 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumpty Dumpty: Controlling Word Meanings via Corpus Poisoning
Jan 14, 2020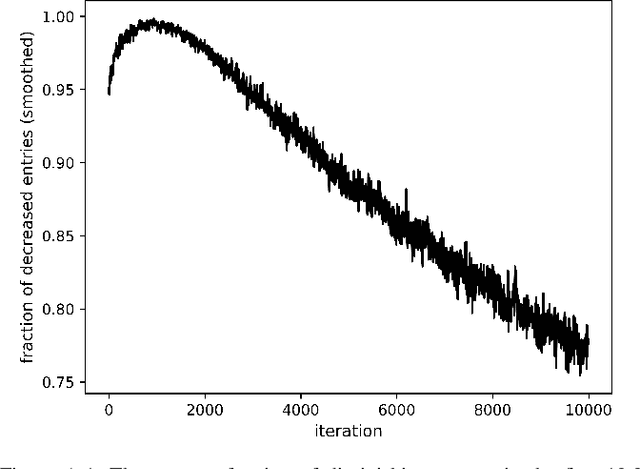
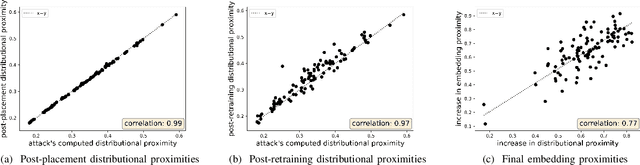
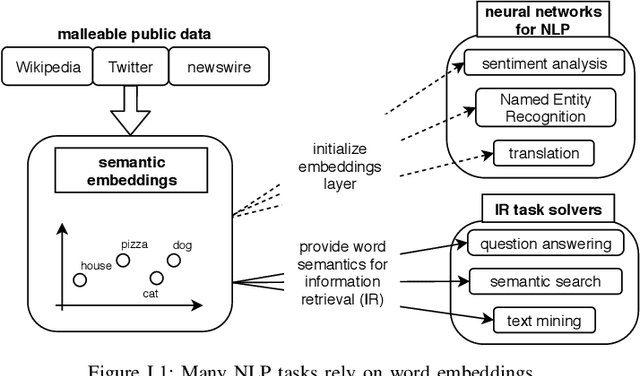
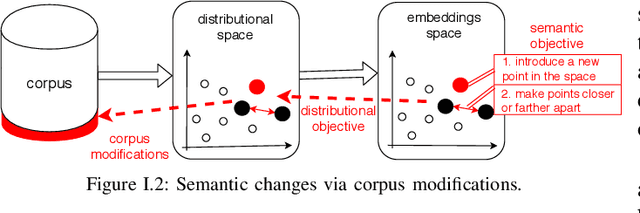
Word embeddings, i.e., low-dimensional vector representations such as GloVe and SGNS, encode word "meaning" in the sense that distances between words' vectors correspond to their semantic proximity. This enables transfer learning of semantics for a variety of natural language processing tasks. Word embeddings are typically trained on large public corpora such as Wikipedia or Twitter. We demonstrate that an attacker who can modify the corpus on which the embedding is trained can control the "meaning" of new and existing words by changing their locations in the embedding space. We develop an explicit expression over corpus features that serves as a proxy for distance between words and establish a causative relationship between its values and embedding distances. We then show how to use this relationship for two adversarial objectives: (1) make a word a top-ranked neighbor of another word, and (2) move a word from one semantic cluster to another. An attack on the embedding can affect diverse downstream tasks, demonstrating for the first time the power of data poisoning in transfer learning scenarios. We use this attack to manipulate query expansion in information retrieval systems such as resume search, make certain names more or less visible to named entity recognition models, and cause new words to be translated to a particular target word regardless of the language. Finally, we show how the attacker can generate linguistically likely corpus modifications, thus fooling defenses that attempt to filter implausible sentences from the corpus using a language model.