 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbarrassingly Simple Text Watermarks
Oct 13, 2023



We propose Easymark, a family of embarrassingly simple yet effective watermarks. Text watermarking is becoming increasingly important with the advent of Large Language Models (LLM). LLMs can generate texts that cannot be distinguished from human-written texts. This is a serious problem for the credibility of the text. Easymark is a simple yet effective solution to this problem. Easymark can inject a watermark without changing the meaning of the text at all while a validator can detect if a text was generated from a system that adopted Easymark or not with high credibility. Easymark is extremely easy to implement so that it only requires a few lines of code. Easymark does not require access to LLMs, so it can be implemented on the user-side when the LLM providers do not offer watermarked LLMs. In spite of its simplicity, it achieves higher detection accuracy and BLEU scores than the state-of-the-art text watermarking methods. We also prove the impossibility theorem of perfect watermarking, which is valuable in its own right. This theorem shows that no matter how sophisticated a watermark is, a malicious user could remove it from the text, which motivate us to use a simple watermark such as Easymark. We carry out experiments with LLM-generated texts and confirm that Easymark can be detected reliably without any degradation of BLEU and perplexity, and outperform state-of-the-art watermarks in terms of both quality and reliability.
Necessary and Sufficient Watermark for Large Language Models
Oct 02, 2023



In recent years, large language models (LLMs) have achieved remarkable performances in various NLP tasks. They can generate texts that are indistinguishable from those written by humans. Such remarkable performance of LLMs increases their risk of being used for malicious purposes, such as generating fake news articles. Therefore, it is necessary to develop methods for distinguishing texts written by LLMs from those written by humans. Watermarking is one of the most powerful methods for achieving this. Although existing watermarking methods have successfully detected texts generated by LLMs, they significantly degrade the quality of the generated texts. In this study, we propose the Necessary and Sufficient Watermark (NS-Watermark) for inserting watermarks into generated texts without degrading the text quality. More specifically, we derive minimum constraints required to be imposed on the generated texts to distinguish whether LLMs or humans write the texts. Then, we formulate the NS-Watermark as a constrained optimization problem and propose an efficient algorithm to solve it. Through the experiments, we demonstrate that the NS-Watermark can generate more natural texts than existing watermarking methods and distinguish more accurately between texts written by LLMs and those written by humans. Especially in machine translation tasks, the NS-Watermark can outperform the existing watermarking method by up to 30 BLEU scores.
Beyond Exponential Graph: Communication-Efficient Topologies for Decentralized Learning via Finite-time Convergence
May 19, 2023Decentralized learning has recently been attracting increasing attention for its applications in parallel computation and privacy preservation. Many recent studies stated that the underlying network topology with a faster consensus rate (a.k.a. spectral gap) leads to a better convergence rate and accuracy for decentralized learning. However, a topology with a fast consensus rate, e.g., the exponential graph, generally has a large maximum degree, which incurs significant communication costs. Thus, seeking topologies with both a fast consensus rate and small maximum degree is important. In this study, we propose a novel topology combining both a fast consensus rate and small maximum degree called the Base-$(k + 1)$ Graph. Unlike the existing topologies, the Base-$(k + 1)$ Graph enables all nodes to reach the exact consensus after a finite number of iterations for any number of nodes and maximum degree k. Thanks to this favorable property, the Base-$(k + 1)$ Graph endows Decentralized SGD (DSGD) with both a faster convergence rate and more communication efficiency than the exponential graph. We conducted experiments with various topologies, demonstrating that the Base-$(k + 1)$ Graph enables various decentralized learning methods to achieve higher accuracy with better communication efficiency than the existing topologies.
