 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStage-dependent integer-binary encoding in factorization-machine black-box optimization
Jun 22, 2026Black-box optimization (BBO) deals with problems where objective functions lack explicit analytical forms and are expensive to evaluate. Factorization machine with quadratic-optimization annealing (FMQA) constructs a surrogate model using a factorization machine (FM) and optimizes it with an Ising machine. Conventional FMQA applies a single integer-binary encoding throughout the optimization process, although the encoding best suited to surrogate learning may differ from the one best suited to Ising-machine solution search. We propose a stage-dependent FMQA framework and derive conversion formulas between one-hot and domain-wall QUBO matrices that preserve the surrogate objective over feasible integer states up to an additive constant. We evaluate the OhDw variant, which employs one-hot encoding for learning and domain-wall encoding for search, on the Rastrigin function with input dimensions N = 2 and 5 and discretization levels q = 61 and 301. Across all conditions, the dominant factor governing optimization performance is the encoding used in the learning stage, with one-hot encoding consistently yielding lower residual errors than domain-wall or binary encoding. The additional benefit of switching to domain-wall encoding for solution search is condition-dependent. For N = 5 and q = 301, OhDw achieves a lower residual error and solutions closer to the global optimum than one-hot-only FMQA, whereas for N = 5 and q = 61 the latter achieves a lower residual error. These results indicate that one-hot encoding in the learning stage is the primary performance driver and that stage-dependent encoding can provide further improvement under finer discretization.
Deep Learning of Superconductors I: Estimation of Critical Temperature of Superconductors Toward the Search for New Materials
Dec 03, 2018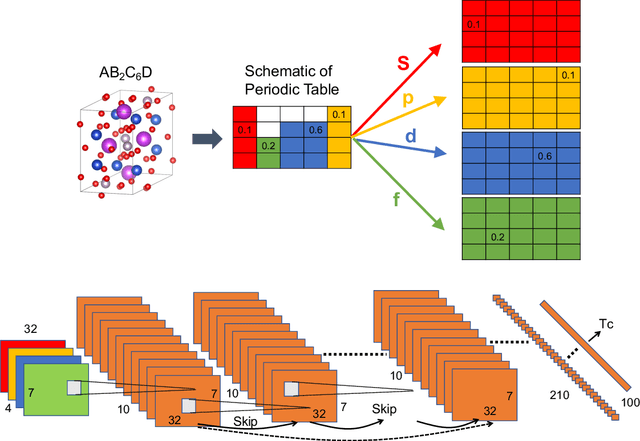
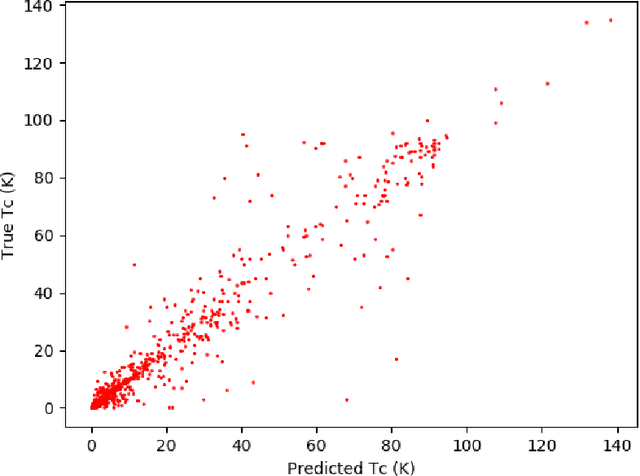
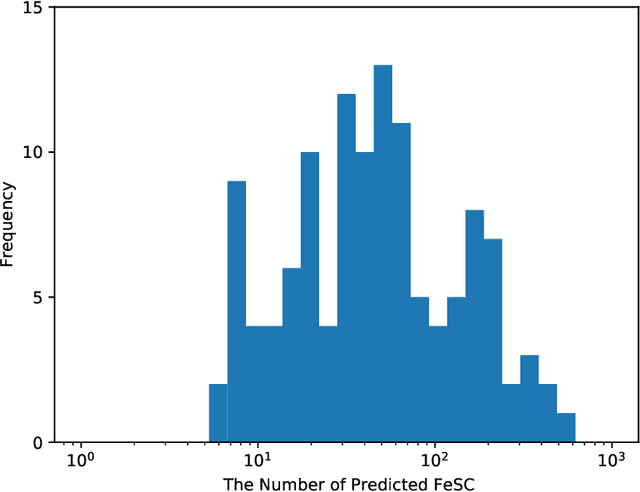
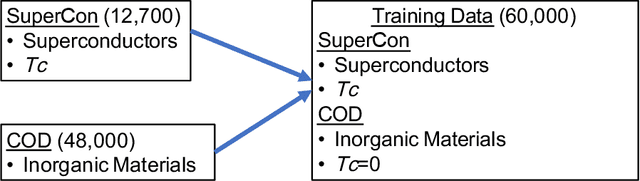
High-temperature superconductors have a lot of promising applications: quantum computers, high-performance classical computers, green energy, safe and high-speed transportation system, medical appliance, and etc. However, to discover new superconductors is very difficult. It is said that only $3\%$ of candidate materials become superconductors. We do not have satisfactory theory of high-temperature superconductors yet, and computational methods do not work either. On the other hand, the data has accumulated. Deep learning suits the situation. We introduce following two methods into deep learning: (1) in order to better represent material information and make good use of our scientific knowledge into deep learning, we introduce the input data form representing "material as image from periodic table with four channels corresponding to s, p, d, and f of electron orbit", (2) we introduce the method, named "garbage-in", to make use of the non-annotated data, which means the data of materials without any critical temperature $T_c$ in this case. We show that the critical temperature is well predicted by deep learning. In order to test the ability of the deep neural network it is good if we have the list of materials, which it is hard to tell whether they become superconductors or not from human expert in advance. We use the list made by Hosono's group as such. The test is to predict if a material becomes superconductor beyond $10$ Kelvin or not, and the neural network is trained by the data before the list was made. The neural network achieved accuracy $94\%$, precision $74\%$, recall $62\%$, and f1 score $67\%$. Compared to the baseline precision $9\%$, which is obtained from a positive prediction to randomly selected material, our deep learning has very good precision. We make a list of candidate materials of superconductors, and we are preparing for the experiments now.