 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Assembly State Reasoning from Action Recognition for Human-Robot Collaboration
Jun 18, 2026Human Action Recognition (HAR) is frequently investigated in Human-Robot Collaboration (HRC) research to understand what actions have been performed and hence the state of a collaborative task. Accurately tracking an assembly state from HAR is however not fully investigated, and in realistic scenarios is not a trivial task. This research systematically investigates and compares methods for tracking assembly state using action recognition inputs. Investigations using two diverse datasets and five state tracking approaches, including logic-based, Hidden Markov Model (HMM), and neural network (NN) methods, show that optimal approaches are not uniform across different tasks and that different methods fail under different circumstances. Testing is performed using both simulated inputs with varying noise levels and realistic inputs from a HAR model. Results show NN and HMM methods can perform well in tasks with limited variability, but for other scenarios logic-based approaches can be more robust. Methods which model expected action duration are also important for tasks with repeated actions where no additional sensing is provided.
Human-Guided Co-Manipulation of Carbon Fiber Plies
Jun 10, 2026The handling of flexible materials is a difficult task to fully automate due to the challenges caused by the deformability of these types of objects. Meanwhile, a fully manual process can be ergonomically challenging, tedious and inefficient. Thus, human-robot collaboration (HRC) and cooperative manipulation (co-manipulation) have received increasing interest in this field as they enable human involvement when needed while also improving productivity. To enable efficient co-manipulation and interaction between the human operator and the robot, different modalities and control methods are required. In this paper, we present and examine different control methods for co-manipulation of carbon fiber plies, evaluating the pros and cons of each method in a controlled setting. We propose that a multimodal combination of speech commands, wrist-tracking through vision, and force with compliant control would provide the best solution for complete and intuitive control of the task.
A Conversational Framework for Human-Robot Collaborative Manipulation with Distributed Generative AI models
Jun 04, 2026This paper presents a distributed conversational framework for human-robot collaborative manipulation that integrates local language and vision-language models (VLMs) with a Robot Operating System 2 (ROS 2)-based execution stack. Language understanding, visual grounding, orchestration, and motion execution run as separate ROS 2 nodes, enabling flexible deployment across distributed hardware while maintaining a responsive control loop. From free-form user commands, the system generates structured action requests for pick, place, and handover. It uses a VLM to return image-space targets, which are converted into metric robot-frame goals using depth and calibration. A web dashboard exposes intermediate intent and grounding overlays (pixel, depth, and robot-frame) and requires explicit operator confirmation before any motion is executed. Experiments on a Franka FR3 platform evaluate end-to-end task reliability and latency under increasing working table scene ambiguity and compare alternative LLM/VLM configurations in the same pipeline. Code and full documentation are available at [github.com/cogrob-tuni/franka-llm](https://github.com/cogrob-tuni/franka-llm).
Dynamic Neural Curiosity Enhances Learning Flexibility for Autonomous Goal Discovery
Nov 29, 2024



The autonomous learning of new goals in robotics remains a complex issue to address. Here, we propose a model where curiosity influence learning flexibility. To do so, this paper proposes to root curiosity and attention together by taking inspiration from the Locus Coeruleus-Norepinephrine system along with various cognitive processes such as cognitive persistence and visual habituation. We apply our approach by experimenting with a simulated robotic arm on a set of objects with varying difficulty. The robot first discovers new goals via bottom-up attention through motor babbling with an inhibition of return mechanism, then engage to the learning of goals due to neural activity arising within the curiosity mechanism. The architecture is modelled with dynamic neural fields and the learning of goals such as pushing the objects in diverse directions is supported by the use of forward and inverse models implemented by multi-layer perceptrons. The adoption of dynamic neural fields to model curiosity, habituation and persistence allows the robot to demonstrate various learning trajectories depending on the object. In addition, the approach exhibits interesting properties regarding the learning of similar goals as well as the continuous switch between exploration and exploitation.