Graph Neural Networks can Recover the Hidden Features Solely from the Graph Structure
Jan 26, 2023



Graph Neural Networks (GNNs) are popular models for graph learning problems. GNNs show strong empirical performance in many practical tasks. However, the theoretical properties have not been completely elucidated. In this paper, we investigate whether GNNs can exploit the graph structure from the perspective of the expressive power of GNNs. In our analysis, we consider graph generation processes that are controlled by hidden node features, which contain all information about the graph structure. A typical example of this framework is kNN graphs constructed from the hidden features. In our main results, we show that GNNs can recover the hidden node features from the input graph alone, even when all node features, including the hidden features themselves and any indirect hints, are unavailable. GNNs can further use the recovered node features for downstream tasks. These results show that GNNs can fully exploit the graph structure by themselves, and in effect, GNNs can use both the hidden and explicit node features for downstream tasks. In the experiments, we confirm the validity of our results by showing that GNNs can accurately recover the hidden features using a GNN architecture built based on our theoretical analysis.
Active Learning from the Web
Oct 15, 2022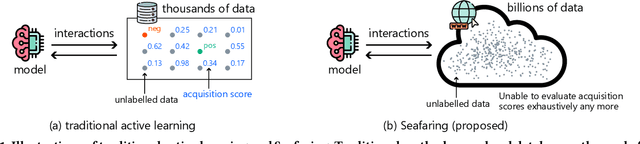

Labeling data is one of the most costly processes in machine learning pipelines. Active learning is a standard approach to alleviating this problem. Pool-based active learning first builds a pool of unlabelled data and iteratively selects data to be labeled so that the total number of required labels is minimized, keeping the model performance high. Many effective criteria for choosing data from the pool have been proposed in the literature. However, how to build the pool is less explored. Specifically, most of the methods assume that a task-specific pool is given for free. In this paper, we advocate that such a task-specific pool is not always available and propose the use of a myriad of unlabelled data on the Web for the pool for which active learning is applied. As the pool is extremely large, it is likely that relevant data exist in the pool for many tasks, and we do not need to explicitly design and build the pool for each task. The challenge is that we cannot compute the acquisition scores of all data exhaustively due to the size of the pool. We propose an efficient method, Seafaring, to retrieve informative data in terms of active learning from the Web using a user-side information retrieval algorithm. In the experiments, we use the online Flickr environment as the pool for active learning. This pool contains more than ten billion images and is several orders of magnitude larger than the existing pools in the literature for active learning. We confirm that our method performs better than existing approaches of using a small unlabelled pool.
Momentum Tracking: Momentum Acceleration for Decentralized Deep Learning on Heterogeneous Data
Sep 30, 2022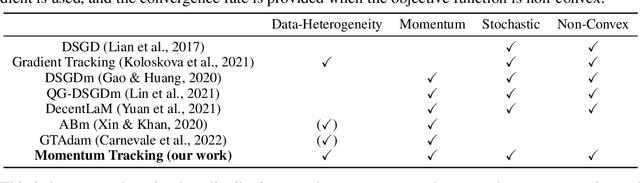
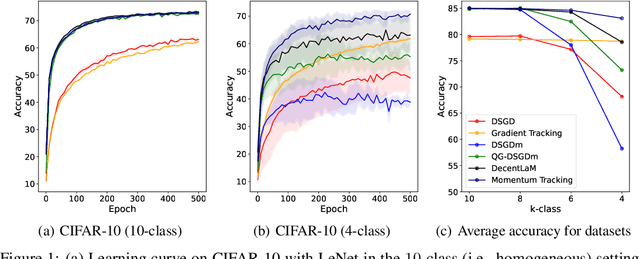
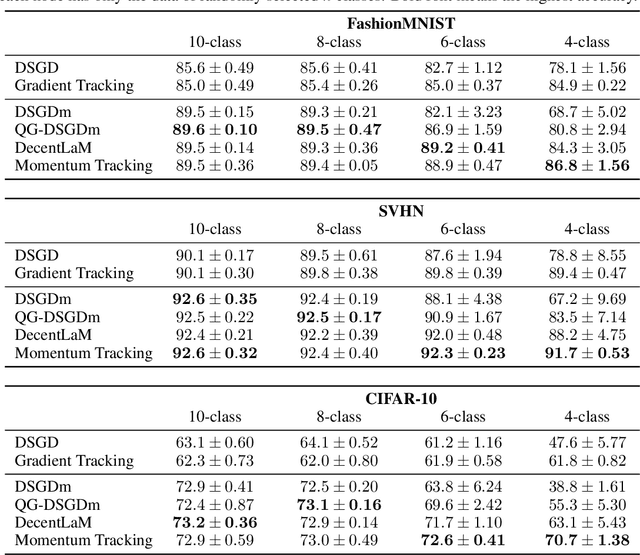
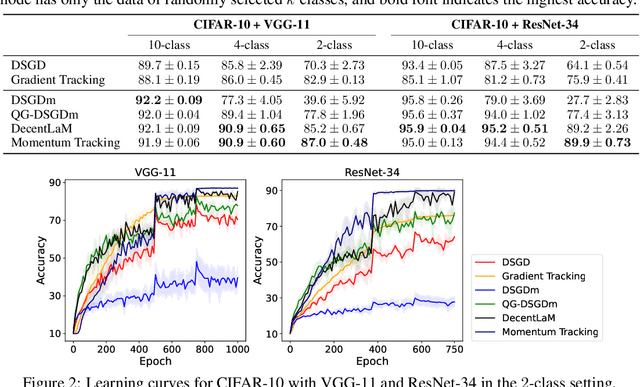
