 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Governs the Machine? A Machine Identity Governance Taxonomy (MIGT) for AI Systems Operating Across Enterprise and Geopolitical Boundaries
Apr 07, 2026The governance of artificial intelligence has a blind spot: the machine identities that AI systems use to act. AI agents, service accounts, API tokens, and automated workflows now outnumber human identities in enterprise environments by ratios exceeding 80 to 1, yet no integrated framework exists to govern them. A single ungoverned automated agent produced $5.4-10 billion in losses in the 2024 CrowdStrike outage; nation-state actors including Silk Typhoon and Salt Typhoon have operationalized ungoverned machine credentials as primary espionage vectors against critical infrastructure. This paper makes four original contributions. First, the AI-Identity Risk Taxonomy (AIRT): a comprehensive enumeration of 37 risk sub-categories across eight domains, each grounded in documented incidents, regulatory recognition, practitioner prevalence data, and threat intelligence. Second, the Machine Identity Governance Taxonomy (MIGT): an integrated six-domain governance framework simultaneously addressing the technical governance gap, the regulatory compliance gap, and the cross-jurisdictional coordination gap that existing frameworks address only in isolation. Third, a foreign state actor threat model for enterprise identity governance, establishing that Silk Typhoon, Salt Typhoon, Volt Typhoon, and North Korean AI-enhanced identity fraud operations have already operationalized AI identity vulnerabilities as active attack vectors. Fourth, a cross-jurisdictional regulatory alignment structure mapping enterprise AI identity governance obligations under EU, US, and Chinese frameworks simultaneously, identifying irreconcilable conflicts and providing a governance mechanism for managing them. A four-phase implementation roadmap translates the MIGT into actionable enterprise programs.
How Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Architecting Resilient LLM Agents: A Guide to Secure Plan-then-Execute Implementations
Sep 10, 2025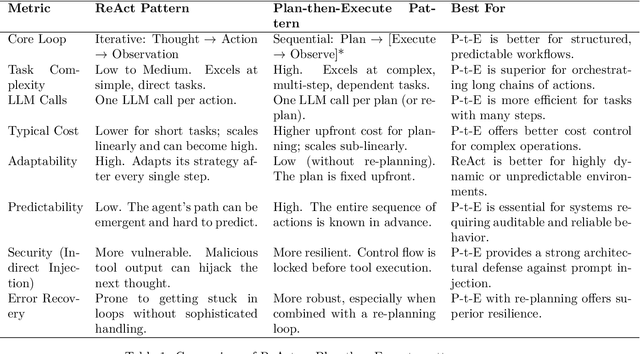
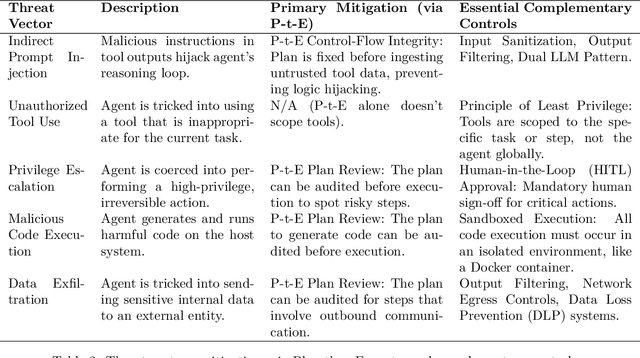
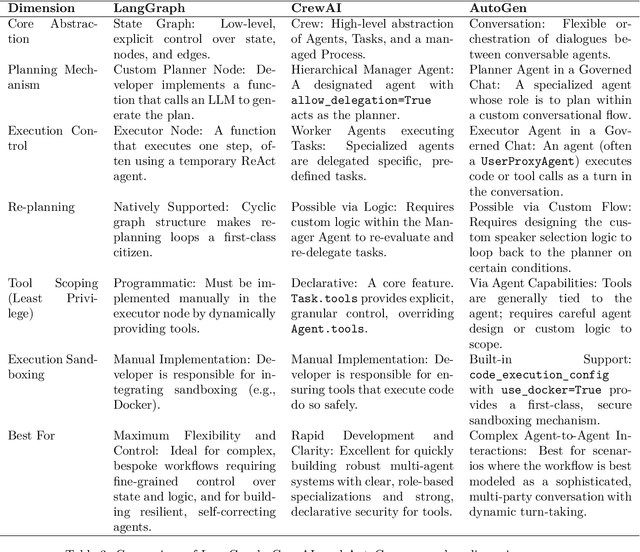
As Large Language Model (LLM) agents become increasingly capable of automating complex, multi-step tasks, the need for robust, secure, and predictable architectural patterns is paramount. This paper provides a comprehensive guide to the ``Plan-then-Execute'' (P-t-E) pattern, an agentic design that separates strategic planning from tactical execution. We explore the foundational principles of P-t-E, detailing its core components - the Planner and the Executor - and its architectural advantages in predictability, cost-efficiency, and reasoning quality over reactive patterns like ReAct (Reason + Act). A central focus is placed on the security implications of this design, particularly its inherent resilience to indirect prompt injection attacks by establishing control-flow integrity. We argue that while P-t-E provides a strong foundation, a defense-in-depth strategy is necessary, and we detail essential complementary controls such as the Principle of Least Privilege, task-scoped tool access, and sandboxed code execution. To make these principles actionable, this guide provides detailed implementation blueprints and working code references for three leading agentic frameworks: LangChain (via LangGraph), CrewAI, and AutoGen. Each framework's approach to implementing the P-t-E pattern is analyzed, highlighting unique features like LangGraph's stateful graphs for re-planning, CrewAI's declarative tool scoping for security, and AutoGen's built-in Docker sandboxing. Finally, we discuss advanced patterns, including dynamic re-planning loops, parallel execution with Directed Acyclic Graphs (DAGs), and the critical role of Human-in-the-Loop (HITL) verification, to offer a complete strategic blueprint for architects, developers, and security engineers aiming to build production-grade, resilient, and trustworthy LLM agents.