 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Perspective on the Origin of Facial Expressions
May 10, 2017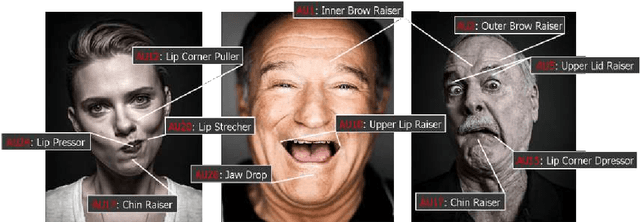


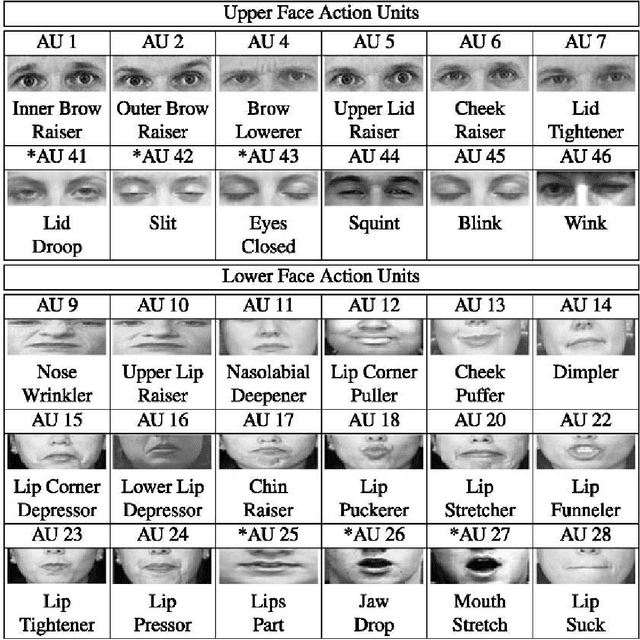
Facial expressions play a significant role in human communication and behavior. Psychologists have long studied the relationship between facial expressions and emotions. Paul Ekman et al., devised the Facial Action Coding System (FACS) to taxonomize human facial expressions and model their behavior. The ability to recognize facial expressions automatically, enables novel applications in fields like human-computer interaction, social gaming, and psychological research. There has been a tremendously active research in this field, with several recent papers utilizing convolutional neural networks (CNN) for feature extraction and inference. In this paper, we employ CNN understanding methods to study the relation between the features these computational networks are using, the FACS and Action Units (AU). We verify our findings on the Extended Cohn-Kanade (CK+), NovaEmotions and FER2013 datasets. We apply these models to various tasks and tests using transfer learning, including cross-dataset validation and cross-task performance. Finally, we exploit the nature of the FER based CNN models for the detection of micro-expressions and achieve state-of-the-art accuracy using a simple long-short-term-memory (LSTM) recurrent neural network (RNN).
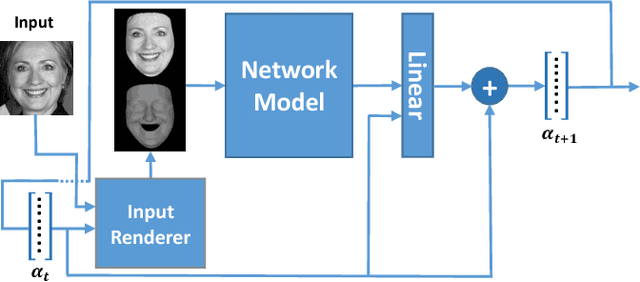
Learning Detailed Face Reconstruction from a Single Image
Apr 06, 2017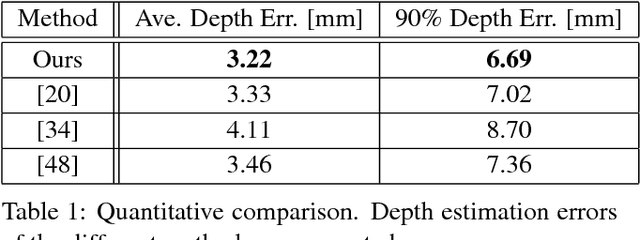

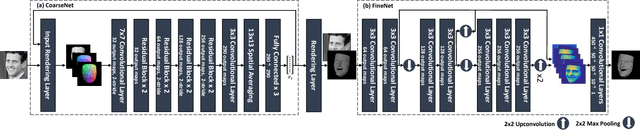

Reconstructing the detailed geometric structure of a face from a given image is a key to many computer vision and graphics applications, such as motion capture and reenactment. The reconstruction task is challenging as human faces vary extensively when considering expressions, poses, textures, and intrinsic geometries. While many approaches tackle this complexity by using additional data to reconstruct the face