 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-Anonymizing Text by Fingerprinting Language Generation
Jun 17, 2020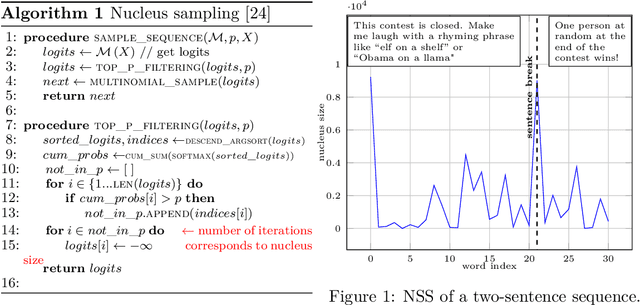
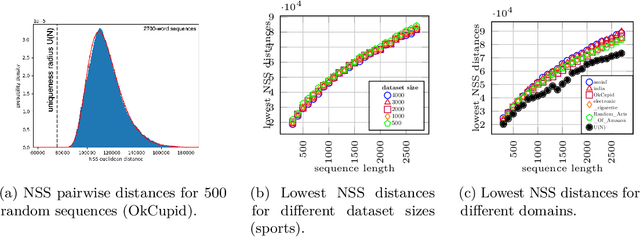
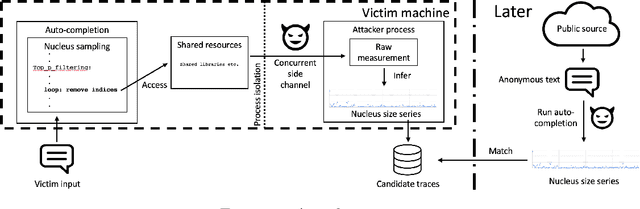
Components of machine learning systems are not (yet) perceived as security hotspots. Secure coding practices, such as ensuring that no execution paths depend on confidential inputs, have not yet been adopted by ML developers. We initiate the study of code security of ML systems by investigating how nucleus sampling---a popular approach for generating text, used for applications such as auto-completion---unwittingly leaks texts typed by users. Our main result is that the series of nucleus sizes for many natural English word sequences is a unique fingerprint. We then show how an attacker can infer typed text by measuring these fingerprints via a suitable side channel (e.g., cache access times), explain how this attack could help de-anonymize anonymous texts, and discuss defenses.
Humpty Dumpty: Controlling Word Meanings via Corpus Poisoning
Jan 14, 2020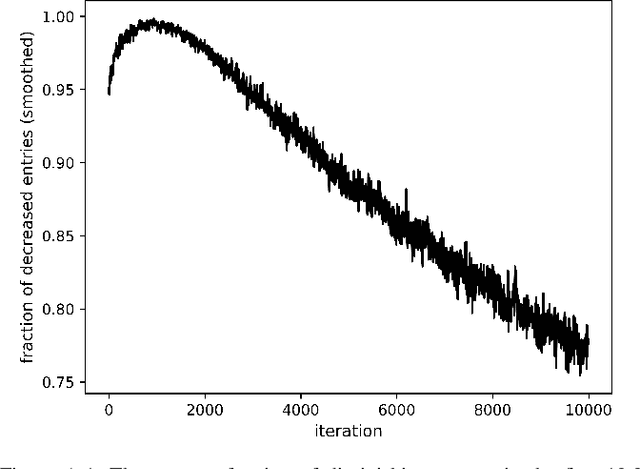
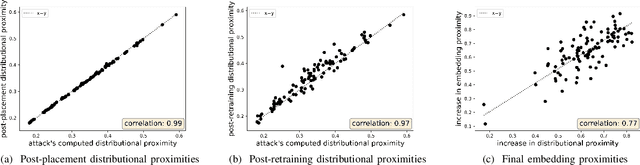
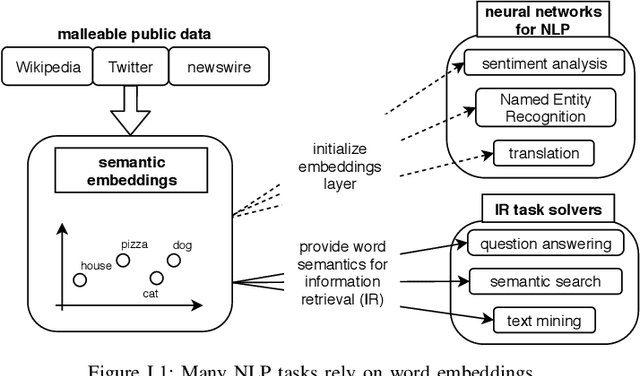
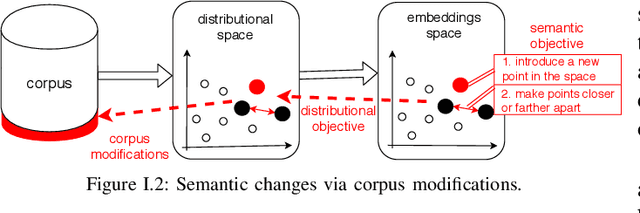
Word embeddings, i.e., low-dimensional vector representations such as GloVe and SGNS, encode word "meaning" in the sense that distances between words' vectors correspond to their semantic proximity. This enables transfer learning of semantics for a variety of natural language processing tasks. Word embeddings are typically trained on large public corpora such as Wikipedia or Twitter. We demonstrate that an attacker who can modify the corpus on which the embedding is trained can control the "meaning" of new and existing words by changing their locations in the embedding space. We develop an explicit expression over corpus features that serves as a proxy for distance between words and establish a causative relationship between its values and embedding distances. We then show how to use this relationship for two adversarial objectives: (1) make a word a top-ranked neighbor of another word, and (2) move a word from one semantic