 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlioma C6: A Novel Dataset for Training and Benchmarking Cell Segmentation
Nov 10, 2025
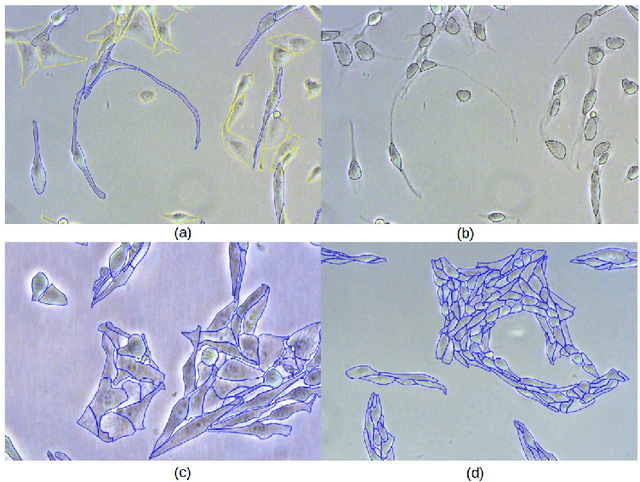
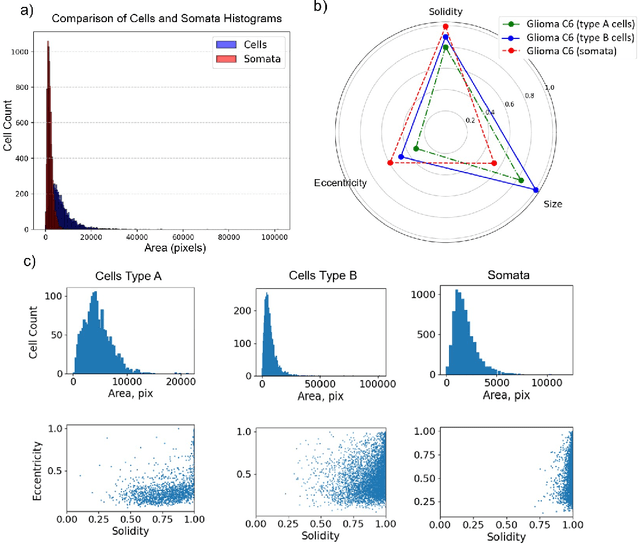
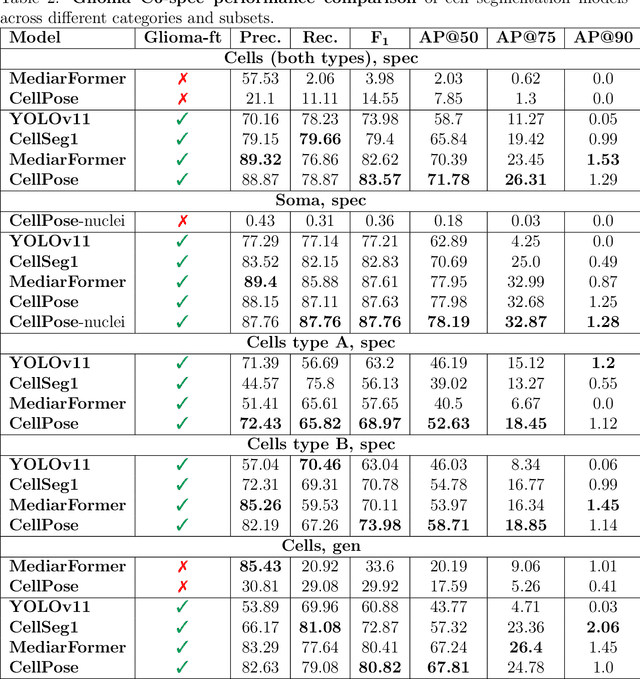
We present Glioma C6, a new open dataset for instance segmentation of glioma C6 cells, designed as both a benchmark and a training resource for deep learning models. The dataset comprises 75 high-resolution phase-contrast microscopy images with over 12,000 annotated cells, providing a realistic testbed for biomedical image analysis. It includes soma annotations and morphological cell categorization provided by biologists. Additional categorization of cells, based on morphology, aims to enhance the utilization of image data for cancer cell research. Glioma C6 consists of two parts: the first is curated with controlled parameters for benchmarking, while the second supports generalization testing under varying conditions. We evaluate the performance of several generalist segmentation models, highlighting their limitations on our dataset. Our experiments demonstrate that training on Glioma C6 significantly enhances segmentation performance, reinforcing its value for developing robust and generalizable models. The dataset is publicly available for researchers.
Neural network task specialization via domain constraining
Apr 28, 2025



