 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIT.UA-AAUBS at ArchEHR-QA 2026: Evaluating Open-Source and Proprietary LLMs via Prompting in Low-Resource QA
May 05, 2026This paper presents the joint participation of the BIT.UA and AAUBS groups in the ArchEHR-QA 2026 shared task, which focuses on clinical question answering and evidence grounding in a low-resource setting. Due to the absence of training data and the strict data privacy constraints inherent to the healthcare domain (e.g. GDPR), we investigate the capabilities of Large Language Models (LLMs) without weight updates. We evaluate several state-of-the-art proprietary models and locally deployable open-source alternatives using various prompt engineering strategies, including task decomposition, Chain-of-Thought, and in-context learning. Furthermore, we explore majority voting and LLM-as-a-judge ensembling techniques to maximize predictive robustness. Our results demonstrate that while proprietary models exhibit strong resilience to prompt variations, domain-adapted open-source models (such as MedGemma 3 27B) achieve highly competitive performance when paired with the right prompt. Overall, our prompt-based approach proved highly effective, securing 1st place in Subtask 4 (evidence citation alignment) and 3rd place in Subtask 3 (patient-friendly answer generation). All code, results, and prompts are available on our GitHub repository: https://github.com/bioinformatics-ua/ArchEHR-QA-2026.
Hybrid Model for Patent Classification using Augmented SBERT and KNN
Mar 22, 2021
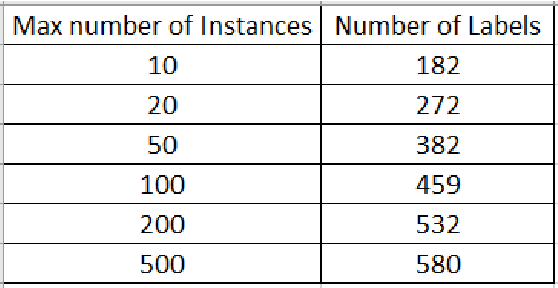
Purpose: This study aims to provide a hybrid approach for patent claim classification with Sentence-BERT (SBERT) and K Nearest Neighbours (KNN) and explicitly focuses on the patent claims. Patent classification is a multi-label classification task in which the number of labels can be greater than 640 at the subclass level. The proposed framework predicts individual input patent class and subclass based on finding top k semantic similarity patents. Design/Methodology/Approach: The study uses transformer models based on Augmented SBERT and RoBERTa. We use a different approach to predict patent classification by finding top k similar patent claims and using the KNN algorithm to predict patent class or subclass. Besides, in this study, we just focus on patent claims, and in the future study, we add other appropriate parts of patent documents. Findings: The findings suggest the relevance of hybrid models to predict multi-label classification based on text data. In this approach, we used the Transformer model as the distance function in KNN, and proposed a new version of KNN based on Augmented SBERT. Practical Implications: The presented framework provides a practical model for patent classification. In this study, we predict the class and subclass of the patent based on semantic claims similarity. The end-user interpretability of the results is one of the essential positive points of the model. Originality/Value: The main contribution of the study included: 1) Using the Augmented approach for fine-tuning SBERT by in-domain supervised patent claims data. 2) Improving results based on a hybrid model for patent classification. The best result of F1-score at the subclass level was > 69%) Proposing the practical model with high interpretability of results.
Introduction to Rare-Event Predictive Modeling for Inferential Statisticians -- A Hands-On Application in the Prediction of Breakthrough Patents
Mar 30, 2020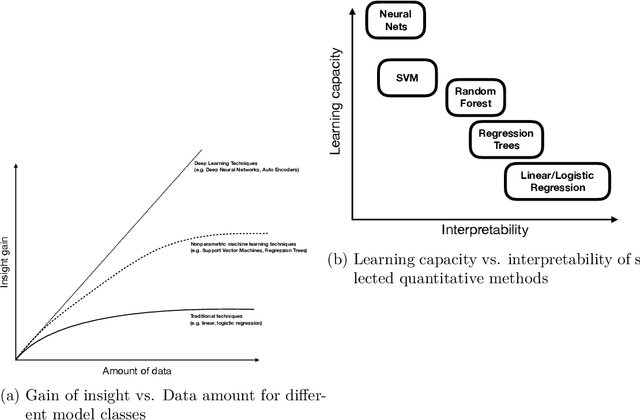
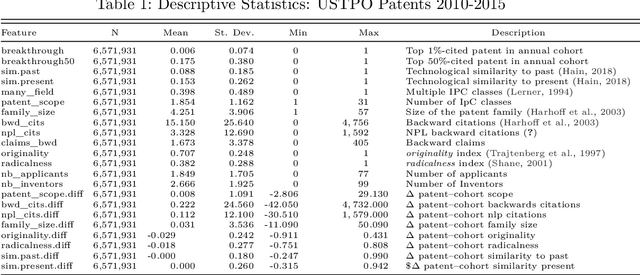
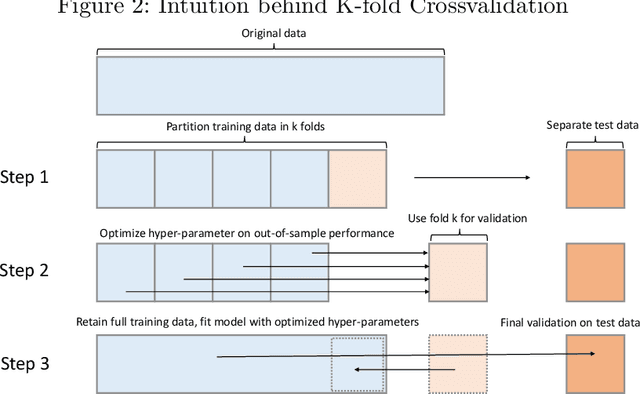
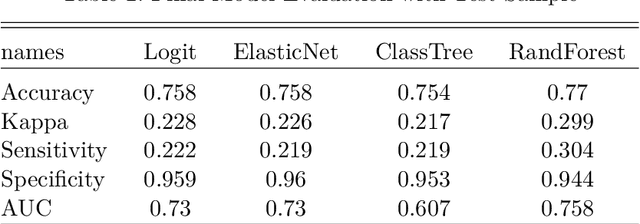
Recent years have seen a substantial development of quantitative methods, mostly led by the computer science community with the goal to develop better machine learning application, mainly focused on predictive modeling. However, economic, management, and technology forecasting research has up to now been hesitant to apply predictive modeling techniques and workflows. In this paper, we introduce to a machine learning (ML) approach to quantitative analysis geared towards optimizing the predictive performance, contrasting it with standard practices inferential statistics which focus on producing good parameter estimates. We discuss the potential synergies between the two fields against the backdrop of this at first glance, \enquote{target-incompatibility}. We discuss fundamental concepts in predictive modeling, such as out-of-sample model validation, variable and model selection, generalization and hyperparameter tuning procedures. Providing a hands-on predictive modelling for an quantitative social science audience, while aiming at demystifying computer science jargon. We use the example of \enquote{high-quality} patent identification guiding the reader through various model classes and procedures for data pre-processing, modelling and validation. We start of with more familiar easy to interpret model classes (Logit and Elastic Nets), continues with less familiar non-parametric approaches (Classification Trees and Random Forest) and finally presents artificial neural network architectures, first a simple feed-forward and then a deep autoencoder geared towards anomaly detection. Instead of limiting ourselves to the introduction of standard ML techniques, we also present state-of-the-art yet approachable techniques from artificial neural networks and deep learning to predict rare phenomena of interest.