of a single subject, extracting facial surface from a single image remains a difficult problem. As a result, single-image based methods can usually provide only a rough estimate of the facial geometry. In contrast, we propose to leverage the power of convolutional neural networks to produce a highly detailed face reconstruction from a single image. For this purpose, we introduce an end-to-end CNN framework which derives the shape in a coarse-to-fine fashion. The proposed architecture is composed of two main blocks, a network that recovers the coarse facial geometry (CoarseNet), followed by a CNN that refines the facial features of that geometry (FineNet). The proposed networks are connected by a novel layer which renders a depth image given a mesh in 3D. Unlike object recognition and detection problems, there are no suitable datasets for training CNNs to perform face geometry reconstruction. Therefore, our training regime begins with a supervised phase, based on synthetic images, followed by an unsupervised phase that uses only unconstrained facial images. The accuracy and robustness of the proposed model is demonstrated by both qualitative and quantitative evaluation tests.
Learning Invariant Representations Of Planar Curves
Feb 16, 2017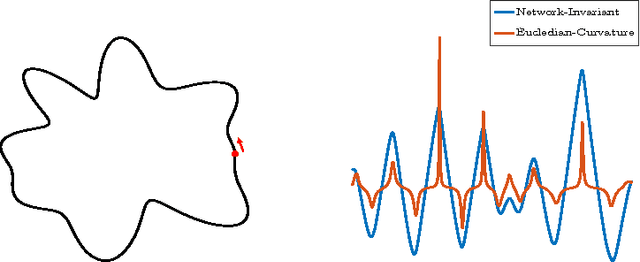
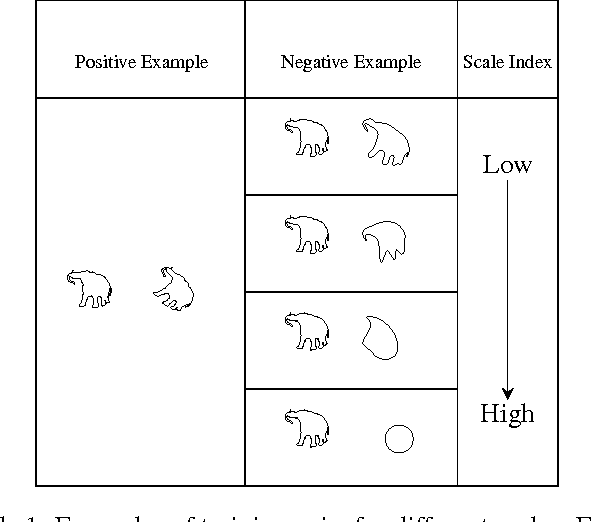
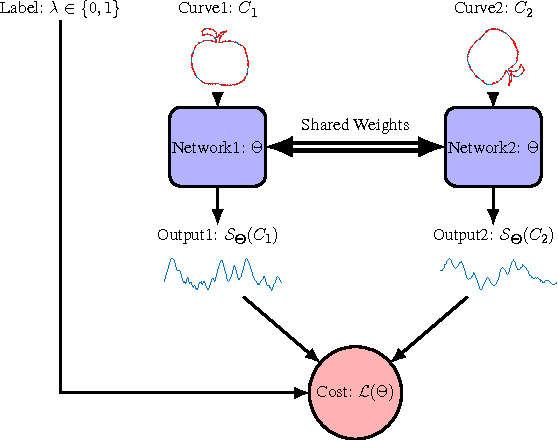
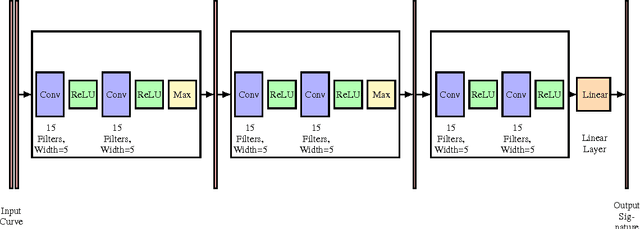
We propose a metric learning framework for the construction of invariant geometric functions of planar curves for the Eucledian and Similarity group of transformations. We leverage on the representational power of convolutional neural networks to compute these geometric quantities. In comparison with axiomatic constructions, we show that the invariants approximated by the learning architectures have better numerical qualities such as robustness to noise, resiliency to sampling, as well as the ability to adapt to occlusion and partiality. Finally, we develop a novel multi-scale representation in a similarity metric learning paradigm.
