 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Tune or Not To Tune? Zero-shot Models for Legal Case Entailment
Feb 07, 2022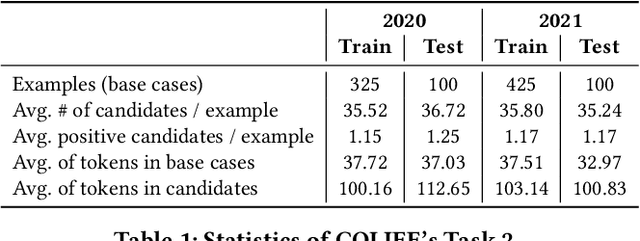
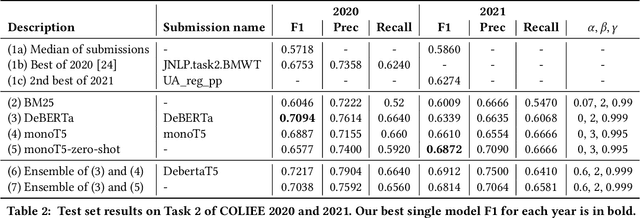
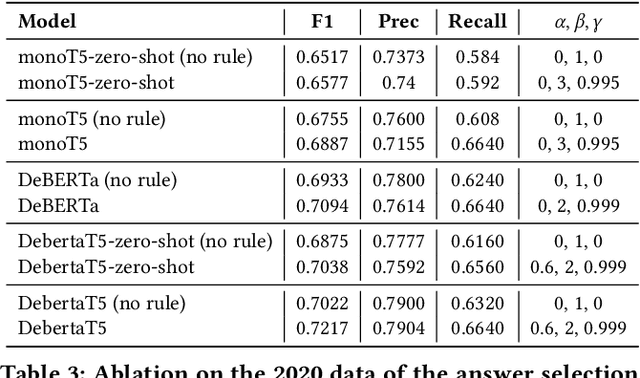
There has been mounting evidence that pretrained language models fine-tuned on large and diverse supervised datasets can transfer well to a variety of out-of-domain tasks. In this work, we investigate this transfer ability to the legal domain. For that, we participated in the legal case entailment task of COLIEE 2021, in which we use such models with no adaptations to the target domain. Our submissions achieved the highest scores, surpassing the second-best team by more than six percentage points. Our experiments confirm a counter-intuitive result in the new paradigm of pretrained language models: given limited labeled data, models with little or no adaptation to the target task can be more robust to changes in the data distribution than models fine-tuned on it. Code is available at https://github.com/neuralmind-ai/coliee.
Sequence-to-Sequence Models for Extracting Information from Registration and Legal Documents
Jan 14, 2022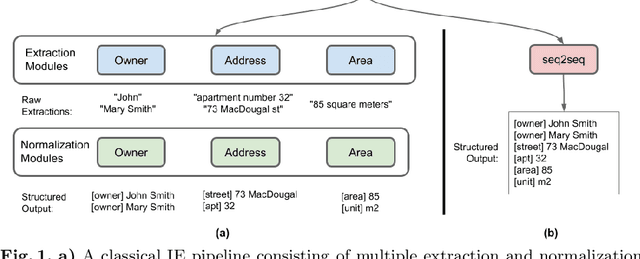
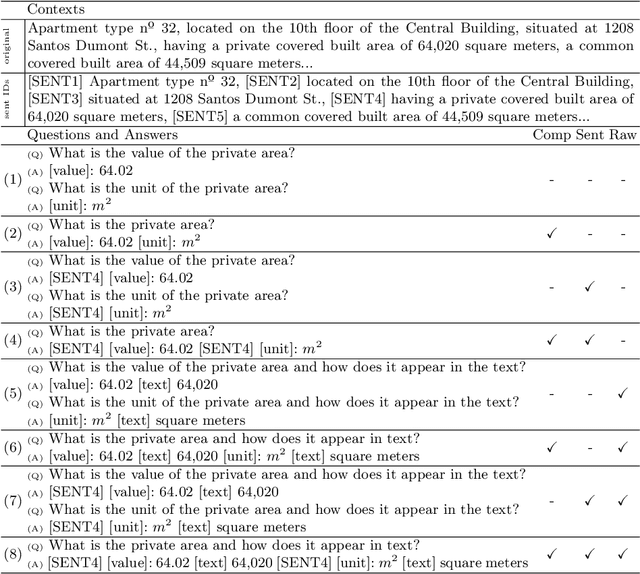

A typical information extraction pipeline consists of token- or span-level classification models coupled with a series of pre- and post-processing scripts. In a production pipeline, requirements often change, with classes being added and removed, which leads to nontrivial modifications to the source code and the possible introduction of bugs. In this work, we evaluate sequence-to-sequence models as an alternative to token-level classification methods for information extraction of legal and registration documents. We finetune models that jointly extract the information and generate the output already in a structured format. Post-processing steps are learned during training, thus eliminating the need for rule-based methods and simplifying the pipeline. Furthermore, we propose a novel method to align the output with the input text, thus facilitating system inspection and auditing. Our experiments on four real-world datasets show that the proposed method is an alternative to classical pipelines.
