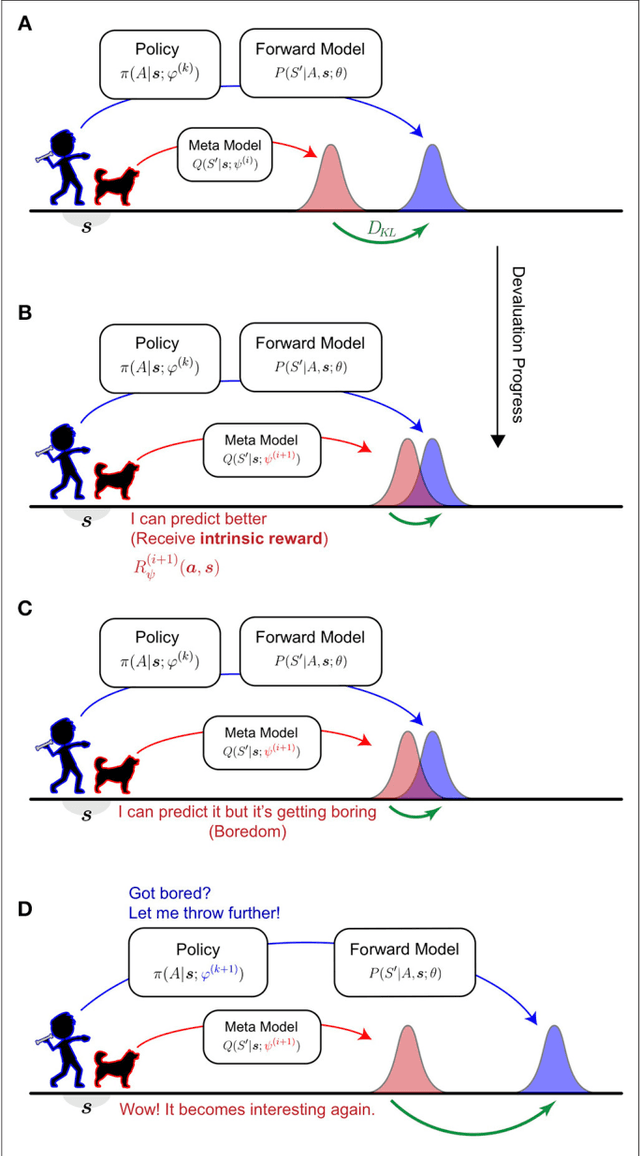

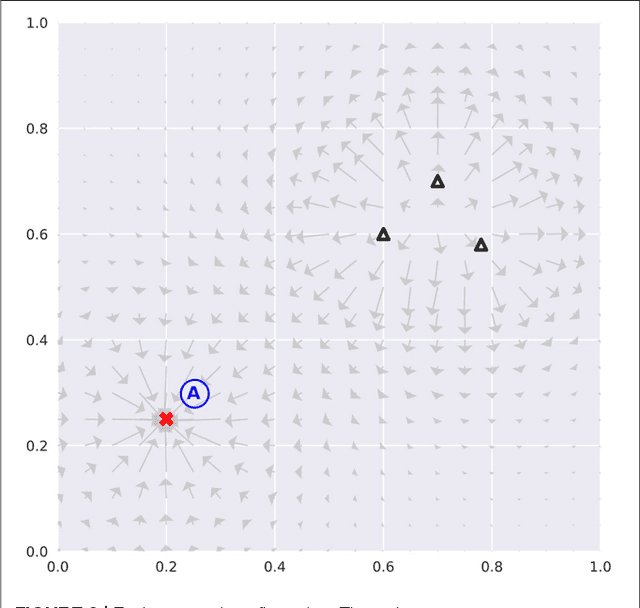
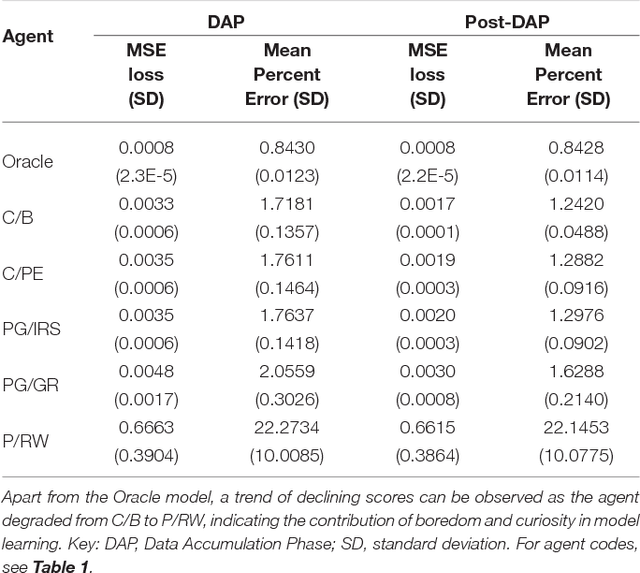
This paper presents the Homeo-Heterostatic Value Gradients (HHVG) algorithm as a formal account on the constructive interplay between boredom and curiosity which gives rise to effective exploration and superior forward model learning. We envisaged actions as instrumental in agent's own epistemic disclosure. This motivated two central algorithmic ingredients: devaluation and devaluation progress, both underpin agent's cognition concerning intrinsically generated rewards. The two serve as an instantiation of homeostatic and heterostatic intrinsic motivation. A key insight from our algorithm is that the two seemingly opposite motivations can be reconciled---without which exploration and information-gathering cannot be effectively carried out. We supported this claim with empirical evidence, showing that boredom-enabled agents consistently outperformed other curious or explorative agent variants in model building benchmarks based on self-assisted experience accumulation.