Deep Stereo Matching with Dense CRF Priors
Jan 24, 2017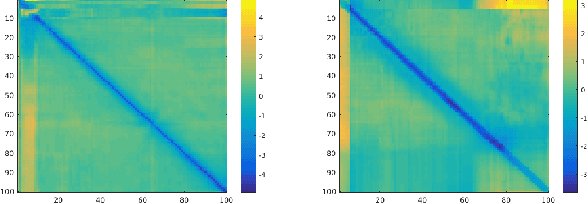
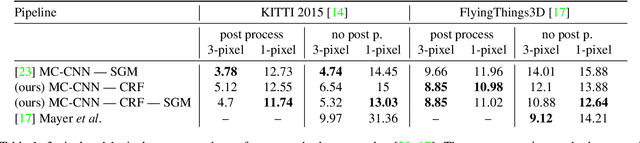
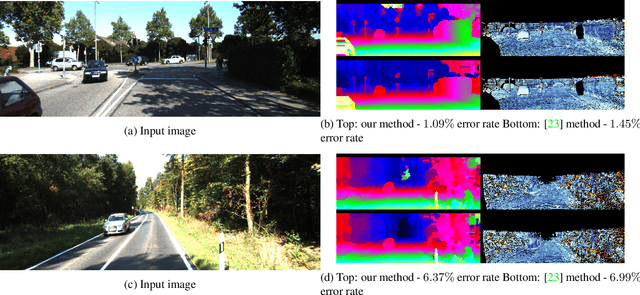
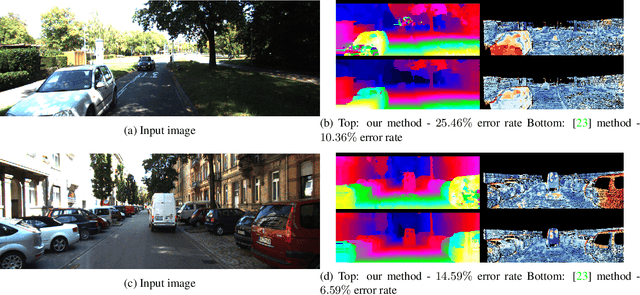
Stereo reconstruction from rectified images has recently been revisited within the context of deep learning. Using a deep Convolutional Neural Network to obtain patch-wise matching cost volumes has resulted in state of the art stereo reconstruction on classic datasets like Middlebury and Kitti. By introducing this cost into a classical stereo pipeline, the final results are improved dramatically over non-learning based cost models. However these pipelines typically include hand engineered post processing steps to effectively regularize and clean the result. Here, we show that it is possible to take a more holistic approach by training a fully end-to-end network which directly includes regularization in the form of a densely connected Conditional Random Field (CRF) that acts as a prior on inter-pixel interactions. We demonstrate that our approach on both synthetic and real world datasets outperforms an alternative end-to-end network and compares favorably to more hand engineered approaches.
3D Face Reconstruction by Learning from Synthetic Data
Sep 26, 2016


Fast and robust three-dimensional reconstruction of facial geometric structure from a single image is a challenging task with numerous applications. Here, we introduce a learning-based approach for reconstructing a three-dimensional face from a single image. Recent face recovery methods rely on accurate localization of key characteristic points. In contrast, the proposed approach is based on a Convolutional-Neural-Network (CNN) which extracts the face geometry directly from its image. Although such deep architectures outperform other models in complex computer vision problems, training them properly requires a large dataset of annotated examples. In the case of three-dimensional faces, currently, there are no large volume data sets, while acquiring such big-data is a tedious task. As an alternative, we propose to generate random, yet nearly photo-realistic, facial images for which the geometric form is known. The suggested model successfully recovers facial shapes from real images, even for faces with extreme expressions and under various lighting conditions.
