 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Synthesis of Sparse and Semi-Structured Mixed-Type Data
Mar 02, 2026Synthetic data generation is a critical capability for data sharing, privacy compliance, system benchmarking and test data provisioning. Existing methods assume dense, fixed-schema tabular data, yet this assumption is increasingly at odds with modern data systems - from document databases, REST APIs to data lakes - which store and exchange data in sparse, semi-structured formats like JSON. Applying existing tabular methods to such data requires flattening of nested data into wide, sparse tables which scales poorly. We present Origami, an autoregressive transformer-based architecture that tokenizes data records, including nested objects and variable length arrays, into sequences of key, value and structural tokens. This representation natively handles sparsity, mixed types and hierarchical structure without flattening or imputation. Origami outperforms baselines spanning GAN, VAE, diffusion and autoregressive architectures on fidelity, utility and detection metrics across nearly all settings, while maintaining high privacy scores. On semi-structured datasets with up to 38% sparsity, baseline synthesizers either fail to scale or degrade substantially, while Origami maintains high-fidelity synthesis that is harder to distinguish from real data. To the best of our knowledge, Origami is the first architecture capable of natively modeling and generating semi-structured data end-to-end.
LEAF: Knowledge Distillation of Text Embedding Models with Teacher-Aligned Representations
Sep 16, 2025We present LEAF ("Lightweight Embedding Alignment Framework"), a knowledge distillation framework for text embedding models. A key distinguishing feature is that our distilled leaf models are aligned to their teacher. In the context of information retrieval, this allows for flexible asymmetric architectures where documents are encoded with the larger teacher model, while queries can be served with the smaller leaf models. We also show that leaf models automatically inherit MRL and robustness to output quantization whenever these properties are present in the teacher model, without explicitly training for them. To demonstrate the capability of our framework we publish leaf-ir, a 23M parameters information retrieval oriented text embedding model trained using LEAF, which sets a new state-of-the-art (SOTA) on BEIR, ranking #1 on the public leaderboard for this benchmark and for models of its size. When run in asymmetric mode, its retrieval performance is further increased. Our scheme is however not restricted to the information retrieval setting, and we demonstrate its wider applicability by synthesizing the multi-task leaf-mt model. This also sets a new SOTA, ranking #1 on the public MTEB v2 (English) leaderboard for its size. LEAF is applicable to black-box models and in contrast to other embedding model training frameworks, it does not require judgments nor hard negatives, and training can be conducted using small batch sizes. Thus, dataset and training infrastructure requirements for our framework are modest. We make our models publicly available under a permissive Apache 2.0 license.
ORIGAMI: A generative transformer architecture for predictions from semi-structured data
Dec 23, 2024



Despite the popularity and widespread use of semi-structured data formats such as JSON, end-to-end supervised learning applied directly to such data remains underexplored. We present ORIGAMI (Object RepresentatIon via Generative Autoregressive ModellIng), a transformer-based architecture that directly processes nested key/value pairs while preserving their hierarchical semantics. Our key technical contributions include: (1) a structure-preserving tokenizer, (2) a novel key/value position encoding scheme, and (3) a grammar-constrained training and inference framework that ensures valid outputs and accelerates training convergence. These enhancements enable efficient end-to-end modeling of semi-structured data. By reformulating classification as next-token prediction, ORIGAMI naturally handles both single-label and multi-label tasks without architectural modifications. Empirical evaluation across diverse domains demonstrates ORIGAMI's effectiveness: On standard tabular benchmarks converted to JSON, ORIGAMI remains competitive with classical and state-of-the-art approaches. On native JSON datasets, we outperform baselines on multi-label classification and specialized models such as convolutional and graph neural networks on a code classification task. Through extensive ablation studies, we validate the impact of each architectural component and establish ORIGAMI as a robust framework for end-to-end learning on semi-structured data.
Multi-Vehicle Trajectory Optimisation On Road Networks
Oct 05, 2018

