 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-FedTomAtt: Ultra-lightweight Federated Learning with Attention for Tomato Disease Recognition
Feb 18, 2026Federated learning has emerged as a privacy-preserving and efficient approach for deploying intelligent agricultural solutions. Accurate edge-based diagnosis across geographically dispersed farms is crucial for recognising tomato diseases in sustainable farming. Traditional centralised training aggregates raw data on a central server, leading to communication overhead, privacy risks and latency. Meanwhile, edge devices require lightweight networks to operate effectively within limited resources. In this paper, we propose U-FedTomAtt, an ultra-lightweight federated learning framework with attention for tomato disease recognition in resource-constrained and distributed environments. The model comprises only 245.34K parameters and 71.41 MFLOPS. First, we propose an ultra-lightweight neural network with dilated bottleneck (DBNeck) modules and a linear transformer to minimise computational and memory overhead. To mitigate potential accuracy loss, a novel local-global residual attention (LoGRA) module is incorporated. Second, we propose the federated dual adaptive weight aggregation (FedDAWA) algorithm that enhances global model accuracy. Third, our framework is validated using three benchmark datasets for tomato diseases under simulated federated settings. Experimental results show that the proposed method achieves 0.9910% and 0.9915% Top-1 accuracy and 0.9923% and 0.9897% F1-scores on SLIF-Tomato and PlantVillage tomato datasets, respectively.
Plagiarism Detection on Electronic Text based Assignments using Vector Space Model (ICIAfS14)
Dec 25, 2014


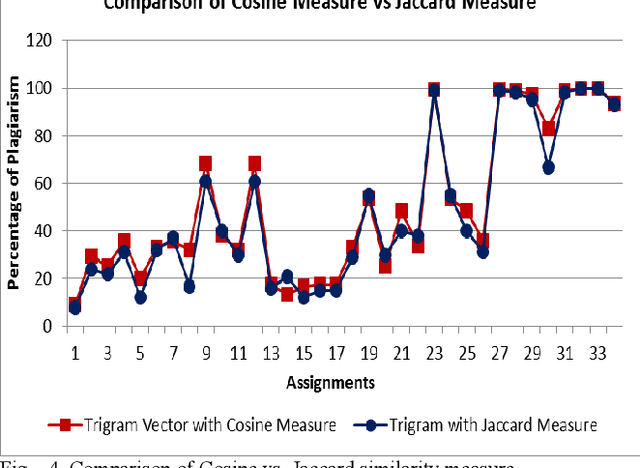
Plagiarism is known as illegal use of others' part of work or whole work as one's own in any field such as art, poetry, literature, cinema, research and other creative forms of study. Plagiarism is one of the important issues in academic and research fields and giving more concern in academic systems. The situation is even worse with the availability of ample resources on the web. This paper focuses on an effective plagiarism detection tool on identifying suitable intra-corpal plagiarism detection for text based assignments by comparing unigram, bigram, trigram of vector space model with cosine similarity measure. Manually evaluated, labelled dataset was tested using unigram, bigram and trigram vector. Even though trigram vector consumes comparatively more time, it shows better results with the labelled data. In addition, the selected trigram vector space model with cosine similarity measure is compared with tri-gram sequence matching technique with Jaccard measure. In the results, cosine similarity score shows slightly higher values than the other. Because, it focuses on giving more weight for terms that do not frequently exist in the dataset and cosine similarity measure using trigram technique is more preferable than the other. Therefore, we present our new tool and it could be used as an effective tool to evaluate text based electronic assignments and minimize the plagiarism among students.