Being curious about the answers to questions: novelty search with learned attention
Jun 01, 2018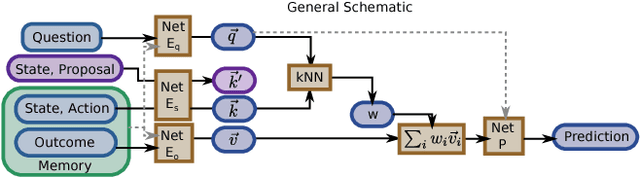

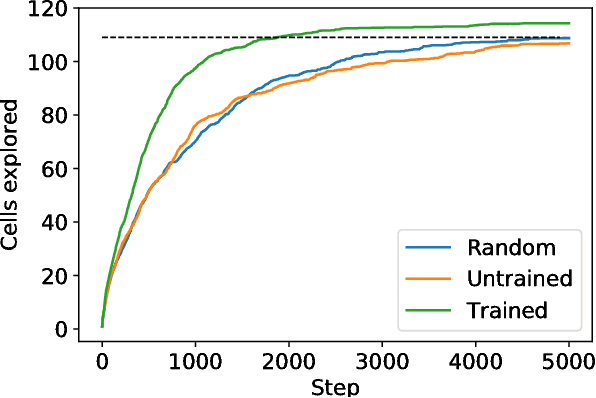
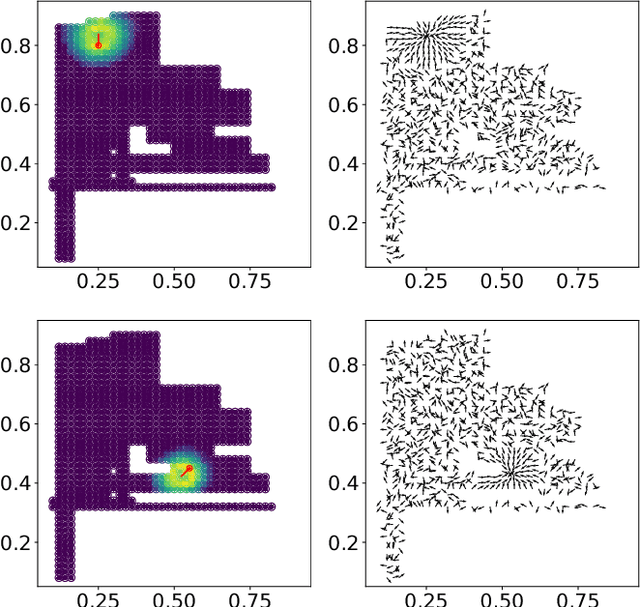
We investigate the use of attentional neural network layers in order to learn a `behavior characterization' which can be used to drive novelty search and curiosity-based policies. The space is structured towards answering a particular distribution of questions, which are used in a supervised way to train the attentional neural network. We find that in a 2d exploration task, the structure of the space successfully encodes local sensory-motor contingencies such that even a greedy local `do the most novel action' policy with no reinforcement learning or evolution can explore the space quickly. We also apply this to a high/low number guessing game task, and find that guessing according to the learned attention profile performs active inference and can discover the correct number more quickly than an exact but passive approach.
