 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDereverberation of Autoregressive Envelopes for Far-field Speech Recognition
Aug 13, 2021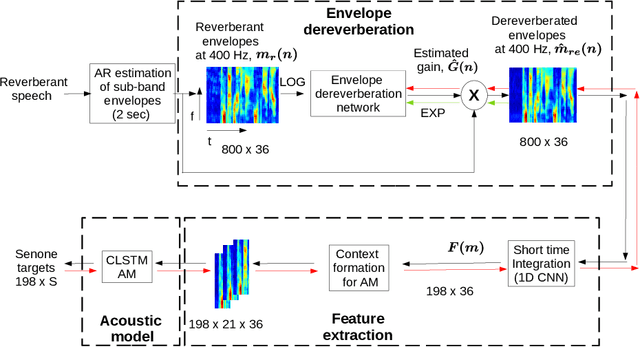
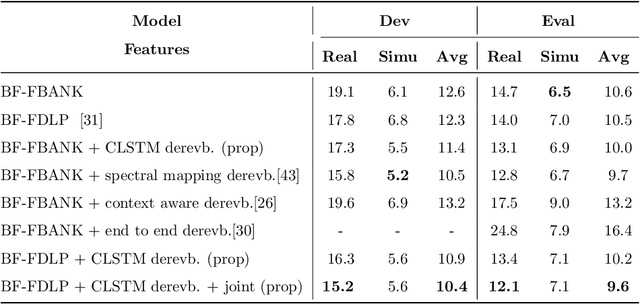
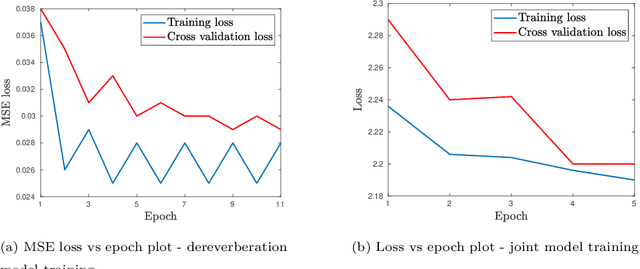
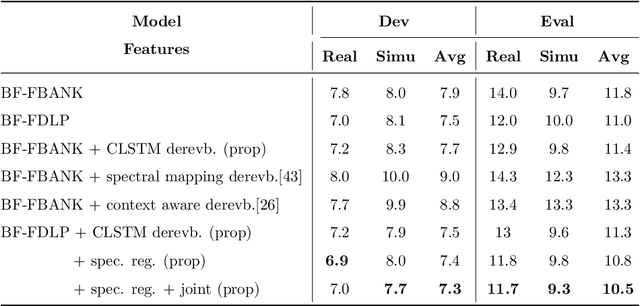
The task of speech recognition in far-field environments is adversely affected by the reverberant artifacts that elicit as the temporal smearing of the sub-band envelopes. In this paper, we develop a neural model for speech dereverberation using the long-term sub-band envelopes of speech. The sub-band envelopes are derived using frequency domain linear prediction (FDLP) which performs an autoregressive estimation of the Hilbert envelopes. The neural dereverberation model estimates the envelope gain which when applied to reverberant signals suppresses the late reflection components in the far-field signal. The dereverberated envelopes are used for feature extraction in speech recognition. Further, the sequence of steps involved in envelope dereverberation, feature extraction and acoustic modeling for ASR can be implemented as a single neural processing pipeline which allows the joint learning of the dereverberation network and the acoustic model. Several experiments are performed on the REVERB challenge dataset, CHiME-3 dataset and VOiCES dataset. In these experiments, the joint learning of envelope dereverberation and acoustic model yields significant performance improvements over the baseline ASR system based on log-mel spectrogram as well as other past approaches for dereverberation (average relative improvements of 10-24% over the baseline system). A detailed analysis on the choice of hyper-parameters and the cost function involved in envelope dereverberation is also provided.