SGD with momentum acceleration is one of the key components for improving the performance of neural networks. For decentralized learning, a straightforward approach using momentum acceleration is Distributed SGD (DSGD) with momentum acceleration (DSGDm). However, DSGDm performs worse than DSGD when the data distributions are statistically heterogeneous. Recently, several studies have addressed this issue and proposed methods with momentum acceleration that are more robust to data heterogeneity than DSGDm, although their convergence rates remain dependent on data heterogeneity and decrease when the data distributions are heterogeneous. In this study, we propose Momentum Tracking, which is a method with momentum acceleration whose convergence rate is proven to be independent of data heterogeneity. More specifically, we analyze the convergence rate of Momentum Tracking in the standard deep learning setting, where the objective function is non-convex and the stochastic gradient is used. Then, we identify that it is independent of data heterogeneity for any momentum coefficient $\beta\in [0, 1)$. Through image classification tasks, we demonstrate that Momentum Tracking is more robust to data heterogeneity than the existing decentralized learning methods with momentum acceleration and can consistently outperform these existing methods when the data distributions are heterogeneous.
Towards Principled User-side Recommender Systems
Aug 21, 2022
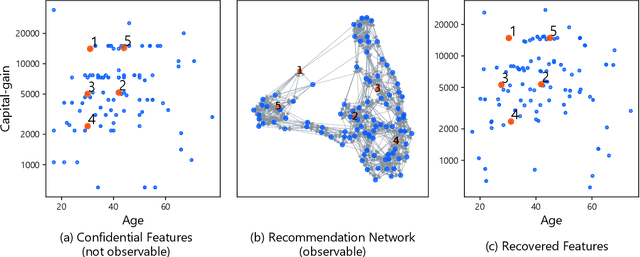


Traditionally, recommendation algorithms have been designed for service developers. However, recently, a new paradigm called user-side recommender systems has been proposed and they enable web service users to construct their own recommender systems without access to trade-secret data. This approach opens the door to user-defined fair systems even if the official recommender system of the service is not fair. While existing methods for user-side recommender systems have addressed the challenging problem of building recommender systems without using log data, they rely on heuristic approaches, and it is still unclear whether constructing user-side recommender systems is a well-defined problem from theoretical point of view. In this paper, we provide theoretical justification of user-side recommender systems. Specifically, we see that hidden item features can be recovered from the information available to the user, making the construction of user-side recommender system well-defined. However, this theoretically grounded approach is not efficient. To realize practical yet theoretically sound recommender systems, we propose three desirable properties of user-side recommender systems and propose an effective and efficient user-side recommender system, \textsc{Consul}, based on these foundations. We prove that \textsc{Consul} satisfies all three properties, whereas existing user-side recommender systems lack at least one of them. In the experiments, we empirically validate the theory of feature recovery via numerical experiments. We also show that our proposed method achieves an excellent trade-off between effectiveness and efficiency and demonstrate via case studies that the proposed method can retrieve information that the provider's official recommender system cannot.