Learning to generate classifiers
Mar 30, 2018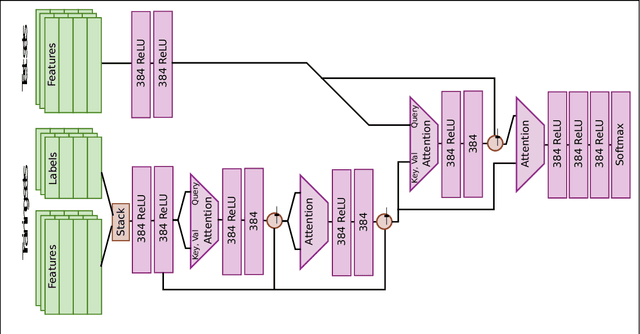
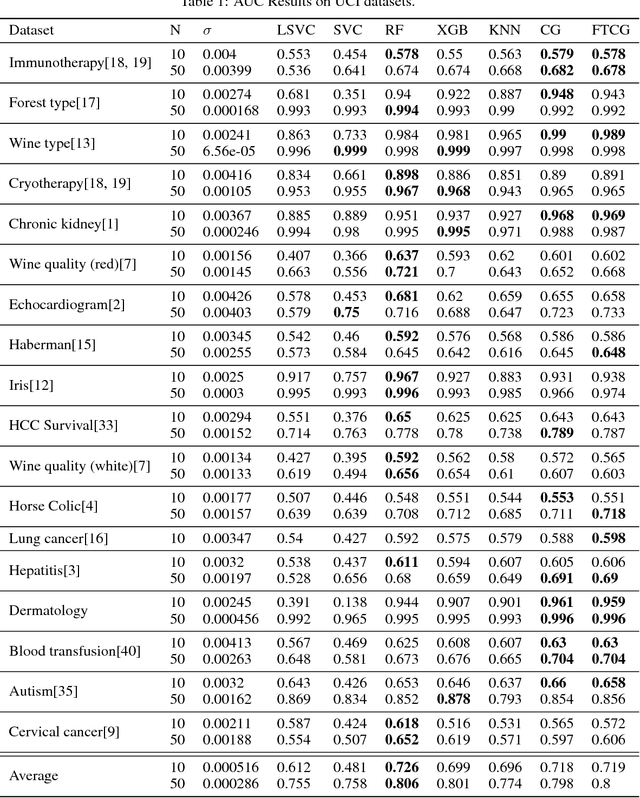
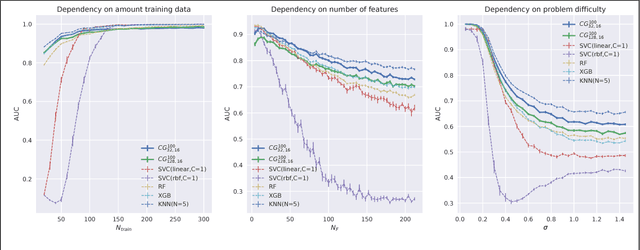
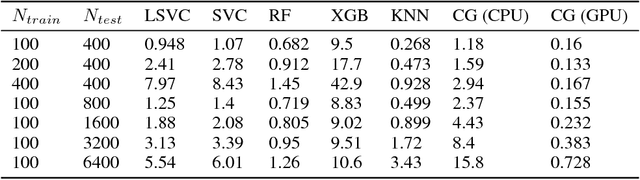
We train a network to generate mappings between training sets and classification policies (a 'classifier generator') by conditioning on the entire training set via an attentional mechanism. The network is directly optimized for test set performance on an training set of related tasks, which is then transferred to unseen 'test' tasks. We use this to optimize for performance in the low-data and unsupervised learning regimes, and obtain significantly better performance in the 10-50 datapoint regime than support vector classifiers, random forests, XGBoost, and k-nearest neighbors on a range of small datasets.
