 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Model for Patent Classification using Augmented SBERT and KNN
Mar 22, 2021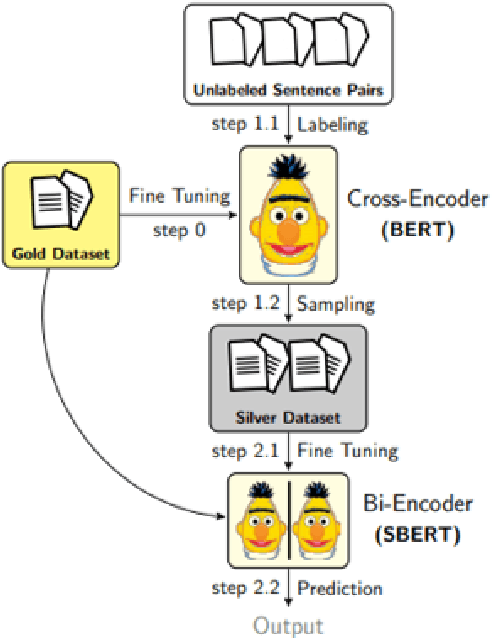
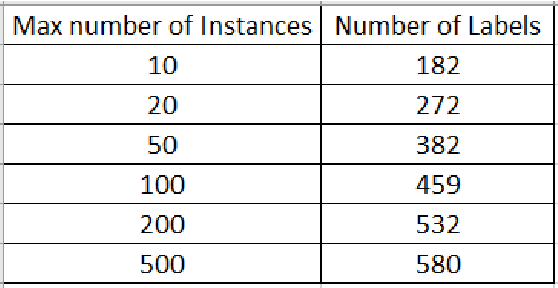
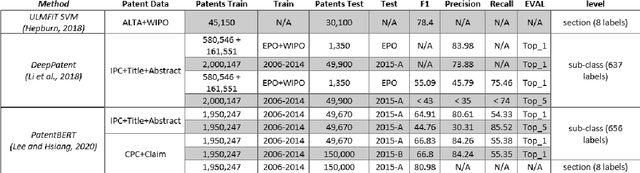
Purpose: This study aims to provide a hybrid approach for patent claim classification with Sentence-BERT (SBERT) and K Nearest Neighbours (KNN) and explicitly focuses on the patent claims. Patent classification is a multi-label classification task in which the number of labels can be greater than 640 at the subclass level. The proposed framework predicts individual input patent class and subclass based on finding top k semantic similarity patents. Design/Methodology/Approach: The study uses transformer models based on Augmented SBERT and RoBERTa. We use a different approach to predict patent classification by finding top k similar patent claims and using the KNN algorithm to predict patent class or subclass. Besides, in this study, we just focus on patent claims, and in the future study, we add other appropriate parts of patent documents. Findings: The findings suggest the relevance of hybrid models to predict multi-label classification based on text data. In this approach, we used the Transformer model as the distance function in KNN, and proposed a new version of KNN based on Augmented SBERT. Practical Implications: The presented framework provides a practical model for patent classification. In this study, we predict the class and subclass of the patent based on semantic claims similarity. The end-user interpretability of the results is one of the essential positive points of the model. Originality/Value: The main contribution of the study included: 1) Using the Augmented approach for fine-tuning SBERT by in-domain supervised patent claims data. 2) Improving results based on a hybrid model for patent classification. The best result of F1-score at the subclass level was > 69%) Proposing the practical model with high interpretability of results.