Customized Facial Constant Positive Air Pressure (CPAP) Masks
Sep 22, 2016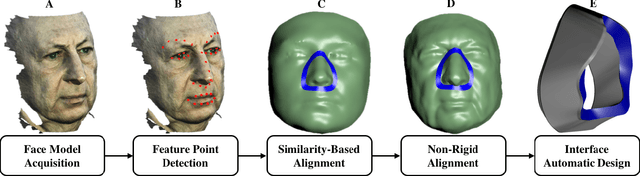
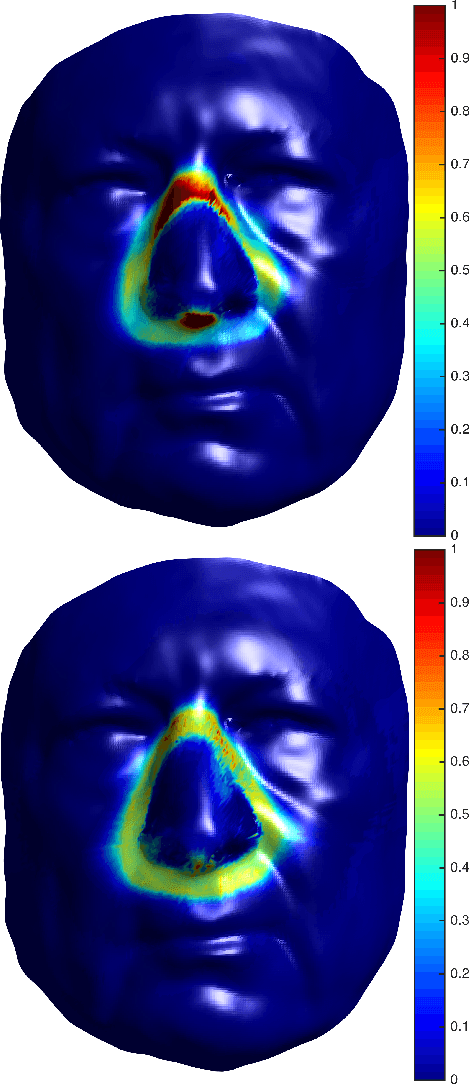
Sleep apnea is a syndrome that is characterized by sudden breathing halts while sleeping. One of the common treatments involves wearing a mask that delivers continuous air flow into the nostrils so as to maintain a steady air pressure. These masks are designed for an average facial model and are often difficult to adjust due to poor fit to the actual patient. The incompatibility is characterized by gaps between the mask and the face, which deteriorates the impermeability of the mask and leads to air leakage. We suggest a fully automatic approach for designing a personalized nasal mask interface using a facial depth scan. The interfaces generated by the proposed method accurately fit the geometry of the scanned face, and are easy to manufacture. The proposed method utilizes cheap commodity depth sensors and 3D printing technologies to efficiently design and manufacture customized masks for patients suffering from sleep apnea.