End-to-End Speech Recognition With Joint Dereverberation Of Sub-Band Autoregressive Envelopes
Aug 09, 2021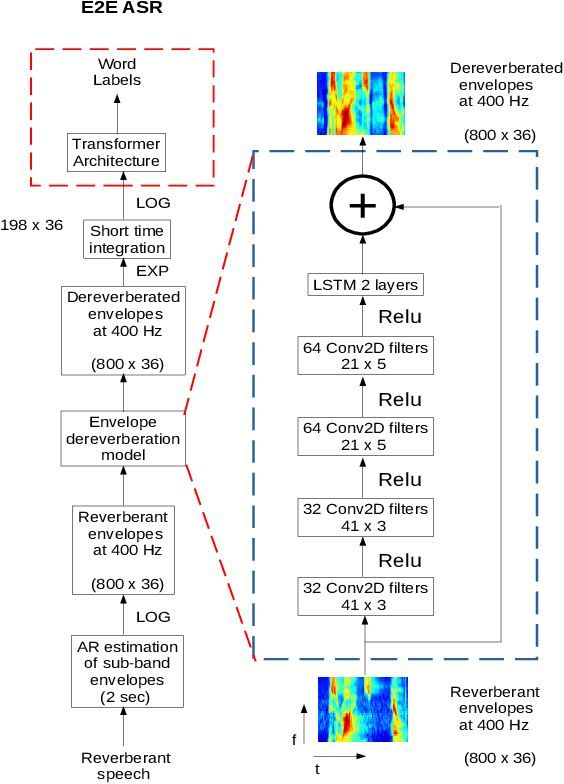
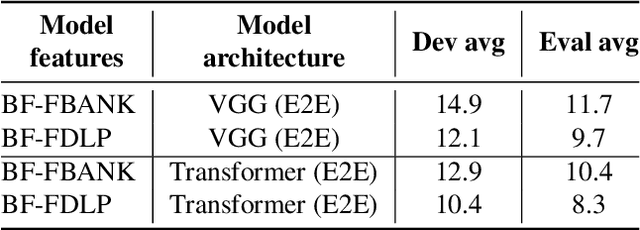
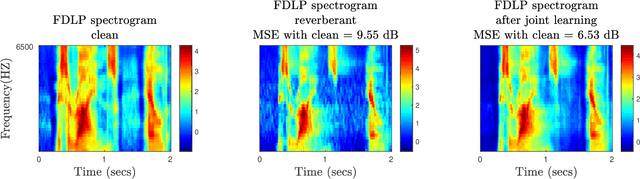
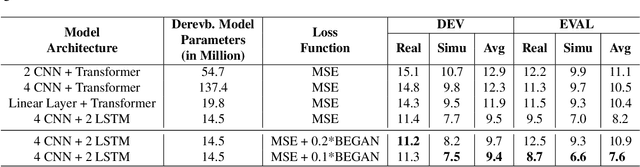
The end-to-end (E2E) automatic speech recognition (ASR) offers several advantages over previous efforts for recognizing speech. However, in reverberant conditions, E2E ASR is a challenging task as the long-term sub-band envelopes of the reverberant speech are temporally smeared. In this paper, we develop a feature enhancement approach using a neural model operating on sub-band temporal envelopes. The temporal envelopes are modeled using the framework of frequency domain linear prediction (FDLP). The neural enhancement model proposed in this paper performs an envelope gain based enhancement of temporal envelopes. The model architecture consists of a combination of convolutional and long short term memory (LSTM) neural network layers. Further, the envelope dereverberation, feature extraction and acoustic modeling using transformer based E2E ASR can all be jointly optimized for the speech recognition task. The joint optimization ensures that the dereverberation model targets the ASR cost function. We perform E2E speech recognition experiments on the REVERB challenge dataset as well as on the VOiCES dataset. In these experiments, the proposed joint modeling approach yields significant improvements compared to baseline E2E ASR system (average relative improvements of 21% on the REVERB challenge dataset and about 10% on the VOiCES dataset).