Twin Papers: A Simple Framework of Causal Inference for Citations via Coupling
Aug 21, 2022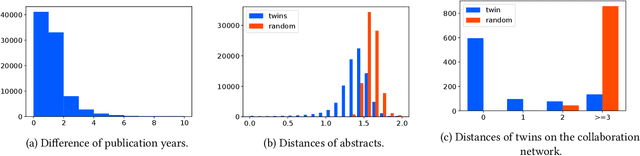

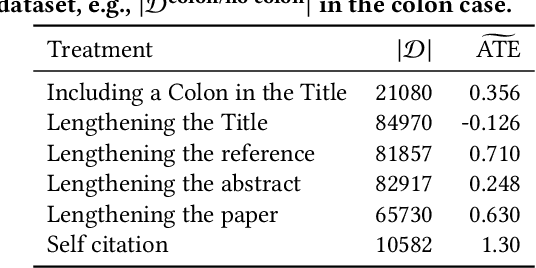

The research process includes many decisions, e.g., how to entitle and where to publish the paper. In this paper, we introduce a general framework for investigating the effects of such decisions. The main difficulty in investigating the effects is that we need to know counterfactual results, which are not available in reality. The key insight of our framework is inspired by the existing counterfactual analysis using twins, where the researchers regard twins as counterfactual units. The proposed framework regards a pair of papers that cite each other as twins. Such papers tend to be parallel works, on similar topics, and in similar communities. We investigate twin papers that adopted different decisions, observe the progress of the research impact brought by these studies, and estimate the effect of decisions by the difference in the impacts of these studies. We release our code and data, which we believe are highly beneficial owing to the scarcity of the dataset on counterfactual studies.
Approximating 1-Wasserstein Distance with Trees
Jun 24, 2022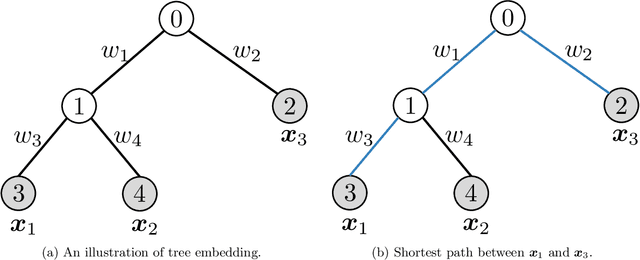
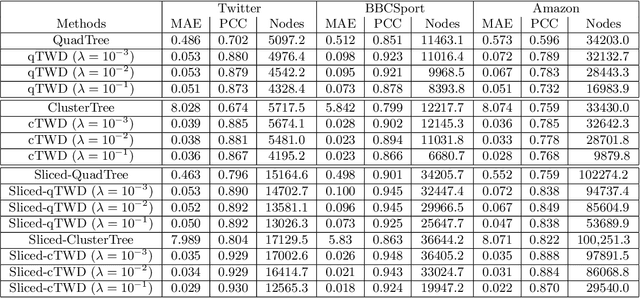
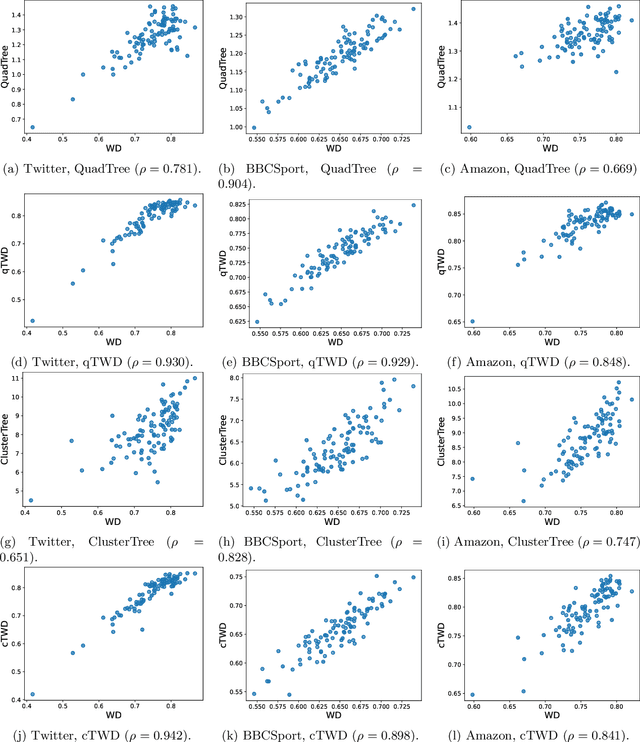
