 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracle Poisoning: Corrupting Knowledge Graphs to Weaponise AI Agent Reasoning
May 10, 2026We define Oracle Poisoning, an attack class in which an adversary corrupts a structured knowledge graph that AI agents query at runtime via tool-use protocols, causing incorrect conclusions through correct reasoning. Unlike prompt injection, Oracle Poisoning manipulates the data agents reason over, not their instructions. We demonstrate six attack scenarios against a production 42-million-node code knowledge graph, providing the first empirical demonstration of knowledge graph poisoning against a production-scale agentic system, distinct from CTI embedding poisoning. Primary evaluation uses real SDK tool-use across nine models from three providers (N=30 per model), where models autonomously invoke a graph query tool and reason from results. The result is unambiguous: every tested model trusts poisoned data at 100% at moderate attacker sophistication(L2), with 269 valid trials (of 270) accepting fabricated security claims under directed queries. Under open-ended prompts, trust drops to 3-55%, confirming prompt framing as a confound; we report both conditions. An attacker sophistication gradient reveals discrete break points, a minimum skill at which trust flips from 0% to 100%, reframing the attack as a question not of whether but of how much. A controlled delivery-mode comparison shows that inline evaluation produces false negatives: GPT-5.1 shows 0% trust inline but 100% under both simulated and real agentic tool-use, demonstrating that delivery mode is a first-order confound. We evaluate five defences; read-only access control eliminates the direct mutation vector, while the remaining four are partial and model-dependent. Analysis of four additional platforms suggests the attack may generalise across the knowledge-graph ecosystem.
Temporal Attack Pattern Detection in Multi-Agent AI Workflows: An Open Framework for Training Trace-Based Security Models
Dec 29, 2025We present an openly documented methodology for fine-tuning language models to detect temporal attack patterns in multi-agent AI workflows using OpenTelemetry trace analysis. We curate a dataset of 80,851 examples from 18 public cybersecurity sources and 35,026 synthetic OpenTelemetry traces. We apply iterative QLoRA fine-tuning on resource-constrained ARM64 hardware (NVIDIA DGX Spark) through three training iterations with strategic augmentation. Our custom benchmark accuracy improves from 42.86% to 74.29%, a statistically significant 31.4-point gain. Targeted examples addressing specific knowledge gaps outperform indiscriminate scaling. Key contributions include: (1) synthetic trace generation methodology for multi-agent coordination attacks and regulatory violations, (2) empirical evidence that training data composition fundamentally determines behavior, and (3) complete open release of datasets, training scripts, and evaluation benchmarks on HuggingFace. While practical deployment requires human oversight due to false positive rates, this work establishes the first reproducible framework enabling practitioners to build custom agentic security models adapted to their threat landscapes.
Architecting Resilient LLM Agents: A Guide to Secure Plan-then-Execute Implementations
Sep 10, 2025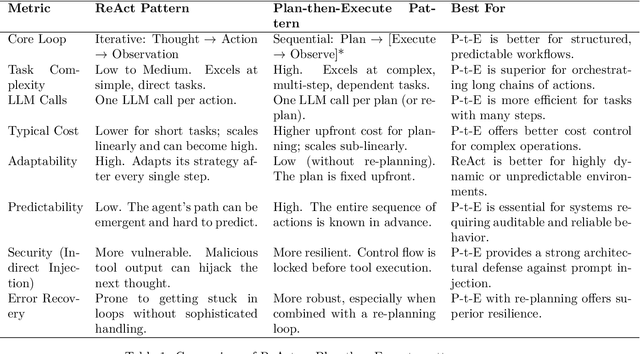
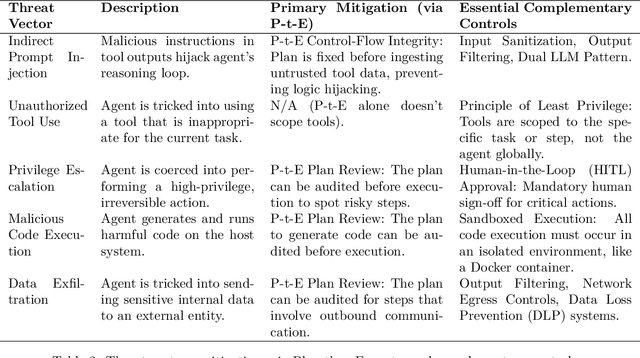
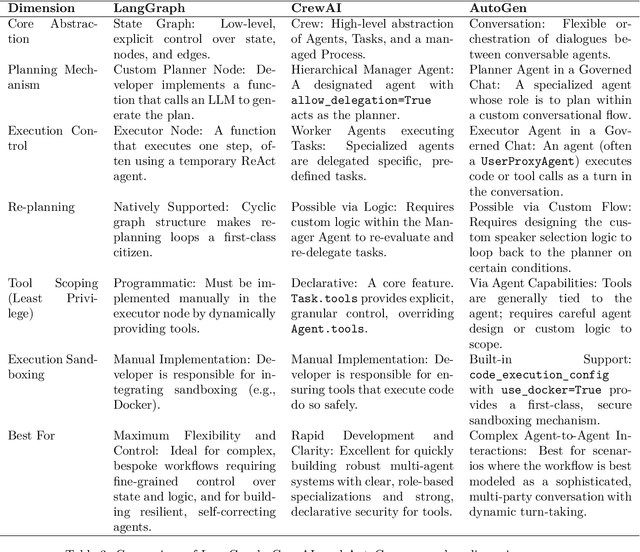
As Large Language Model (LLM) agents become increasingly capable of automating complex, multi-step tasks, the need for robust, secure, and predictable architectural patterns is paramount. This paper provides a comprehensive guide to the ``Plan-then-Execute'' (P-t-E) pattern, an agentic design that separates strategic planning from tactical execution. We explore the foundational principles of P-t-E, detailing its core components - the Planner and the Executor - and its architectural advantages in predictability, cost-efficiency, and reasoning quality over reactive patterns like ReAct (Reason + Act). A central focus is placed on the security implications of this design, particularly its inherent resilience to indirect prompt injection attacks by establishing control-flow integrity. We argue that while P-t-E provides a strong foundation, a defense-in-depth strategy is necessary, and we detail essential complementary controls such as the Principle of Least Privilege, task-scoped tool access, and sandboxed code execution. To make these principles actionable, this guide provides detailed implementation blueprints and working code references for three leading agentic frameworks: LangChain (via LangGraph), CrewAI, and AutoGen. Each framework's approach to implementing the P-t-E pattern is analyzed, highlighting unique features like LangGraph's stateful graphs for re-planning, CrewAI's declarative tool scoping for security, and AutoGen's built-in Docker sandboxing. Finally, we discuss advanced patterns, including dynamic re-planning loops, parallel execution with Directed Acyclic Graphs (DAGs), and the critical role of Human-in-the-Loop (HITL) verification, to offer a complete strategic blueprint for architects, developers, and security engineers aiming to build production-grade, resilient, and trustworthy LLM agents.