SRIB-LEAP submission to Far-field Multi-Channel Speech Enhancement Challenge for Video Conferencing
Jun 24, 2021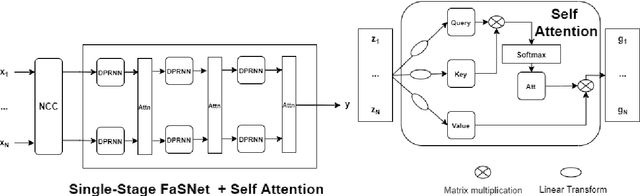
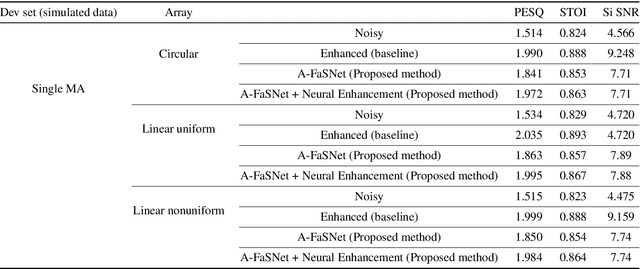


This paper presents the details of the SRIB-LEAP submission to the ConferencingSpeech challenge 2021. The challenge involved the task of multi-channel speech enhancement to improve the quality of far field speech from microphone arrays in a video conferencing room. We propose a two stage method involving a beamformer followed by single channel enhancement. For the beamformer, we incorporated self-attention mechanism as inter-channel processing layer in the filter-and-sum network (FaSNet), an end-to-end time-domain beamforming system. The single channel speech enhancement is done in log spectral domain using convolution neural network (CNN)-long short term memory (LSTM) based architecture. We achieved improvements in objective quality metrics - perceptual evaluation of speech quality (PESQ) of 0.5 on the noisy data. On subjective quality evaluation, the proposed approach improved the mean opinion score (MOS) by an absolute measure of 0.9 over the noisy audio.
Towards sound based testing of COVID-19 -- Summary of the first Diagnostics of COVID-19 using Acoustics Challenge
Jun 21, 2021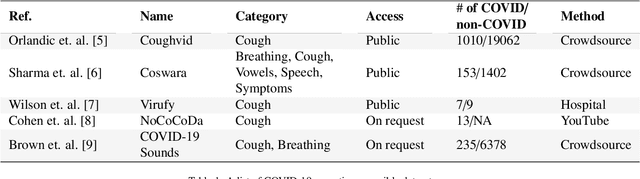
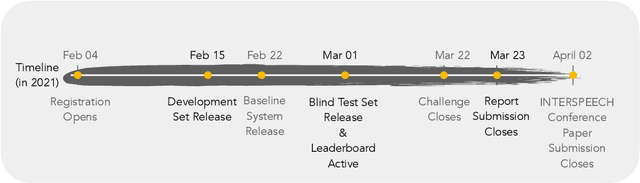
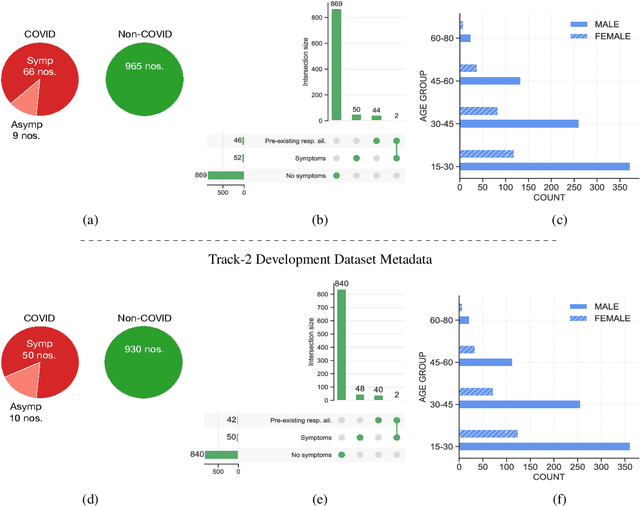
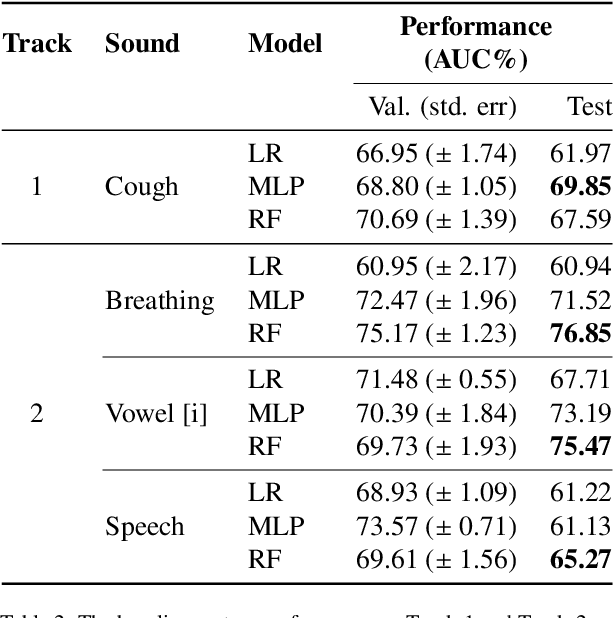