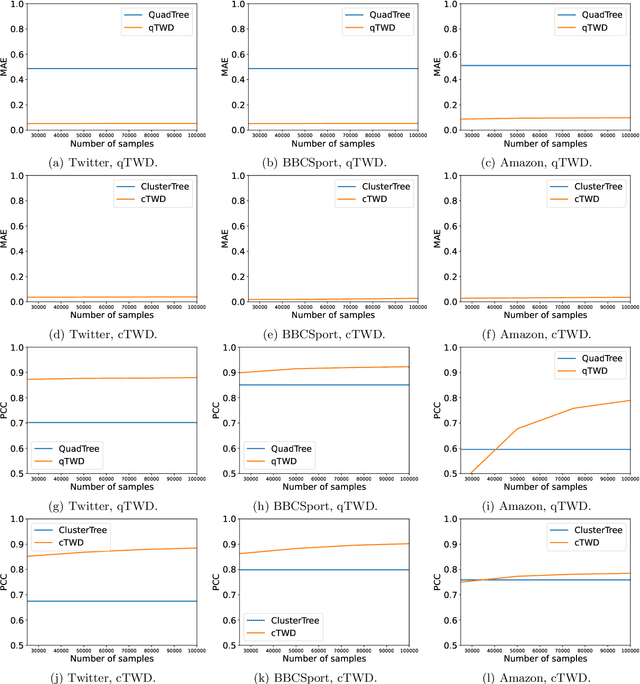
Wasserstein distance, which measures the discrepancy between distributions, shows efficacy in various types of natural language processing (NLP) and computer vision (CV) applications. One of the challenges in estimating Wasserstein distance is that it is computationally expensive and does not scale well for many distribution comparison tasks. In this paper, we aim to approximate the 1-Wasserstein distance by the tree-Wasserstein distance (TWD), where TWD is a 1-Wasserstein distance with tree-based embedding and can be computed in linear time with respect to the number of nodes on a tree. More specifically, we propose a simple yet efficient L1-regularized approach to learning the weights of the edges in a tree. To this end, we first show that the 1-Wasserstein approximation problem can be formulated as a distance approximation problem using the shortest path distance on a tree. We then show that the shortest path distance can be represented by a linear model and can be formulated as a Lasso-based regression problem. Owing to the convex formulation, we can obtain a globally optimal solution efficiently. Moreover, we propose a tree-sliced variant of these methods. Through experiments, we demonstrated that the weighted TWD can accurately approximate the original 1-Wasserstein distance.