AR-based interaction for safe human-robot collaborative manufacturing
Sep 06, 2019
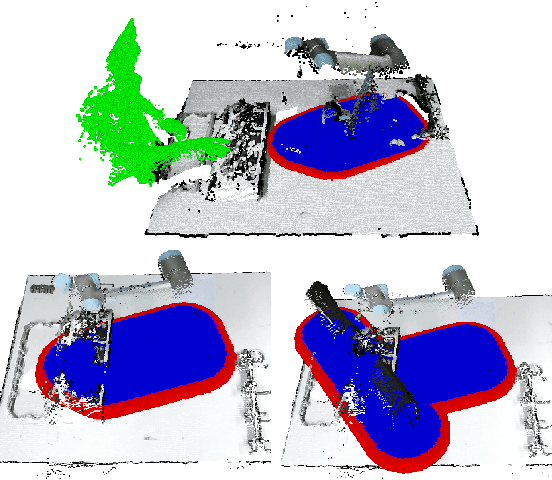
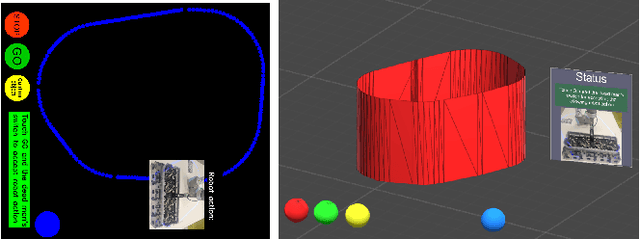
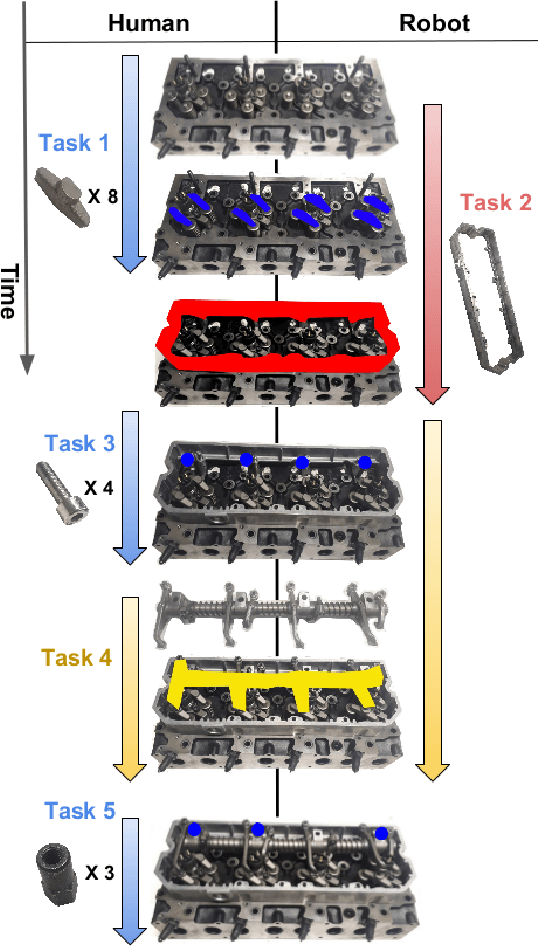
Industrial standards define safety requirements for Human-Robot Collaboration (HRC) in industrial manufacturing. The standards particularly require real-time monitoring and securing of the minimum protective distance between a robot and an operator. In this work, we propose a depth-sensor based model for workspace monitoring and an interactive Augmented Reality (AR) User Interface (UI) for safe HRC. The AR UI is implemented on two different hardware: a projector-mirror setup anda wearable AR gear (HoloLens). We experiment the workspace model and UIs for a realistic diesel motor assembly task. The AR-based interactive UIs provide 21-24% and 57-64% reduction in the task completion and robot idle time, respectively, as compared to a baseline without interaction and workspace sharing. However, subjective evaluations reveal that HoloLens based AR is not yet suitable for industrial manufacturing while the projector-mirror setup shows clear improvements in safety and work ergonomics.
Benchmarking 6D Object Pose Estimation for Robotics
Jun 06, 2019

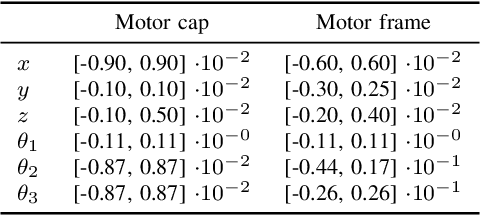
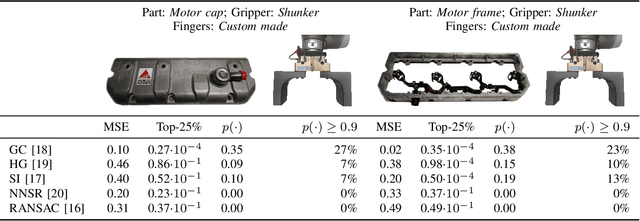
Benchmarking 6D object pose estimation for robotics is not straightforward as sufficient accuracy depends on many factors, e.g., the selected gripper, dimensions, weight and material of an object, grasping point, and the robot task itself. We formulate the problem as a successful grasp, i.e. for a fixed set of factors affecting the task, will the given pose estimate provide sufficiently good grasp to complete the task. The successful grasp is modelled in a probabilistic framework by sampling in the pose error space and executing the task and automatically detecting success or failure. Hours of sampling and thousands of samples are used to construct a non-parametric probability of a successful grasp given the pose residual. The framework is experimentally validated with real objects and assembly tasks and comparison of several state-of-the-art point cloud based 3D pose estimation methods.