 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOD: A Deep Mixture Model with Online Knowledge Distillation for Large Scale Video Temporal Concept Localization
Oct 27, 2019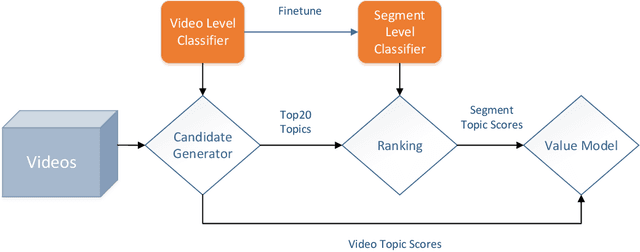


In this paper, we present and discuss a deep mixture model with online knowledge distillation (MOD) for large-scale video temporal concept localization, which is ranked 3rd in the 3rd YouTube-8M Video Understanding Challenge. Specifically, we find that by enabling knowledge sharing with online distillation, fintuning a mixture model on a smaller dataset can achieve better evaluation performance. Based on this observation, in our final solution, we trained and fintuned 12 NeXtVLAD models in parallel with a 2-layer online distillation structure. The experimental results show that the proposed distillation structure can effectively avoid overfitting and shows superior generalization performance. The code is publicly available at: https://github.com/linrongc/solution_youtube8m_v3
* ICCV 2019 YouTube8M workshop
NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification
Nov 12, 2018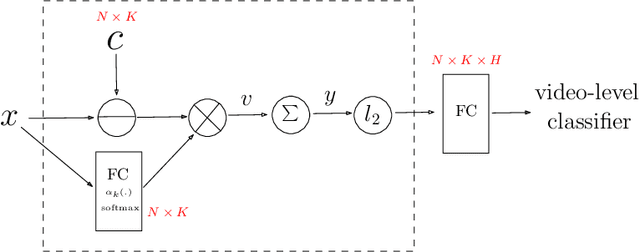
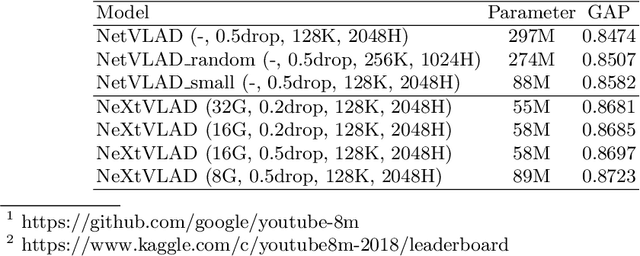
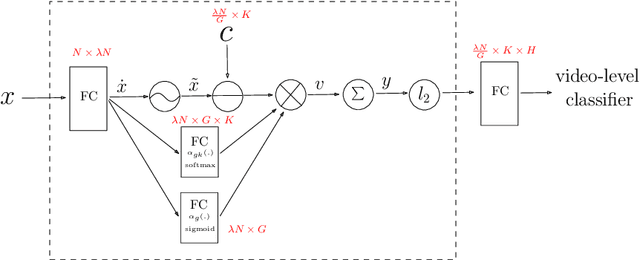
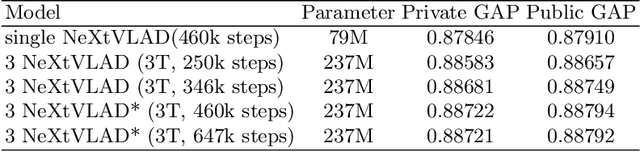
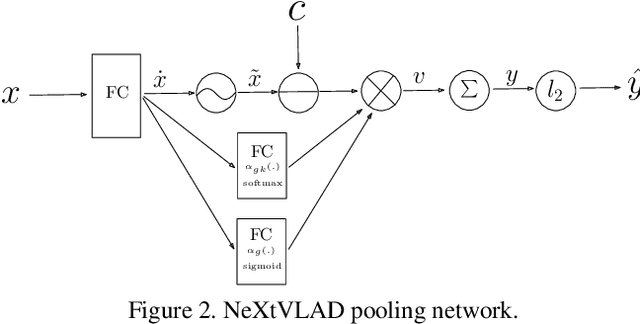
This paper introduces a fast and efficient network architecture, NeXtVLAD, to aggregate frame-level features into a compact feature vector for large-scale video classification. Briefly speaking, the basic idea is to decompose a high-dimensional feature into a group of relatively low-dimensional vectors with attention before applying NetVLAD aggregation over time. This NeXtVLAD approach turns out to be both effective and parameter efficient in aggregating temporal information. In the 2nd Youtube-8M video understanding challenge, a single NeXtVLAD model with less than 80M parameters achieves a GAP score of 0.87846 in private leaderboard. A mixture of 3 NeXtVLAD models results in 0.88722, which is ranked 3rd over 394 teams. The code is publicly available at https://github.com/linrongc/youtube-8m.