The technology development for point-of-care tests (POCTs) targeting respiratory diseases has witnessed a growing demand in the recent past. Investigating the presence of acoustic biomarkers in modalities such as cough, breathing and speech sounds, and using them for building POCTs can offer fast, contactless and inexpensive testing. In view of this, over the past year, we launched the ``Coswara'' project to collect cough, breathing and speech sound recordings via worldwide crowdsourcing. With this data, a call for development of diagnostic tools was announced in the Interspeech 2021 as a special session titled ``Diagnostics of COVID-19 using Acoustics (DiCOVA) Challenge''. The goal was to bring together researchers and practitioners interested in developing acoustics-based COVID-19 POCTs by enabling them to work on the same set of development and test datasets. As part of the challenge, datasets with breathing, cough, and speech sound samples from COVID-19 and non-COVID-19 individuals were released to the participants. The challenge consisted of two tracks. The Track-1 focused only on cough sounds, and participants competed in a leaderboard setting. In Track-2, breathing and speech samples were provided for the participants, without a competitive leaderboard. The challenge attracted 85 plus registrations with 29 final submissions for Track-1. This paper describes the challenge (datasets, tasks, baseline system), and presents a focused summary of the various systems submitted by the participating teams. An analysis of the results from the top four teams showed that a fusion of the scores from these teams yields an area-under-the-curve of 95.1% on the blind test data. By summarizing the lessons learned, we foresee the challenge overview in this paper to help accelerate technology for acoustic-based POCTs.
