 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsifying Suprema of Gaussian Processes
Nov 22, 2024We give a dimension-independent sparsification result for suprema of centered Gaussian processes: Let $T$ be any (possibly infinite) bounded set of vectors in $\mathbb{R}^n$, and let $\{{\boldsymbol{X}}_t\}_{t\in T}$ be the canonical Gaussian process on $T$. We show that there is an $O_\varepsilon(1)$-size subset $S \subseteq T$ and a set of real values $\{c_s\}_{s \in S}$ such that $\sup_{s \in S} \{{\boldsymbol{X}}_s + c_s\}$ is an $\varepsilon$-approximator of $\sup_{t \in T} {\boldsymbol{X}}_t$. Notably, the size of $S$ is completely independent of both the size of $T$ and of the ambient dimension $n$. We use this to show that every norm is essentially a junta when viewed as a function over Gaussian space: Given any norm $\nu(x)$ on $\mathbb{R}^n$, there is another norm $\psi(x)$ which depends only on the projection of $x$ along $O_\varepsilon(1)$ directions, for which $\psi({\boldsymbol{g}})$ is a multiplicative $(1 \pm \varepsilon)$-approximation of $\nu({\boldsymbol{g}})$ with probability $1-\varepsilon$ for ${\boldsymbol{g}} \sim N(0,I_n)$. We also use our sparsification result for suprema of centered Gaussian processes to give a sparsification lemma for convex sets of bounded geometric width: Any intersection of (possibly infinitely many) halfspaces in $\mathbb{R}^n$ that are at distance $O(1)$ from the origin is $\varepsilon$-close, under $N(0,I_n)$, to an intersection of only $O_\varepsilon(1)$ many halfspaces. We describe applications to agnostic learning and tolerant property testing.
Toward Instance-Optimal State Certification With Incoherent Measurements
Feb 25, 2021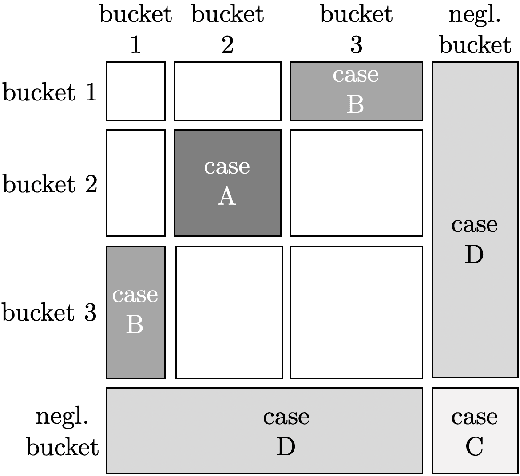
We revisit the basic problem of quantum state certification: given copies of unknown mixed state $\rho\in\mathbb{C}^{d\times d}$ and the description of a mixed state $\sigma$, decide whether $\sigma = \rho$ or $\|\sigma - \rho\|_{\mathsf{tr}} \ge \epsilon$. When $\sigma$ is maximally mixed, this is mixedness testing, and it is known that $\Omega(d^{\Theta(1)}/\epsilon^2)$ copies are necessary, where the exact exponent depends on the type of measurements the learner can make [OW15, BCL20], and in many of these settings there is a matching upper bound [OW15, BOW19, BCL20]. Can one avoid this $d^{\Theta(1)}$ dependence for certain kinds of mixed states $\sigma$, e.g. ones which are approximately low rank? More ambitiously, does there exist a simple functional $f:\mathbb{C}^{d\times d}\to\mathbb{R}_{\ge 0}$ for which one can show that $\Theta(f(\sigma)/\epsilon^2)$ copies are necessary and sufficient for state certification with respect to any $\sigma$? Such instance-optimal bounds are known in the context of classical distribution testing, e.g. [VV17]. Here we give the first bounds of this nature for the quantum setting, showing (up to log factors) that the copy complexity for state certification using nonadaptive incoherent measurements is essentially given by the copy complexity for mixedness testing times the fidelity between $\sigma$ and the maximally mixed state. Surprisingly, our bound differs substantially from instance optimal bounds for the classical problem, demonstrating a qualitative difference between the two settings.
Learning sparse mixtures of rankings from noisy information
Nov 03, 2018


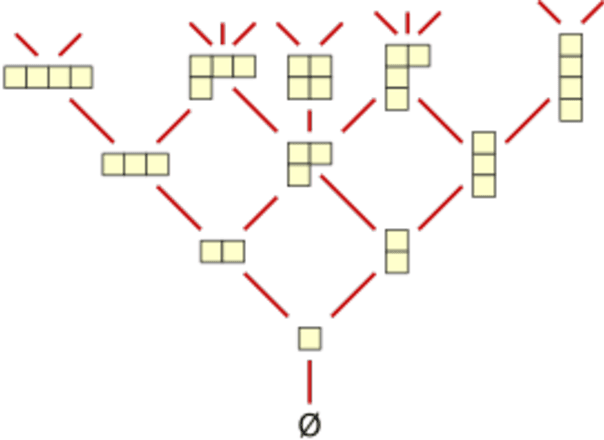
We study the problem of learning an unknown mixture of $k$ rankings over $n$ elements, given access to noisy samples drawn from the unknown mixture. We consider a range of different noise models, including natural variants of the "heat kernel" noise framework and the Mallows model. For each of these noise models we give an algorithm which, under mild assumptions, learns the unknown mixture to high accuracy and runs in $n^{O(\log k)}$ time. The best previous algorithms for closely related problems have running times which are exponential in $k$.
