 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShortcut Learning in Binary Classifier Black Boxes: Applications to Voice Anti-Spoofing and Biometrics
Jan 25, 2026The widespread adoption of deep-learning models in data-driven applications has drawn attention to the potential risks associated with biased datasets and models. Neglected or hidden biases within datasets and models can lead to unexpected results. This study addresses the challenges of dataset bias and explores ``shortcut learning'' or ``Clever Hans effect'' in binary classifiers. We propose a novel framework for analyzing the black-box classifiers and for examining the impact of both training and test data on classifier scores. Our framework incorporates intervention and observational perspectives, employing a linear mixed-effects model for post-hoc analysis. By evaluating classifier performance beyond error rates, we aim to provide insights into biased datasets and offer a comprehensive understanding of their influence on classifier behavior. The effectiveness of our approach is demonstrated through experiments on audio anti-spoofing and speaker verification tasks using both statistical models and deep neural networks. The insights gained from this study have broader implications for tackling biases in other domains and advancing the field of explainable artificial intelligence.
Gamified Speaker Comparison by Listening
May 10, 2022

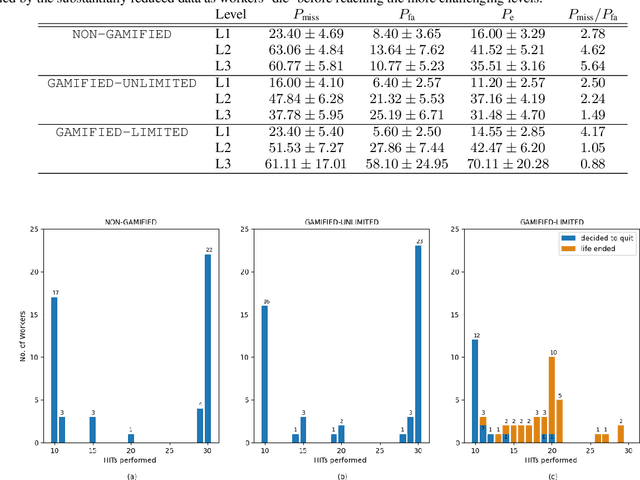
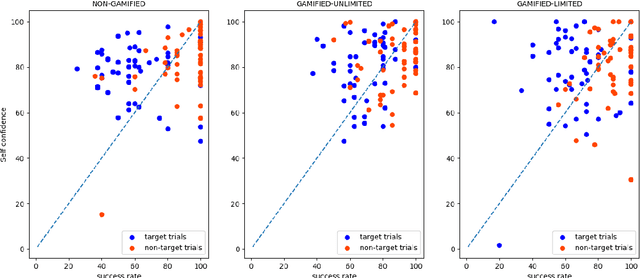
We address speaker comparison by listening in a game-like environment, hypothesized to make the task more motivating for naive listeners. We present the same 30 trials selected with the help of an x-vector speaker recognition system from VoxCeleb to a total of 150 crowdworkers recruited through Amazon's Mechanical Turk. They are divided into cohorts of 50, each using one of three alternative interface designs: (i) a traditional (nongamified) design; (ii) a gamified design with feedback on decisions, along with points, game level indications, and possibility for interface customization; (iii) another gamified design with an additional constraint of maximum of 5 'lives' consumed by wrong answers. We analyze the impact of these interface designs to listener error rates (both misses and false alarms), probability calibration, time of quitting, along with survey questionnaire. The results indicate improved performance from (i) to (ii) and (iii), particularly in terms of balancing the two types of detection errors.