Randomized Independent Component Analysis
Sep 22, 2016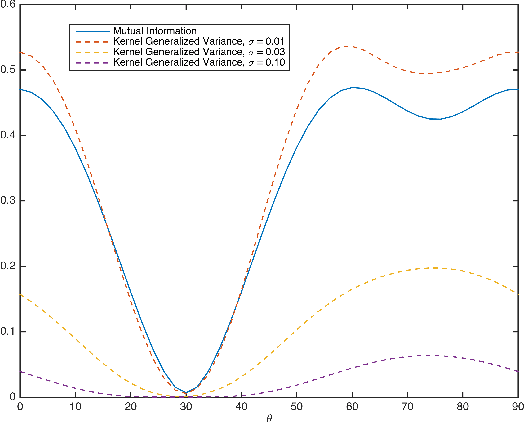
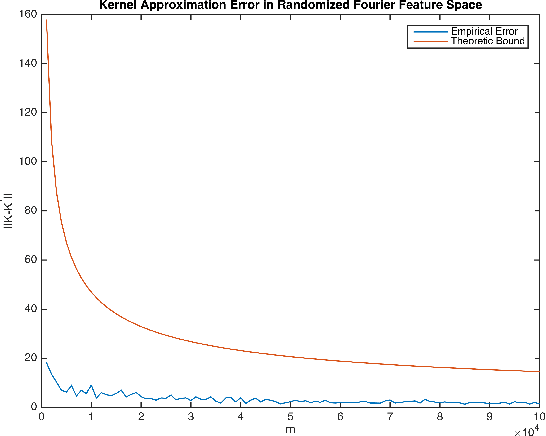
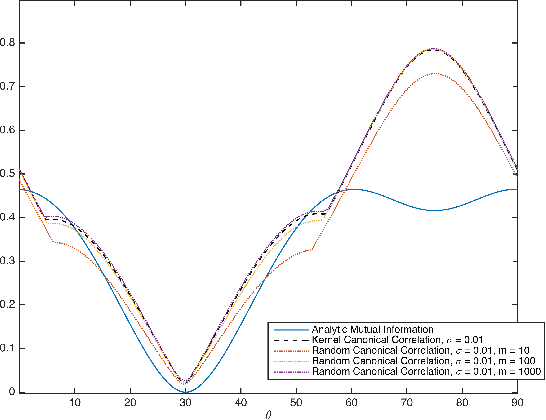
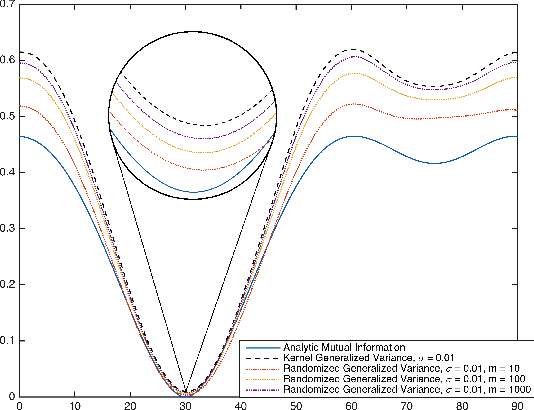
Independent component analysis (ICA) is a method for recovering statistically independent signals from observations of unknown linear combinations of the sources. Some of the most accurate ICA decomposition methods require searching for the inverse transformation which minimizes different approximations of the Mutual Information, a measure of statistical independence of random vectors. Two such approximations are the Kernel Generalized Variance or the Kernel Canonical Correlation which has been shown to reach the highest performance of ICA methods. However, the computational effort necessary just for computing these measures is cubic in the sample size. Hence, optimizing them becomes even more computationally demanding, in terms of both space and time. Here, we propose a couple of alternative novel measures based on randomized features of the samples - the Randomized Generalized Variance and the Randomized Canonical Correlation. The computational complexity of calculating the proposed alternatives is linear in the sample size and provide a controllable approximation of their Kernel-based non-random versions. We also show that optimization of the proposed statistical properties yields a comparable separation error at an order of magnitude faster compared to Kernel-based measures.