On the ability of monolingual models to learn language-agnostic representations
Sep 04, 2021
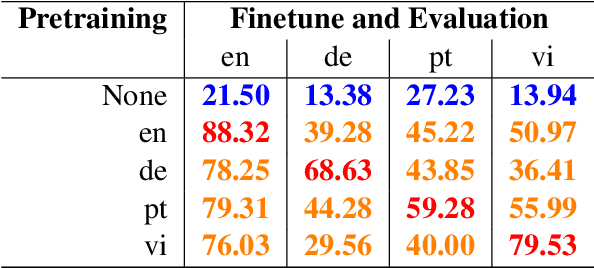
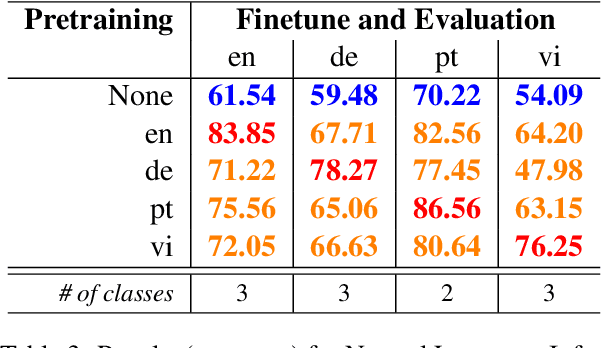
Pretrained multilingual models have become a de facto default approach for zero-shot cross-lingual transfer. Previous work has shown that these models are able to achieve cross-lingual representations when pretrained on two or more languages with shared parameters. In this work, we provide evidence that a model can achieve language-agnostic representations even when pretrained on a single language. That is, we find that monolingual models pretrained and finetuned on different languages achieve competitive performance compared to the ones that use the same target language. Surprisingly, the models show a similar performance on a same task regardless of the pretraining language. For example, models pretrained on distant languages such as German and Portuguese perform similarly on English tasks.
mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset
Aug 31, 2021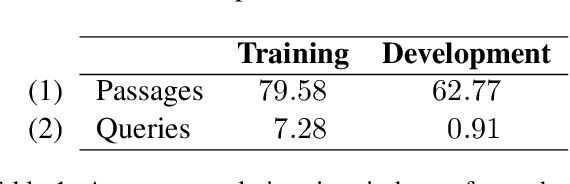
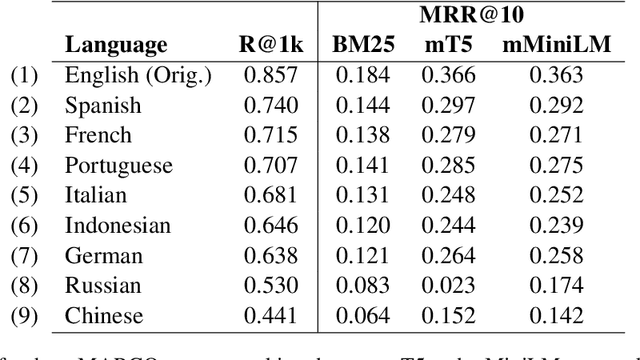
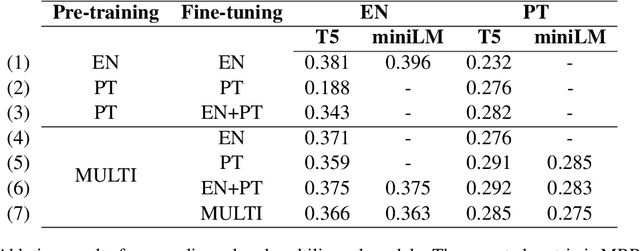
The MS MARCO ranking dataset has been widely used for training deep learning models for IR tasks, achieving considerable effectiveness on diverse zero-shot scenarios. However, this type of resource is scarce in other languages than English. In this work we present mMARCO, a multilingual version of the MS MARCO passage ranking dataset comprising 8 languages that was created using machine translation. We evaluated mMARCO by fine-tuning mono and multilingual re-ranking models on it. Experimental results demonstrate that multilingual models fine-tuned on our translated dataset achieve superior effectiveness than models fine-tuned on the original English version alone. Also, our distilled multilingual re-ranker is competitive with non-distilled models while having 5.4 times fewer parameters. The translated datasets as well as fine-tuned models are available at https://github.com/unicamp-dl/mMARCO.git.