CLEAR: A Fully User-side Image Search System
Jun 17, 2022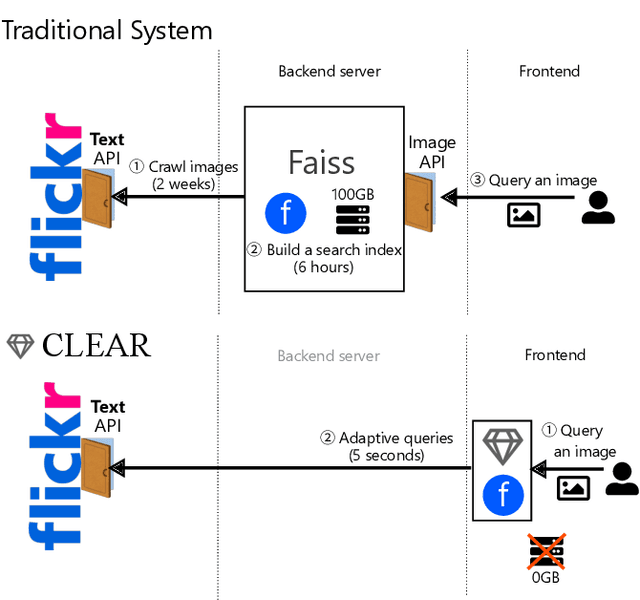
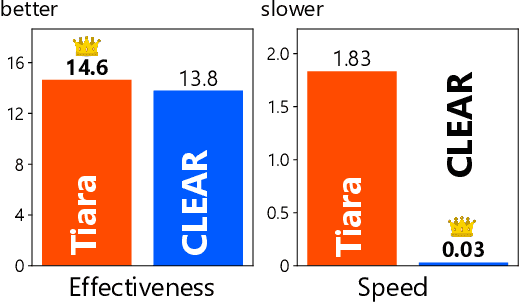
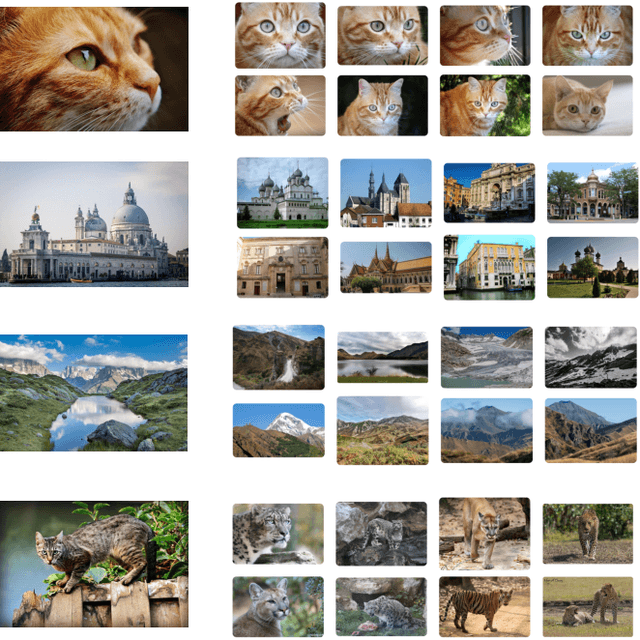
We use many search engines on the Internet in our daily lives. However, they are not perfect. Their scoring function may not model our intent or they may accept only text queries even though we want to carry out a similar image search. In such cases, we need to make a compromise: We continue to use the unsatisfactory service or leave the service. Recently, a new solution, user-side search systems, has been proposed. In this framework, each user builds their own search system that meets their preference with a user-defined scoring function and user-defined interface. Although the concept is appealing, it is still not clear if this approach is feasible in practice. In this demonstration, we show the first fully user-side image search system, CLEAR, which realizes a similar-image search engine for Flickr. The challenge is that Flickr does not provide an official similar image search engine or corresponding API. Nevertheless, CLEAR realizes it fully on a user-side. CLEAR does not use a backend server at all nor store any images or build search indices. It is in contrast to traditional search algorithms that require preparing a backend server and building a search index. Therefore, each user can easily deploy their own CLEAR engine, and the resulting service is custom-made and privacy-preserving. The online demo is available at https://clear.joisino.net. The source code is available at https://github.com/joisino/clear.