Efficient Algorithms for Searching the Minimum Information Partition in Integrated Information Theory
Feb 13, 2018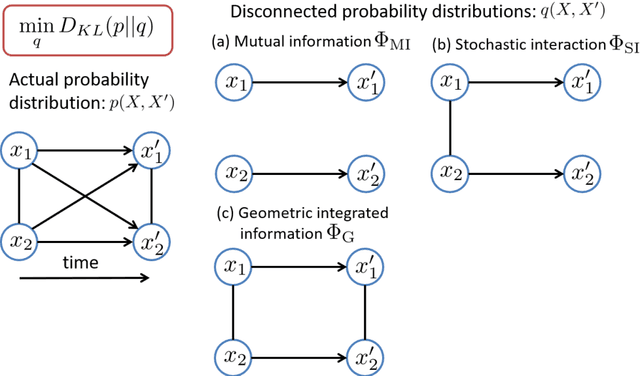
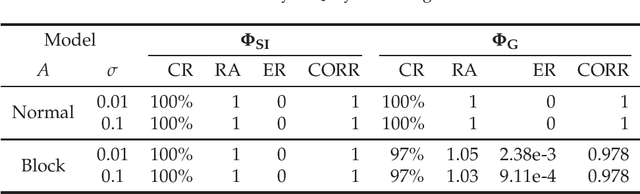
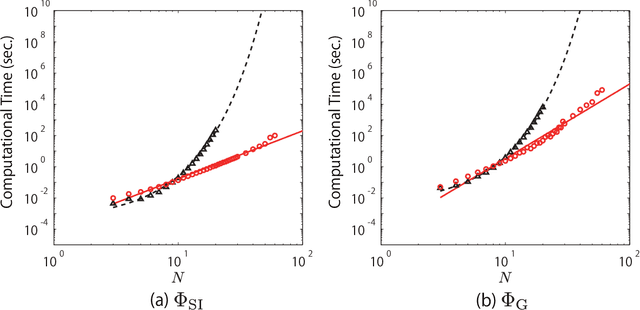
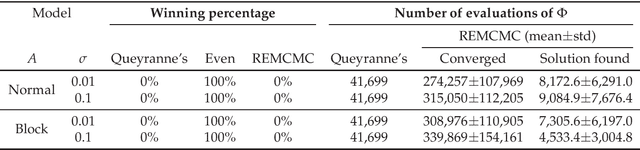
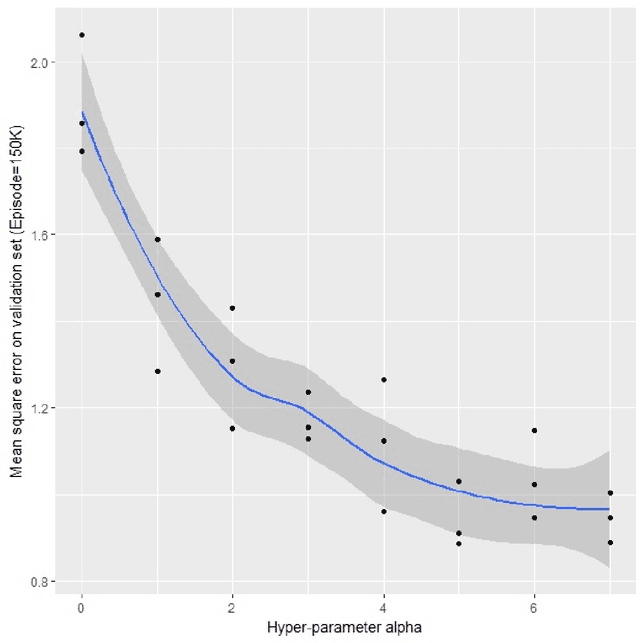
The ability to integrate information in the brain is considered to be an essential property for cognition and consciousness. Integrated Information Theory (IIT) hypothesizes that the amount of integrated information ($\Phi$) in the brain is related to the level of consciousness. IIT proposes that to quantify information integration in a system as a whole, integrated information should be measured across the partition of the system at which information loss caused by partitioning is minimized, called the Minimum Information Partition (MIP). The computational cost for exhaustively searching for the MIP grows exponentially with system size, making it difficult to apply IIT to real neural data. It has been previously shown that if a measure of $\Phi$ satisfies a mathematical property, submodularity, the MIP can be found in a polynomial order by an optimization algorithm. However, although the first version of $\Phi$ is submodular, the later versions are not. In this study, we empirically explore to what extent the algorithm can be applied to the non-submodular measures of $\Phi$ by evaluating the accuracy of the algorithm in simulated data and real neural data. We find that the algorithm identifies the MIP in a nearly perfect manner even for the non-submodular measures. Our results show that the algorithm allows us to measure $\Phi$ in large systems within a practical amount of time.