A cost-benefit analysis of cross-lingual transfer methods
May 29, 2021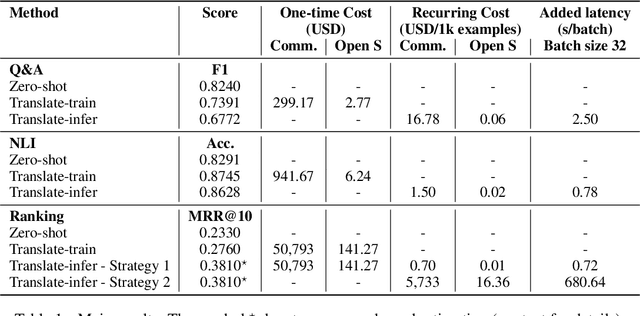
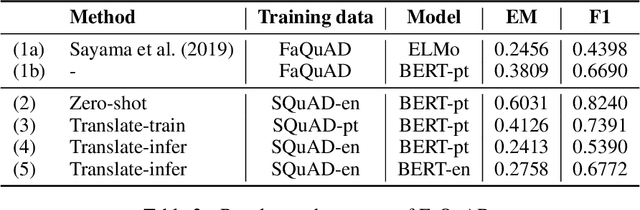
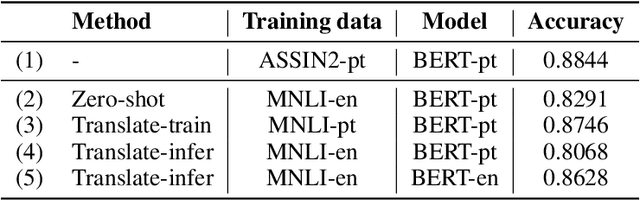
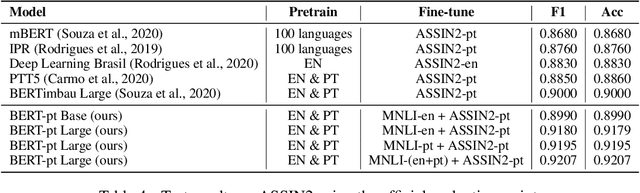
An effective method for cross-lingual transfer is to fine-tune a bilingual or multilingual model on a supervised dataset in one language and evaluating it on another language in a zero-shot manner. Translating examples at training time or inference time are also viable alternatives. However, there are costs associated with these methods that are rarely addressed in the literature. In this work, we analyze cross-lingual methods in terms of their effectiveness (e.g., accuracy), development and deployment costs, as well as their latencies at inference time. Our experiments on three tasks indicate that the best cross-lingual method is highly task-dependent. Finally, by combining zero-shot and translation methods, we achieve the state-of-the-art in two of the three datasets used in this work. Based on these results, we question the need for manually labeled training data in a target language. Code, models and translated datasets are available at https://github.com/unicamp-dl/cross-lingual-analysis
Yes, BM25 is a Strong Baseline for Legal Case Retrieval
Apr 26, 2021
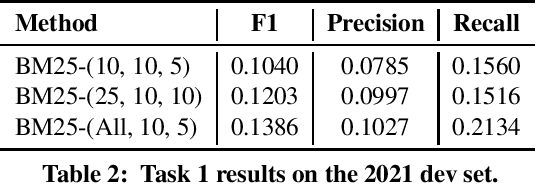
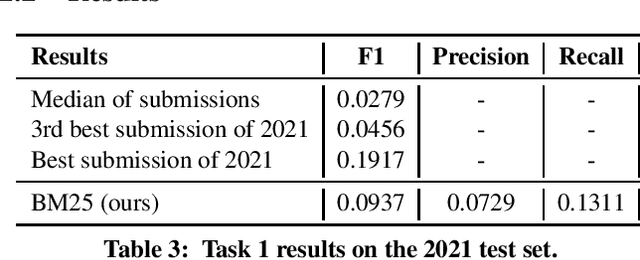
We describe our single submission to task 1 of COLIEE 2021. Our vanilla BM25 got second place, well above the median of submissions. Code is available at https://github.com/neuralmind-ai/coliee.