Multi-modal Point-of-Care Diagnostics for COVID-19 Based On Acoustics and Symptoms
Jun 05, 2021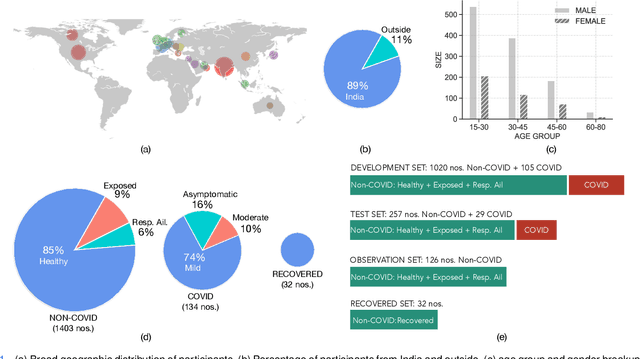
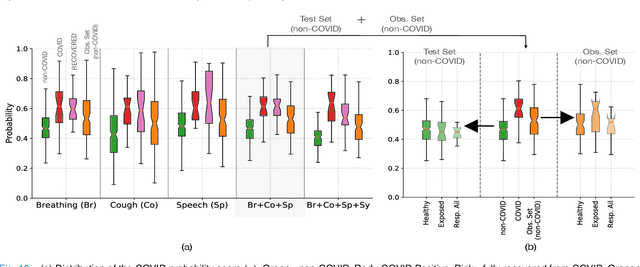
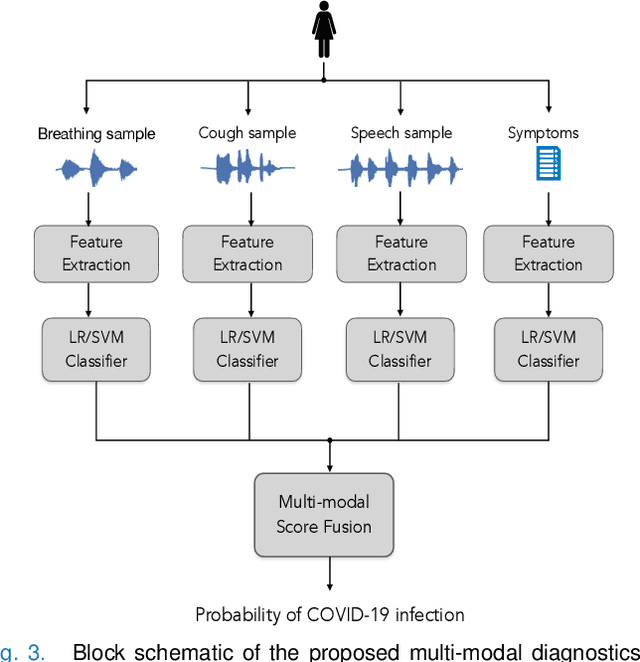
The research direction of identifying acoustic bio-markers of respiratory diseases has received renewed interest following the onset of COVID-19 pandemic. In this paper, we design an approach to COVID-19 diagnostic using crowd-sourced multi-modal data. The data resource, consisting of acoustic signals like cough, breathing, and speech signals, along with the data of symptoms, are recorded using a web-application over a period of ten months. We investigate the use of statistical descriptors of simple time-frequency features for acoustic signals and binary features for the presence of symptoms. Unlike previous works, we primarily focus on the application of simple linear classifiers like logistic regression and support vector machines for acoustic data while decision tree models are employed on the symptoms data. We show that a multi-modal integration of acoustics and symptoms classifiers achieves an area-under-curve (AUC) of 92.40, a significant improvement over any individual modality. Several ablation experiments are also provided which highlight the acoustic and symptom dimensions that are important for the task of COVID-19 diagnostics.
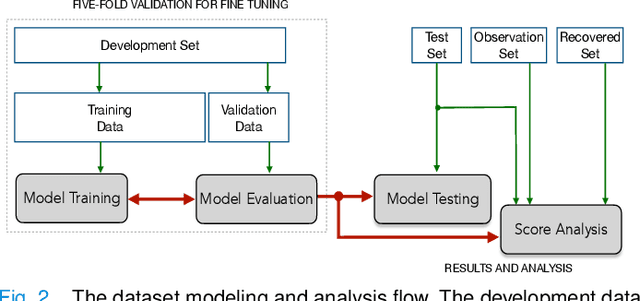
DiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics
Apr 05, 2021
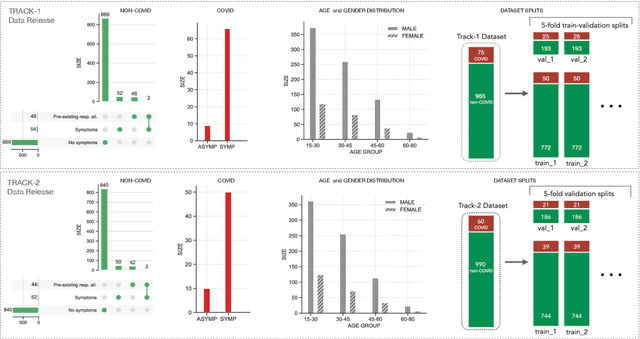
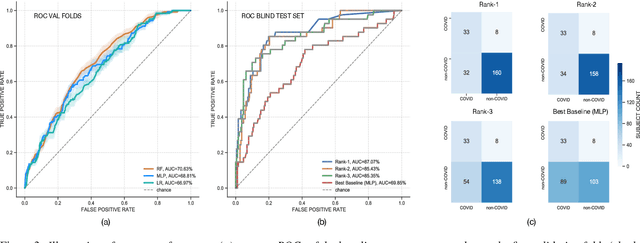