Curiosity-driven reinforcement learning with homeostatic regulation
Feb 07, 2018
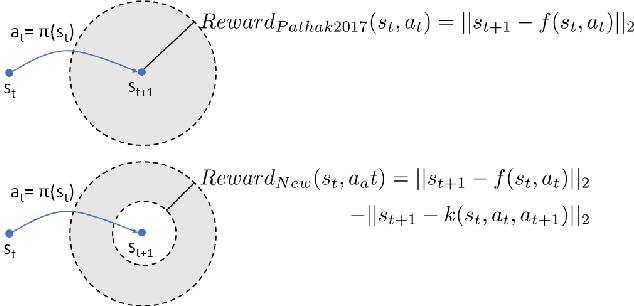
We propose a curiosity reward based on information theory principles and consistent with the animal instinct to maintain certain critical parameters within a bounded range. Our experimental validation shows the added value of the additional homeostatic drive to enhance the overall information gain of a reinforcement learning agent interacting with a complex environment using continuous actions. Our method builds upon two ideas: i) To take advantage of a new Bellman-like equation of information gain and ii) to simplify the computation of the local rewards by avoiding the approximation of complex distributions over continuous states and actions.
Learning body-affordances to simplify action spaces
Aug 15, 2017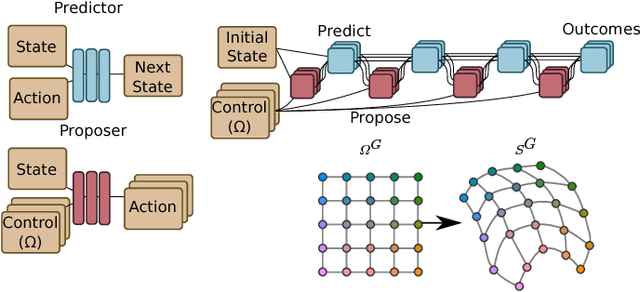
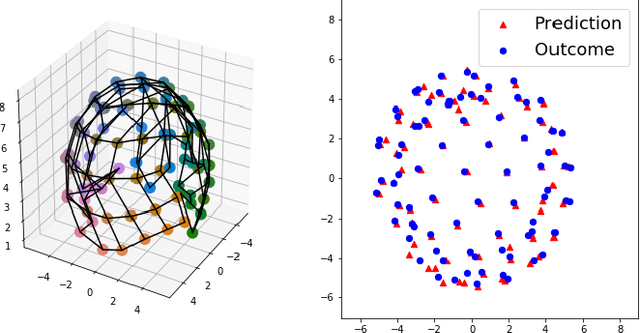
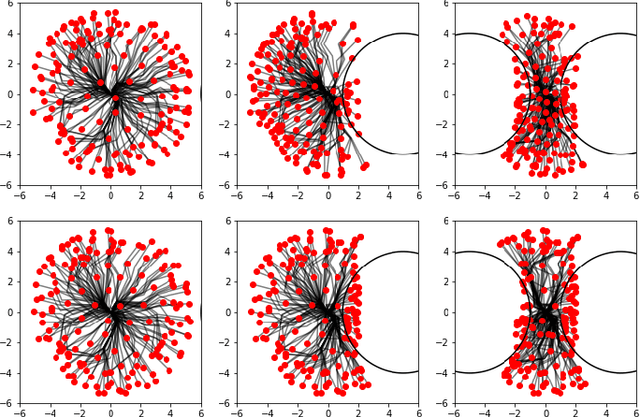
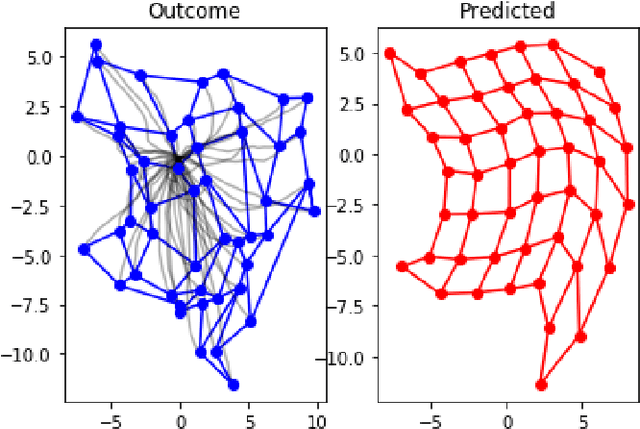
Controlling embodied agents with many actuated degrees of freedom is a challenging task. We propose a method that can discover and interpolate between context dependent high-level actions or body-affordances. These provide an abstract, low-dimensional interface indexing high-dimensional and time- extended action policies. Our method is related to recent ap- proaches in the machine learning literature but is conceptually simpler and easier to implement. More specifically our method requires the choice of a n-dimensional target sensor space that is endowed with a distance metric. The method then learns an also n-dimensional embedding of possibly reactive body-affordances that spread as far as possible throughout the target sensor space.