Investigating the Limitations of Transformers with Simple Arithmetic Tasks
Mar 02, 2021
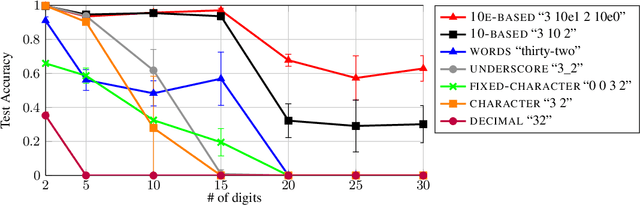
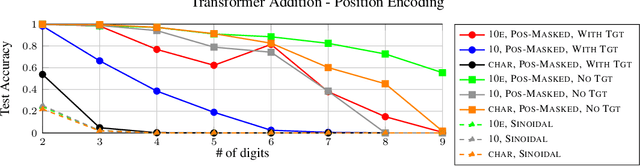
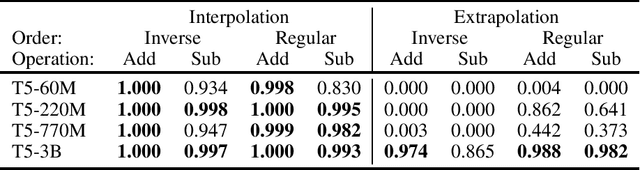
The ability to perform arithmetic tasks is a remarkable trait of human intelligence and might form a critical component of more complex reasoning tasks. In this work, we investigate if the surface form of a number has any influence on how sequence-to-sequence language models learn simple arithmetic tasks such as addition and subtraction across a wide range of values. We find that how a number is represented in its surface form has a strong influence on the model's accuracy. In particular, the model fails to learn addition of five-digit numbers when using subwords (e.g., "32"), and it struggles to learn with character-level representations (e.g., "3 2"). By introducing position tokens (e.g., "3 10e1 2"), the model learns to accurately add and subtract numbers up to 60 digits. We conclude that modern pretrained language models can easily learn arithmetic from very few examples, as long as we use the proper surface representation. This result bolsters evidence that subword tokenizers and positional encodings are components in current transformer designs that might need improvement. Moreover, we show that regardless of the number of parameters and training examples, models cannot learn addition rules that are independent of the length of the numbers seen during training. Code to reproduce our experiments is available at https://github.com/castorini/transformers-arithmetic
