 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of LLMs on Online News Consumption and Production
Dec 31, 2025Large language models (LLMs) change how consumers acquire information online; their bots also crawl news publishers' websites for training data and to answer consumer queries; and they provide tools that can lower the cost of content creation. These changes lead to predictions of adverse impact on news publishers in the form of lowered consumer demand, reduced demand for newsroom employees, and an increase in news "slop." Consequently, some publishers strategically responded by blocking LLM access to their websites using the robots.txt file standard. Using high-frequency granular data, we document four effects related to the predicted shifts in news publishing following the introduction of generative AI (GenAI). First, we find a consistent and moderate decline in traffic to news publishers occurring after August 2024. Second, using a difference-in-differences approach, we find that blocking GenAI bots can have adverse effects on large publishers by reducing total website traffic by 23% and real consumer traffic by 14% compared to not blocking. Third, on the hiring side, we do not find evidence that LLMs are replacing editorial or content-production jobs yet. The share of new editorial and content-production job listings increases over time. Fourth, regarding content production, we find no evidence that large publishers increased text volume; instead, they significantly increased rich content and use more advertising and targeting technologies. Together, these findings provide early evidence of some unforeseen impacts of the introduction of LLMs on news production and consumption.
Algorithmic Collusion of Pricing and Advertising on E-commerce Platforms
Aug 09, 2025
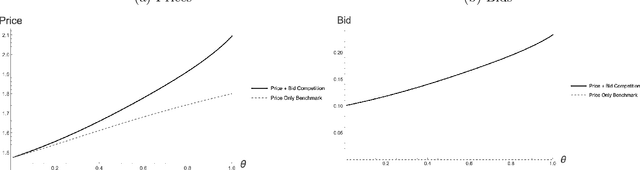
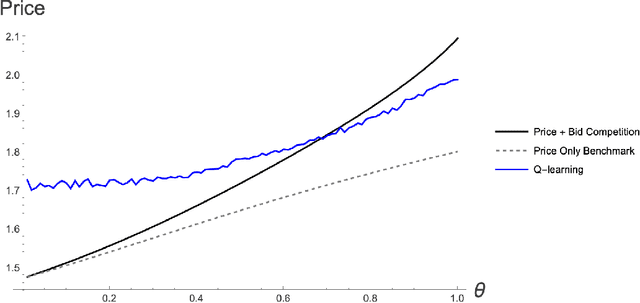
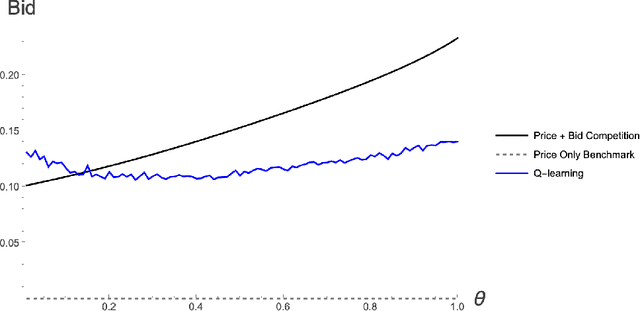
Online sellers have been adopting AI learning algorithms to automatically make product pricing and advertising decisions on e-commerce platforms. When sellers compete using such algorithms, one concern is that of tacit collusion - the algorithms learn to coordinate on higher than competitive. We empirically investigate whether these concerns are valid when sellers make pricing and advertising decisions together, i.e., two-dimensional decisions. Our empirical strategy is to analyze competition with multi-agent reinforcement learning, which we calibrate to a large-scale dataset collected from Amazon.com products. Our first contribution is to find conditions under which learning algorithms can facilitate win-win-win outcomes that are beneficial for consumers, sellers, and even the platform, when consumers have high search costs. In these cases the algorithms learn to coordinate on prices that are lower than competitive prices. The intuition is that the algorithms learn to coordinate on lower advertising bids, which lower advertising costs, leading to lower prices. Our second contribution is an analysis of a large-scale, high-frequency keyword-product dataset for more than 2 million products on Amazon.com. Our estimates of consumer search costs show a wide range of costs for different product keywords. We generate an algorithm usage and find a negative interaction between the estimated consumer search costs and the algorithm usage index, providing empirical evidence of beneficial collusion. Finally, we analyze the platform's strategic response. We find that reserve price adjustments will not increase profits for the platform, but commission adjustments will. Our analyses help alleviate some worries about the potentially harmful effects of competing learning algorithms, and can help sellers, platforms and policymakers to decide on whether to adopt or regulate such algorithms.
When Is Heterogeneity Actionable for Personalization?
Nov 25, 2024



Targeting and personalization policies can be used to improve outcomes beyond the uniform policy that assigns the best performing treatment in an A/B test to everyone. Personalization relies on the presence of heterogeneity of treatment effects, yet, as we show in this paper, heterogeneity alone is not sufficient for personalization to be successful. We develop a statistical model to quantify "actionable heterogeneity," or the conditions when personalization is likely to outperform the best uniform policy. We show that actionable heterogeneity can be visualized as crossover interactions in outcomes across treatments and depends on three population-level parameters: within-treatment heterogeneity, cross-treatment correlation, and the variation in average responses. Our model can be used to predict the expected gain from personalization prior to running an experiment and also allows for sensitivity analysis, providing guidance on how changing treatments can affect the personalization gain. To validate our model, we apply five common personalization approaches to two large-scale field experiments with many interventions that encouraged flu vaccination. We find an 18% gain from personalization in one and a more modest 4% gain in the other, which is consistent with our model. Counterfactual analysis shows that this difference in the gains from personalization is driven by a drastic difference in within-treatment heterogeneity. However, reducing cross-treatment correlation holds a larger potential to further increase personalization gains. Our findings provide a framework for assessing the potential from personalization and offer practical recommendations for improving gains from targeting in multi-intervention settings.
Ranking by Lifts: A Cost-Benefit Approach to Large-Scale A/B Tests
Jul 01, 2024A/B testers conducting large-scale tests prioritize lifts and want to be able to control false rejections of the null. This work develops a decision-theoretic framework for maximizing profits subject to false discovery rate (FDR) control. We build an empirical Bayes solution for the problem via the greedy knapsack approach. We derive an oracle rule based on ranking the ratio of expected lifts and the cost of wrong rejections using the local false discovery rate (lfdr) statistic. Our oracle decision rule is valid and optimal for large-scale tests. Further, we establish asymptotic validity for the data-driven procedure and demonstrate finite-sample validity in experimental studies. We also demonstrate the merit of the proposed method over other FDR control methods. Finally, we discuss an application to actual Optimizely experiments.