Counterfactual Control for Free from Generative Models
Mar 09, 2017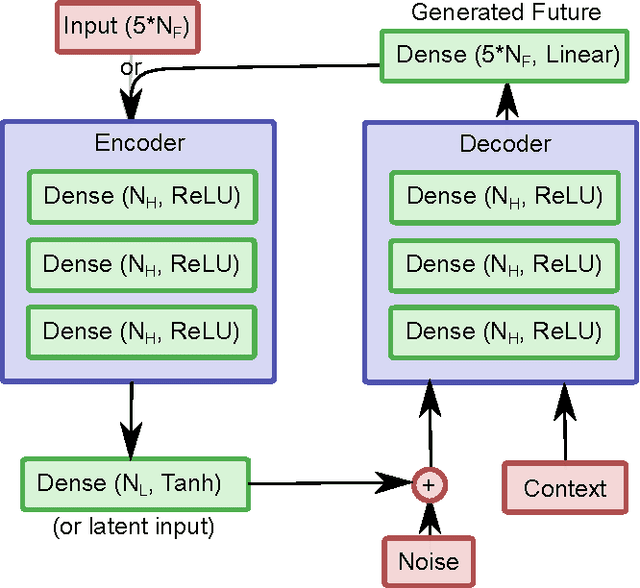
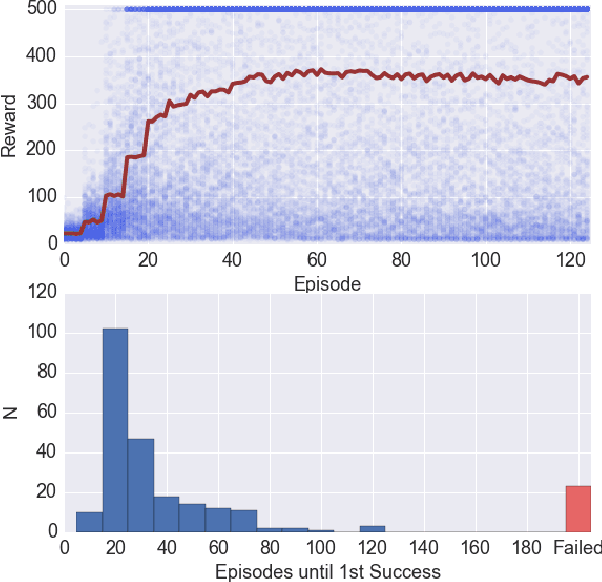
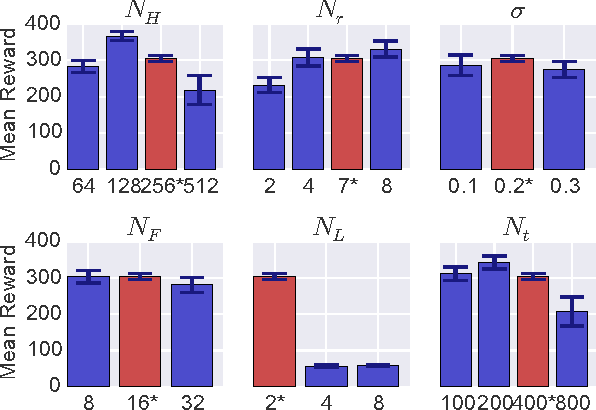
We introduce a method by which a generative model learning the joint distribution between actions and future states can be used to automatically infer a control scheme for any desired reward function, which may be altered on the fly without retraining the model. In this method, the problem of action selection is reduced to one of gradient descent on the latent space of the generative model, with the model itself providing the means of evaluating outcomes and finding the gradient, much like how the reward network in Deep Q-Networks (DQN) provides gradient information for the action generator. Unlike DQN or Actor-Critic, which are conditional models for a specific reward, using a generative model of the full joint distribution permits the reward to be changed on the fly. In addition, the generated futures can be inspected to gain insight in to what the network 'thinks' will happen, and to what went wrong when the outcomes deviate from prediction.