Pyserini: An Easy-to-Use Python Toolkit to Support Replicable IR Research with Sparse and Dense Representations
Feb 19, 2021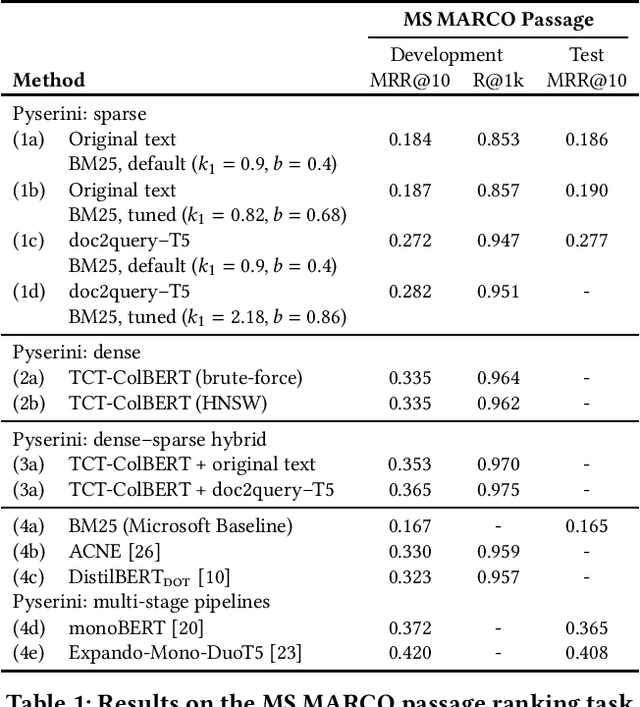
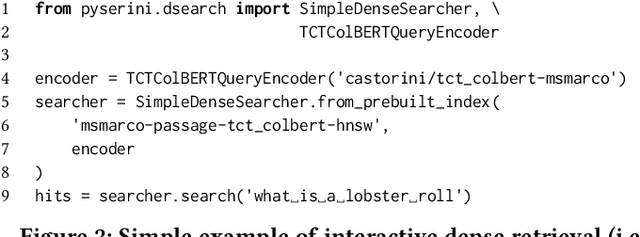
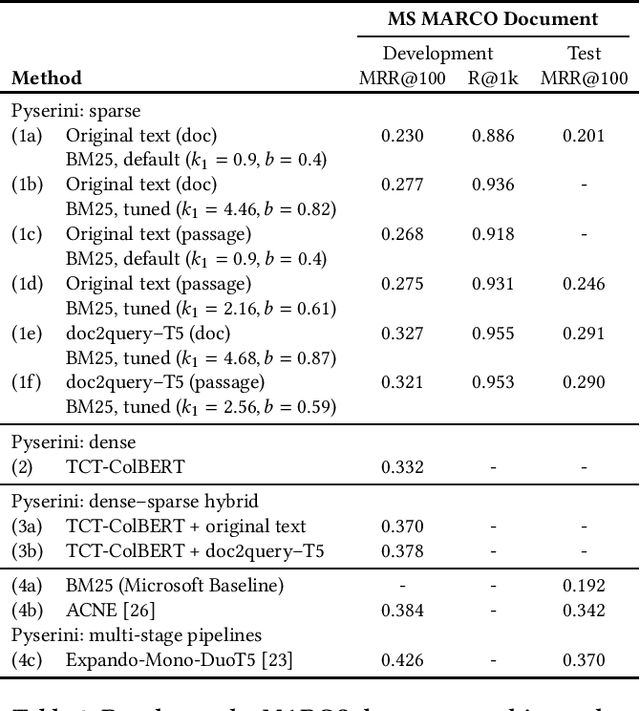
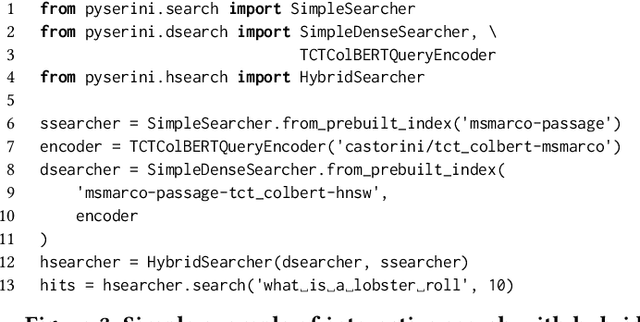
Pyserini is an easy-to-use Python toolkit that supports replicable IR research by providing effective first-stage retrieval in a multi-stage ranking architecture. Our toolkit is self-contained as a standard Python package and comes with queries, relevance judgments, pre-built indexes, and evaluation scripts for many commonly used IR test collections. We aim to support, out of the box, the entire research lifecycle of efforts aimed at improving ranking with modern neural approaches. In particular, Pyserini supports sparse retrieval (e.g., BM25 scoring using bag-of-words representations), dense retrieval (e.g., nearest-neighbor search on transformer-encoded representations), as well as hybrid retrieval that integrates both approaches. This paper provides an overview of toolkit features and presents empirical results that illustrate its effectiveness on two popular ranking tasks. We also describe how our group has built a culture of replicability through shared norms and tools that enable rigorous automated testing.