The DiCOVA challenge aims at accelerating research in diagnosing COVID-19 using acoustics (DiCOVA), a topic at the intersection of speech and audio processing, respiratory health diagnosis, and machine learning. This challenge is an open call for researchers to analyze a dataset of sound recordings collected from COVID-19 infected and non-COVID-19 individuals for a two-class classification. These recordings were collected via crowdsourcing from multiple countries, through a website application. The challenge features two tracks, one focusing on cough sounds, and the other on using a collection of breath, sustained vowel phonation, and number counting speech recordings. In this paper, we introduce the challenge and provide a detailed description of the task, and present a baseline system for the task.
Binary Choice with Asymmetric Loss in a Data-Rich Environment: Theory and an Application to Racial Justice
Oct 25, 2020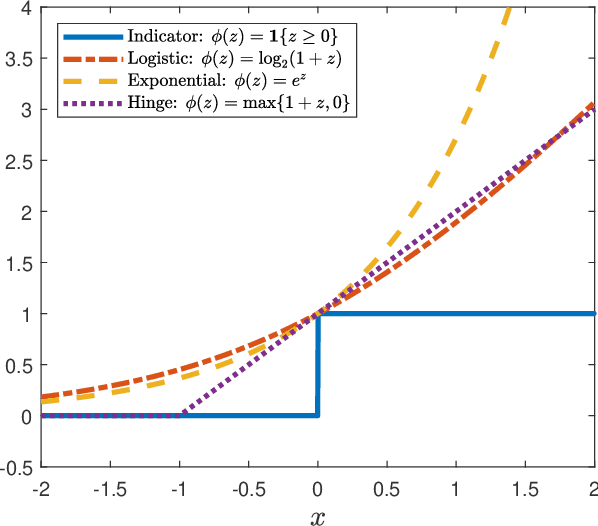
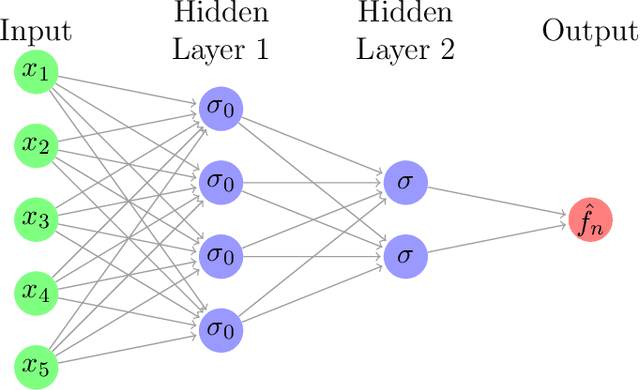
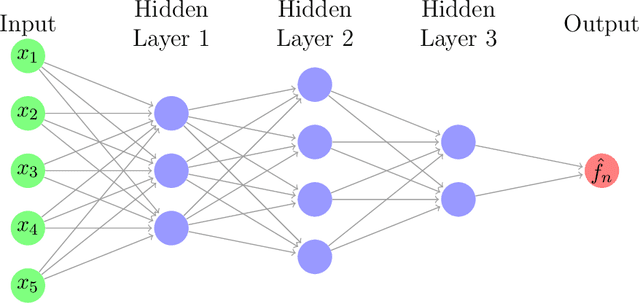
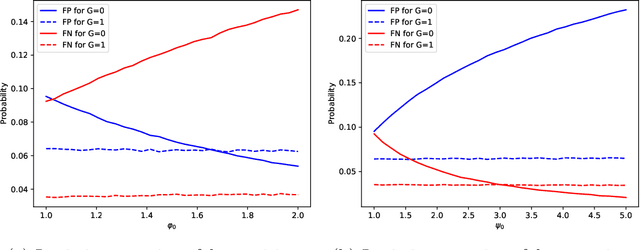
The importance of asymmetries in prediction problems arising in economics has been recognized for a long time. In this paper, we focus on binary choice problems in a data-rich environment with general loss functions. In contrast to the asymmetric regression problems, the binary choice with general loss functions and high-dimensional datasets is challenging and not well understood. Econometricians have studied binary choice problems for a long time, but the literature does not offer computationally attractive solutions in data-rich environments. In contrast, the machine learning literature has many computationally attractive algorithms that form the basis for much of the automated procedures that are implemented in practice, but it is focused on symmetric loss functions that