An evolutionary view on the emergence of Artificial Intelligence
Jan 30, 2021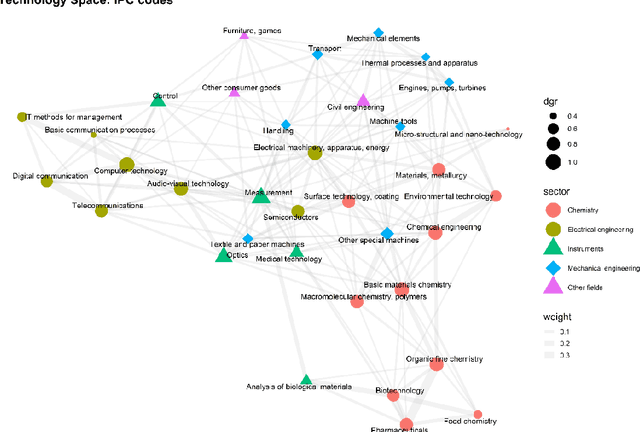
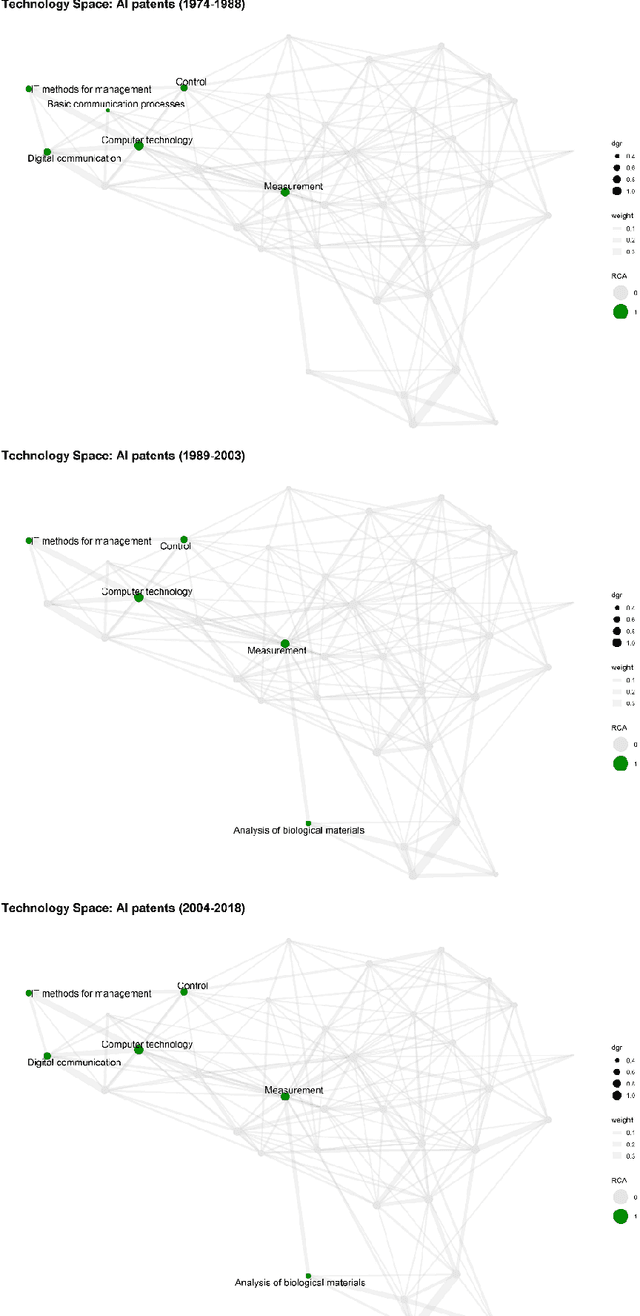
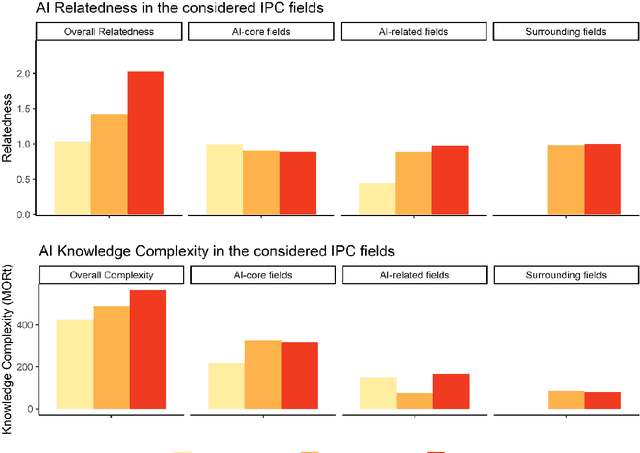
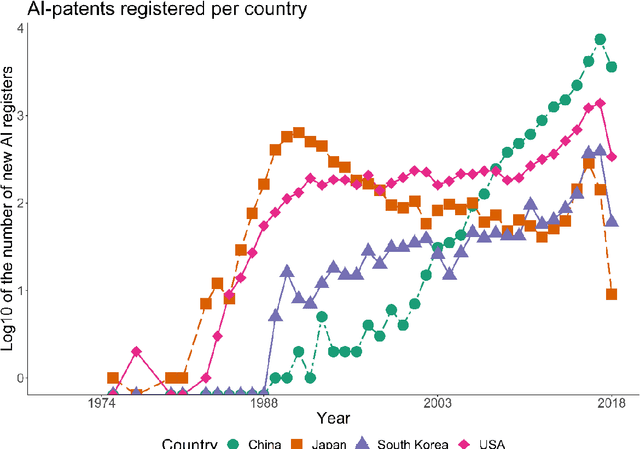
This paper draws upon the evolutionary concepts of technological relatedness and knowledge complexity to enhance our understanding of the long-term evolution of Artificial Intelligence (AI). We reveal corresponding patterns in the emergence of AI - globally and in the context of specific geographies of the US, Japan, South Korea, and China. We argue that AI emergence is associated with increasing related variety due to knowledge commonalities as well as increasing complexity. We use patent-based indicators for the period between 1974-2018 to analyse the evolution of AI's global technological space, to identify its technological core as well as changes to its overall relatedness and knowledge complexity. At the national level, we also measure countries' overall specialisations against AI-specific ones. At the global level, we find increasing overall relatedness and complexity of AI. However, for the technological core of AI, which has been stable over time, we find decreasing related variety and increasing complexity. This evidence points out that AI innovations related to core technologies are becoming increasingly distinct from each other. At the country level, we find that the US and Japan have been increasing the overall relatedness of their innovations. The opposite is the case for China and South Korea, which we associate with the fact that these countries are overall less technologically developed than the US and Japan. Finally, we observe a stable increasing overall complexity for all countries apart from China, which we explain by the focus of this country in technologies not strongly linked to AI.