Consistent Discretization and Minimization of the L1 Norm on Manifolds
Sep 18, 2016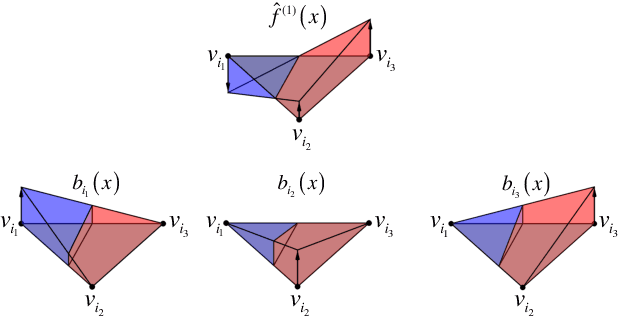
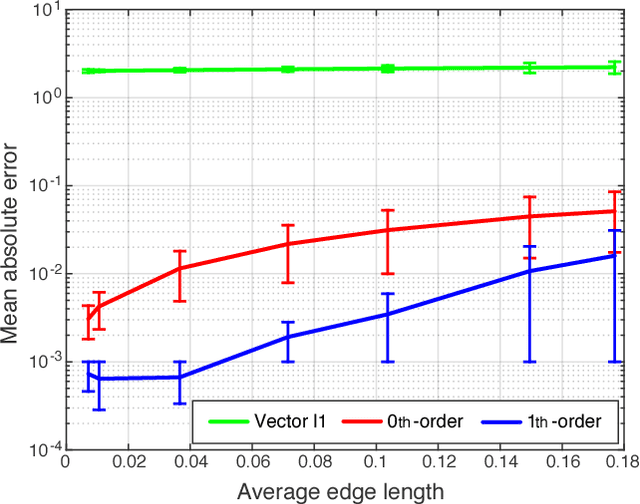
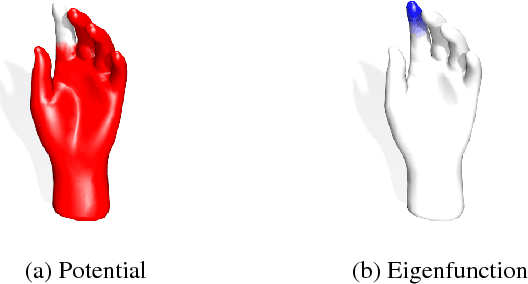
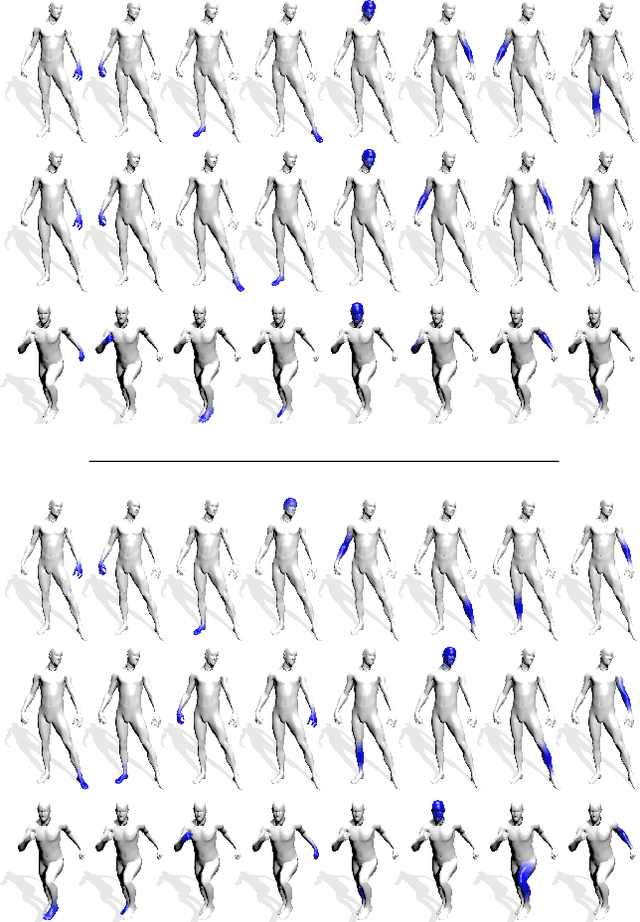
The L1 norm has been tremendously popular in signal and image processing in the past two decades due to its sparsity-promoting properties. More recently, its generalization to non-Euclidean domains has been found useful in shape analysis applications. For example, in conjunction with the minimization of the Dirichlet energy, it was shown to produce a compactly supported quasi-harmonic orthonormal basis, dubbed as compressed manifold modes. The continuous L1 norm on the manifold is often replaced by the vector l1 norm applied to sampled functions. We show that such an approach is incorrect in the sense that it does not consistently discretize the continuous norm and warn against its sensitivity to the specific sampling. We propose two alternative discretizations resulting in an iteratively-reweighed l2 norm. We demonstrate the proposed strategy on the compressed modes problem, which reduces to a sequence of simple eigendecomposition problems not requiring non-convex optimization on Stiefel manifolds and producing more stable and accurate results.