The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
Jan 14, 2021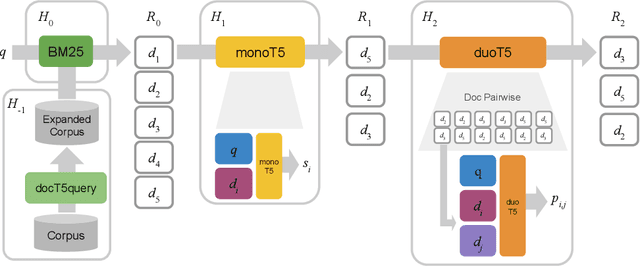
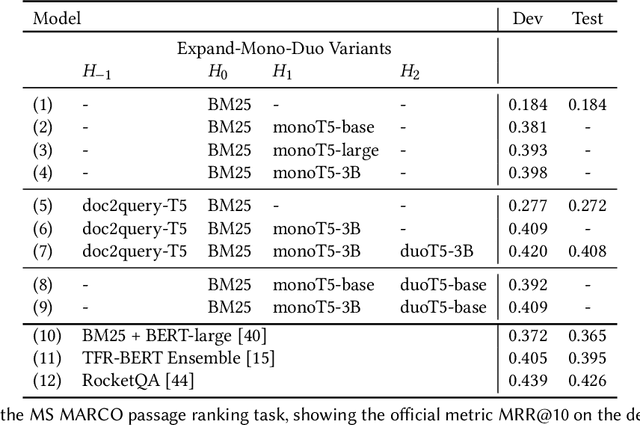
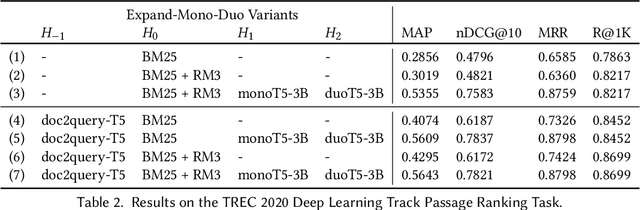
We propose a design pattern for tackling text ranking problems, dubbed "Expando-Mono-Duo", that has been empirically validated for a number of ad hoc retrieval tasks in different domains. At the core, our design relies on pretrained sequence-to-sequence models within a standard multi-stage ranking architecture. "Expando" refers to the use of document expansion techniques to enrich keyword representations of texts prior to inverted indexing. "Mono" and "Duo" refer to components in a reranking pipeline based on a pointwise model and a pairwise model that rerank initial candidates retrieved using keyword search. We present experimental results from the MS MARCO passage and document ranking tasks, the TREC 2020 Deep Learning Track, and the TREC-COVID challenge that validate our design. In all these tasks, we achieve effectiveness that is at or near the state of the art, in some cases using a zero-shot approach that does not exploit any training data from the target task. To support replicability, implementations of our design pattern are open-sourced in the Pyserini IR toolkit and PyGaggle neural reranking library.
Scientific Claim Verification with VERT5ERINI
Oct 22, 2020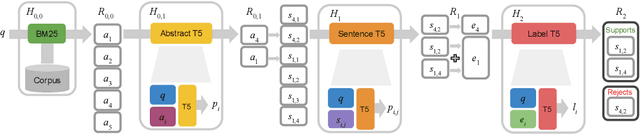



This work describes the adaptation of a pretrained sequence-to-sequence model to the task of scientific claim verification in the biomedical domain. We propose VERT5ERINI that exploits T5 for abstract retrieval, sentence selection and label prediction, which are three critical sub-tasks of claim verification. We evaluate our pipeline on SCIFACT, a newly curated dataset that requires models to not just predict the veracity of claims but also provide relevant sentences from a corpus of scientific literature that support this decision. Empirically, our pipeline outperforms a strong baseline in each of the three steps. Finally, we show VERT5ERINI's ability to generalize to two new datasets of COVID-19 claims using evidence from the ever-expanding CORD-19 corpus.