 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Query Refinement for Target Sound Extraction: Handling Partially Matched Queries
Sep 10, 2025



Target sound extraction (TSE) is the task of extracting a target sound specified by a query from an audio mixture. Much prior research has focused on the problem setting under the Fully Matched Query (FMQ) condition, where the query specifies only active sounds present in the mixture. However, in real-world scenarios, queries may include inactive sounds that are not present in the mixture. This leads to scenarios such as the Fully Unmatched Query (FUQ) condition, where only inactive sounds are specified in the query, and the Partially Matched Query (PMQ) condition, where both active and inactive sounds are specified. Among these conditions, the performance degradation under the PMQ condition has been largely overlooked. To achieve robust TSE under the PMQ condition, we propose context-aware query refinement. This method eliminates inactive classes from the query during inference based on the estimated sound class activity. Experimental results demonstrate that while conventional methods suffer from performance degradation under the PMQ condition, the proposed method effectively mitigates this degradation and achieves high robustness under diverse query conditions.
Advancing AI Audits for Enhanced AI Governance
Nov 26, 2023


As artificial intelligence (AI) is integrated into various services and systems in society, many companies and organizations have proposed AI principles, policies, and made the related commitments. Conversely, some have proposed the need for independent audits, arguing that the voluntary principles adopted by the developers and providers of AI services and systems insufficiently address risk. This policy recommendation summarizes the issues related to the auditing of AI services and systems and presents three recommendations for promoting AI auditing that contribute to sound AI governance. Recommendation1.Development of institutional design for AI audits. Recommendation2.Training human resources for AI audits. Recommendation3. Updating AI audits in accordance with technological progress. In this policy recommendation, AI is assumed to be that which recognizes and predicts data with the last chapter outlining how generative AI should be audited.
A Gradient Method for Multilevel Optimization
May 28, 2021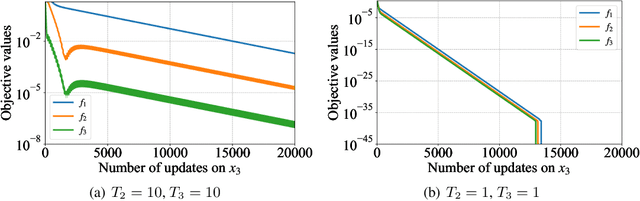
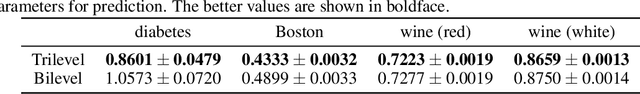
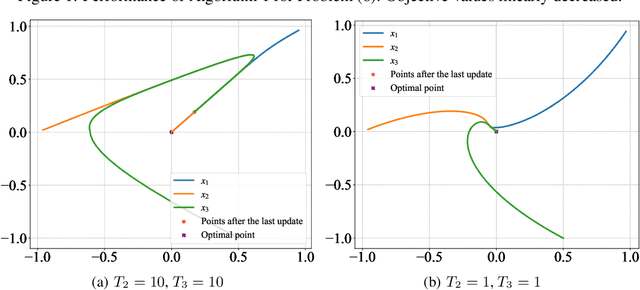
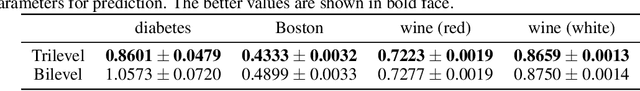
Although application examples of multilevel optimization have already been discussed since the '90s, the development of solution methods was almost limited to bilevel cases due to the difficulty of the problem. In recent years, in machine learning, Franceschi et al. have proposed a method for solving bilevel optimization problems by replacing their lower-level problems with the $T$ steepest descent update equations with some prechosen iteration number $T$. In this paper, we have developed a gradient-based algorithm for multilevel optimization with $n$ levels based on their idea and proved that our reformulation with $n T$ variables asymptotically converges to the original multilevel problem. As far as we know, this is one of the first algorithms with some theoretical guarantee for multilevel optimization. Numerical experiments show that a trilevel hyperparameter learning model considering data poisoning produces more stable prediction results than an existing bilevel hyperparameter learning model in noisy data settings.