Sharp bounds for population recovery
Mar 04, 2017The population recovery problem is a basic problem in noisy unsupervised learning that has attracted significant research attention in recent years [WY12,DRWY12, MS13, BIMP13, LZ15,DST16]. A number of different variants of this problem have been studied, often under assumptions on the unknown distribution (such as that it has restricted support size). In this work we study the sample complexity and algorithmic complexity of the most general version of the problem, under both bit-flip noise and erasure noise model. We give essentially matching upper and lower sample complexity bounds for both noise models, and efficient algorithms matching these sample complexity bounds up to polynomial factors.
Optimal mean-based algorithms for trace reconstruction
Dec 09, 2016In the (deletion-channel) trace reconstruction problem, there is an unknown $n$-bit source string $x$. An algorithm is given access to independent traces of $x$, where a trace is formed by deleting each bit of~$x$ independently with probability~$\delta$. The goal of the algorithm is to recover~$x$ exactly (with high probability), while minimizing samples (number of traces) and running time. Previously, the best known algorithm for the trace reconstruction problem was due to Holenstein~et~al.; it uses $\exp(\tilde{O}(n^{1/2}))$ samples and running time for any fixed $0 < \delta < 1$. It is also what we call a "mean-based algorithm", meaning that it only uses the empirical means of the individual bits of the traces. Holenstein~et~al.~also gave a lower bound, showing that any mean-based algorithm must use at least $n^{\tilde{\Omega}(\log n)}$ samples. In this paper we improve both of these results, obtaining matching upper and lower bounds for mean-based trace reconstruction. For any constant deletion rate $0 < \delta < 1$, we give a mean-based algorithm that uses $\exp(O(n^{1/3}))$ time and traces; we also prove that any mean-based algorithm must use at least $\exp(\Omega(n^{1/3}))$ traces. In fact, we obtain matching upper and lower bounds even for $\delta$ subconstant and $\rho := 1-\delta$ subconstant: when $(\log^3 n)/n \ll \delta \leq 1/2$ the bound is $\exp(-\Theta(\delta n)^{1/3})$, and when $1/\sqrt{n} \ll \rho \leq 1/2$ the bound is $\exp(-\Theta(n/\rho)^{1/3})$. Our proofs involve estimates for the maxima of Littlewood polynomials on complex disks. We show that these techniques can also be used to perform trace reconstruction with random insertions and bit-flips in addition to deletions. We also find a surprising result: for deletion probabilities $\delta > 1/2$, the presence of insertions can actually help with trace reconstruction.
Hardness Results for Agnostically Learning Low-Degree Polynomial Threshold Functions
Oct 18, 2010Hardness results for maximum agreement problems have close connections to hardness results for proper learning in computational learning theory. In this paper we prove two hardness results for the problem of finding a low degree polynomial threshold function (PTF) which has the maximum possible agreement with a given set of labeled examples in $\R^n \times \{-1,1\}.$ We prove that for any constants $d\geq 1, \eps > 0$, {itemize} Assuming the Unique Games Conjecture, no polynomial-time algorithm can find a degree-$d$ PTF that is consistent with a $(\half + \eps)$ fraction of a given set of labeled examples in $\R^n \times \{-1,1\}$, even if there exists a degree-$d$ PTF that is consistent with a $1-\eps$ fraction of the examples. It is $\NP$-hard to find a degree-2 PTF that is consistent with a $(\half + \eps)$ fraction of a given set of labeled examples in $\R^n \times \{-1,1\}$, even if there exists a halfspace (degree-1 PTF) that is consistent with a $1 - \eps$ fraction of the examples. {itemize} These results immediately imply the following hardness of learning results: (i) Assuming the Unique Games Conjecture, there is no better-than-trivial proper learning algorithm that agnostically learns degree-$d$ PTFs under arbitrary distributions; (ii) There is no better-than-trivial learning algorithm that outputs degree-2 PTFs and agnostically learns halfspaces (i.e. degree-1 PTFs) under arbitrary distributions.
PAC Learning Mixtures of Axis-Aligned Gaussians with No Separation Assumption
Sep 16, 2006We propose and analyze a new vantage point for the learning of mixtures of Gaussians: namely, the PAC-style model of learning probability distributions introduced by Kearns et al. Here the task is to construct a hypothesis mixture of Gaussians that is statistically indistinguishable from the actual mixture generating the data; specifically, the KL-divergence should be at most epsilon. In this scenario, we give a poly(n/epsilon)-time algorithm that learns the class of mixtures of any constant number of axis-aligned Gaussians in n-dimensional Euclidean space. Our algorithm makes no assumptions about the separation between the means of the Gaussians, nor does it have any dependence on the minimum mixing weight. This is in contrast to learning results known in the ``clustering'' model, where such assumptions are unavoidable. Our algorithm relies on the method of moments, and a subalgorithm developed in previous work by the authors (FOCS 2005) for a discrete mixture-learning problem.
* 19 pages; no figures; preliminary abridged version appeared in Proceedings of 19th Annual Conference on Learning Theory (COLT) 2006