Real-Time Depth Refinement for Specular Objects
Mar 30, 2016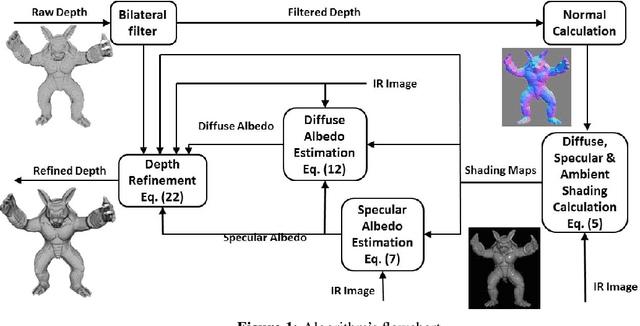
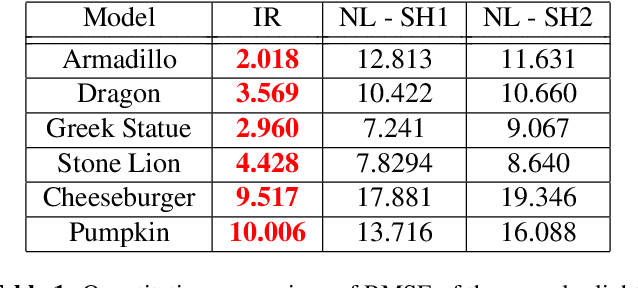
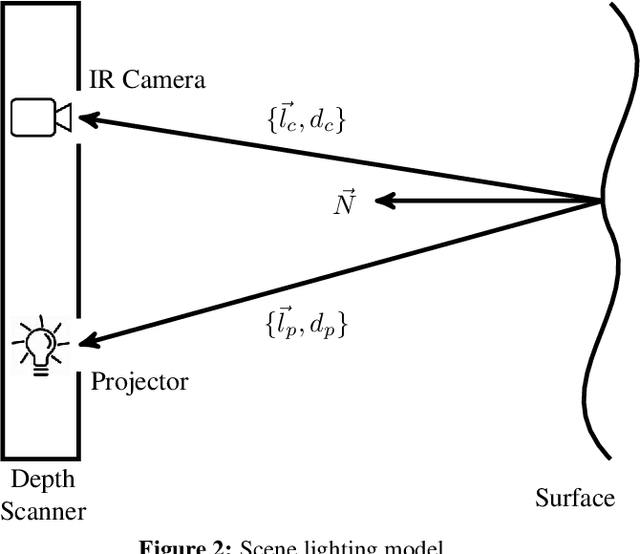
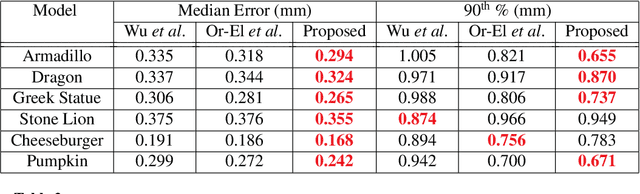
The introduction of consumer RGB-D scanners set off a major boost in 3D computer vision research. Yet, the precision of existing depth scanners is not accurate enough to recover fine details of a scanned object. While modern shading based depth refinement methods have been proven to work well with Lambertian objects, they break down in the presence of specularities. We present a novel shape from shading framework that addresses this issue and enhances both diffuse and specular objects' depth profiles. We take advantage of the built-in monochromatic IR projector and IR images of the RGB-D scanners and present a lighting model that accounts for the specular regions in the input image. Using this model, we reconstruct the depth map in real-time. Both quantitative tests and visual evaluations prove that the proposed method produces state of the art depth reconstruction results.
Rule Of Thumb: Deep derotation for improved fingertip detection
Jul 21, 2015

We investigate a novel global orientation regression approach for articulated objects using a deep convolutional neural network. This is integrated with an in-plane image derotation scheme, DeROT, to tackle the problem of per-frame fingertip detection in depth images. The method reduces the complexity of learning in the space of articulated poses which is demonstrated by using two distinct state-of-the-art learning based hand pose estimation methods applied to fingertip detection. Significant classification improvements are shown over the baseline implementation. Our framework involves no tracking, kinematic constraints or explicit prior model of the articulated object in hand. To support our approach we also describe a new pipeline for high accuracy magnetic annotation and labeling of objects imaged by a depth camera.