This paper introduces a concept of neural network specialization via task-specific domain constraining, aimed at enhancing network performance on data subspace in which the network operates. The study presents experiments on training specialists for image classification and object detection tasks. The results demonstrate that specialization can enhance a generalist's accuracy even without additional data or changing training regimes: solely by constraining class label space in which the network performs. Theoretical and experimental analyses indicate that effective specialization requires modifying traditional fine-tuning methods and constraining data space to semantically coherent subsets. The specialist extraction phase before tuning the network is proposed for maximal performance gains. We also provide analysis of the evolution of the feature space during specialization. This study paves way to future research for developing more advanced dynamically configurable image analysis systems, where computations depend on the specific input. Additionally, the proposed methods can help improve system performance in scenarios where certain data domains should be excluded from consideration of the generalist network.
Hypernym Bias: Unraveling Deep Classifier Training Dynamics through the Lens of Class Hierarchy
Feb 17, 2025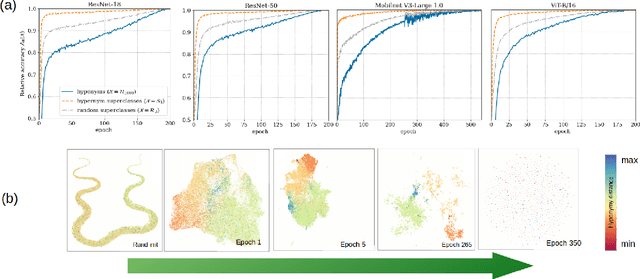
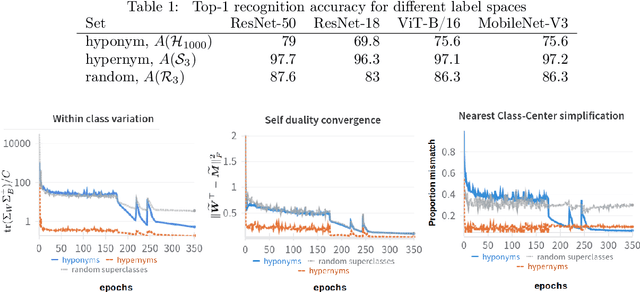
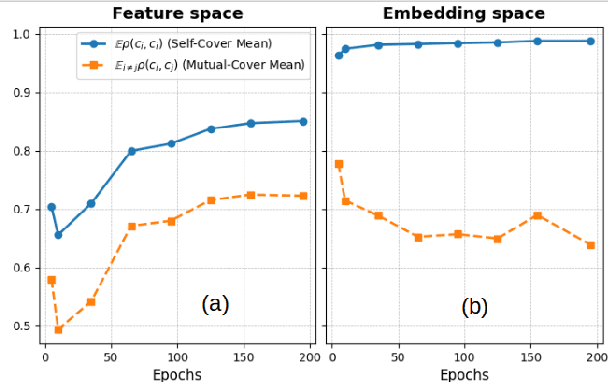

We investigate the training dynamics of deep classifiers by examining how hierarchical relationships between classes evolve during training. Through extensive experiments, we argue that the learning process in classification problems can be understood through the lens of label clustering. Specifically, we observe that networks tend to distinguish higher-level (hypernym) categories in the early stages of training, and learn more specific (hyponym) categories later. We introduce a novel framework to track the evolution of the feature manifold during training, revealing how the hierarchy of class relations emerges and refines across the network layers. Our analysis demonstrates that the learned representations closely align with the semantic structure of the dataset, providing a quantitative description of the clustering process. Notably, we show that in the hypernym label space, certain properties of neural collapse appear earlier than in the hyponym label space, helping to bridge the gap between the initial and terminal phases of learning. We believe our findings offer new insights into the mechanisms driving hierarchical learning in deep networks, paving the way for future advancements in understanding deep learning dynamics.
Sparsely ensembled convolutional neural network classifiers via reinforcement learning
Feb 07, 2021



We consider convolutional neural network (CNN) ensemble learning with the objective function inspired by least action principle; it includes resource consumption component. We teach an agent to perceive images through the set of pre-trained classifiers and want the resulting dynamically configured system to unfold the computational graph with the trajectory that refers to the minimal number of operations and maximal expected accuracy. The proposed agent's architecture implicitly approximates the required classifier selection function with the help of reinforcement learning. Our experimental results prove, that if the agent exploits the dynamic (and context-dependent) structure of computations, it outperforms conventional ensemble learning.