are independent of individual characteristics. One of the main contributions of our paper is to show that the theoretically valid predictions of binary outcomes with arbitrary loss functions can be achieved via a very simple reweighting of the logistic regression, or other state-of-the-art machine learning techniques, such as boosting or (deep) neural networks. We apply our analysis to racial justice in pretrial detention.
Unsupervised Neural Mask Estimator For Generalized Eigen-Value Beamforming Based ASR
Nov 28, 2019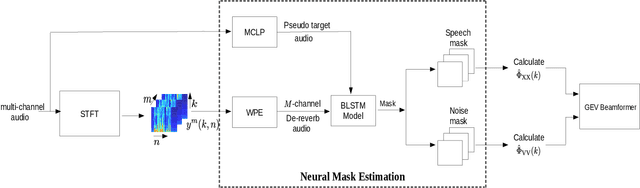

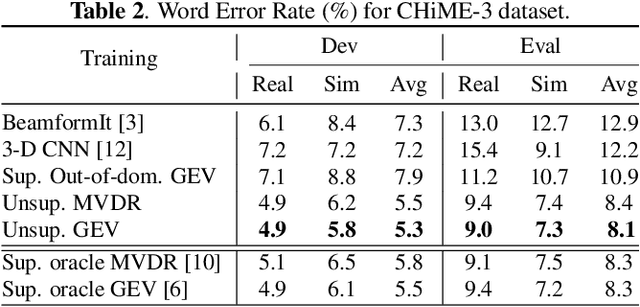
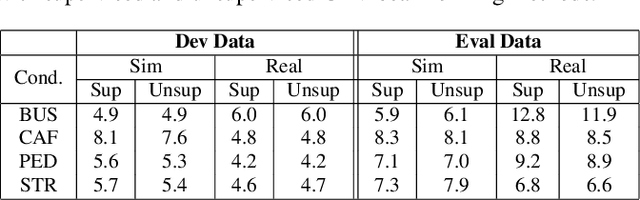
The state-of-art methods for acoustic beamforming in multi-channel ASR are based on a neural mask estimator that predicts the presence of speech and noise. These models are trained using a paired corpus of clean and noisy recordings (teacher model). In this paper, we attempt to move away from the requirements of having supervised clean recordings for training the mask estimator. The models based on signal enhancement and beamforming using multi-channel linear prediction serve as the required mask estimate. In this way, the model training can also be carried out on real recordings of noisy speech rather than simulated ones alone done in a typical teacher model. Several experiments performed on noisy and reverberant environments in the CHiME-3 corpus as well as the REVERB challenge corpus highlight the effectiveness of the proposed approach. The ASR results for the proposed approach provide performances that are significantly better than a teacher model trained on an out-of-domain dataset and on par with the oracle mask estimators trained on the in-domain dataset.