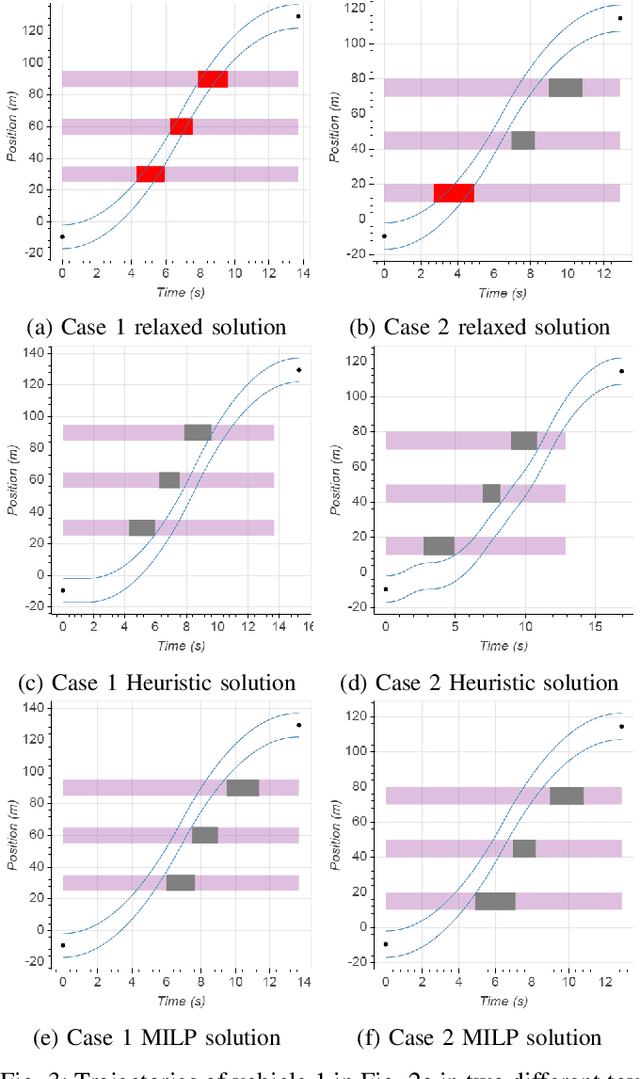

This paper addresses the problem of planning time-optimal trajectories for multiple cooperative agents along specified paths through a static road network. Vehicle interactions at intersections create non-trivial decisions, with complex flow-on effects for subsequent interactions. A globally optimal, minimum time trajectory is found for all vehicles using Mixed Integer Linear Programming (MILP). Computational performance is improved by minimising binary variables using iteratively applied targeted collision constraints, and efficient goal constraints. Simulation results in an open-pit mining scenario compare the proposed method against a fast heuristic method and a reactive approach based on site practices. The heuristic is found to scale better with problem size while the MILP is able to avoid local minima.
Weekly maintenance scheduling using exact and genetic methods
Oct 17, 2016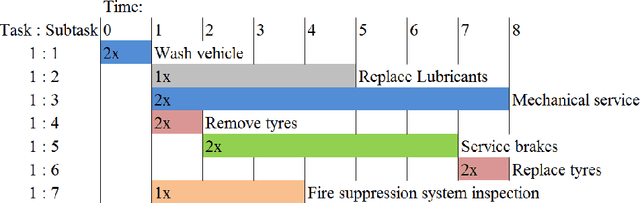

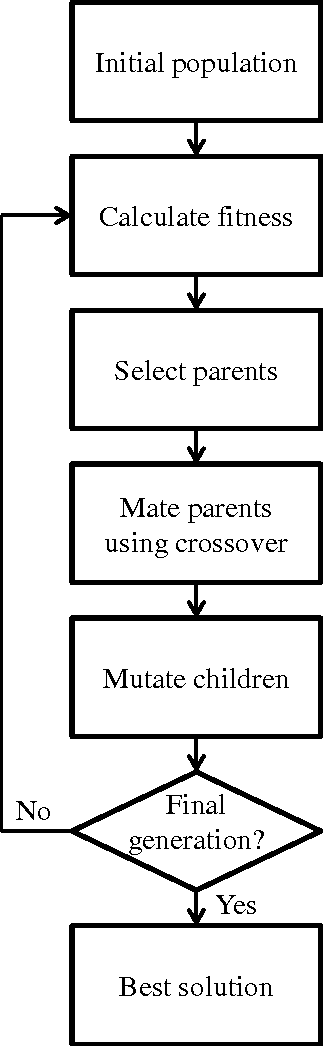
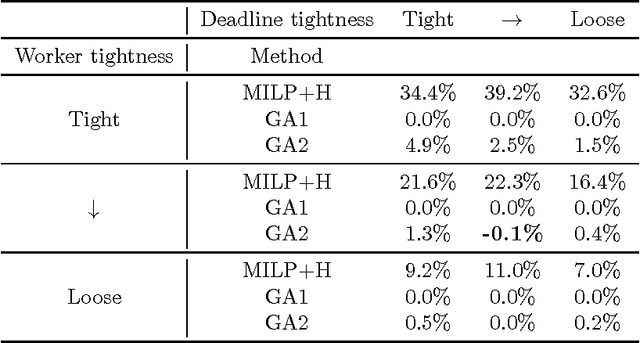
The weekly maintenance schedule specifies when maintenance activities should be performed on the equipment, taking into account the availability of workers and maintenance bays, and other operational constraints. The current approach to generating this schedule is labour intensive and requires coordination between the maintenance schedulers and operations staff to minimise its impact on the operation of the mine. This paper presents methods for automatically generating this schedule from the list of maintenance tasks to be performed, the availability roster of the maintenance staff, and time windows in which each piece of equipment is available for maintenance. Both Mixed-Integer Linear Programming (MILP) and genetic algorithms are evaluated, with the genetic algorithm shown to significantly outperform the MILP. Two fitness functions for the genetic algorithm are also examined, with a linear fitness function outperforming an inverse fitness function by up to 5% for the same calculation time. The genetic algorithm approach is computationally fast, allowing the schedule to be rapidly recalculated in response to unexpected delays and breakdowns.