cluster to another. An attack on the embedding can affect diverse downstream tasks, demonstrating for the first time the power of data poisoning in transfer learning scenarios. We use this attack to manipulate query expansion in information retrieval systems such as resume search, make certain names more or less visible to named entity recognition models, and cause new words to be translated to a particular target word regardless of the language. Finally, we show how the attacker can generate linguistically likely corpus modifications, thus fooling defenses that attempt to filter implausible sentences from the corpus using a language model.
Are We Safe Yet? The Limitations of Distributional Features for Fake News Detection
Aug 26, 2019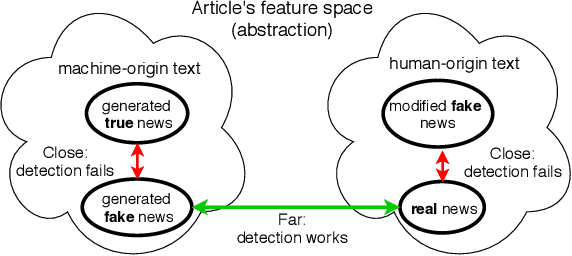


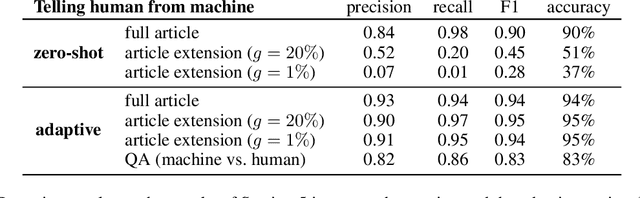
Automatic detection of fake news --- texts that are deceitful and misleading --- is a long outstanding and largely unsolved problem. Worse yet, recent developments in language modeling allow for the automatic generation of such texts. One approach that has recently gained attention detects these fake news using stylometry-based provenance, i.e. tracing a text's writing style back to its producing source and determining whether the source is malicious. This was shown to be highly effective under the assumption that legitimate text is produced by humans, and fake text is produced by a language model. In this work, we identify a fundamental problem with provenance-based approaches against attackers that auto-generate fake news: fake and legitimate texts can originate from nearly identical sources. First, a legitimate text might be auto-generated in a similar process to that of fake text, and second, attackers can automatically corrupt articles originating from legitimate human sources. We demonstrate these issues by simulating attacks in such settings, and find that the provenance approach fails to defend against them. Our findings highlight the importance of assessing the veracity of the text rather than solely relying on its style or source. We also open up a discussion on the types of benchmarks that should be used to evaluate neural fake news detectors.