 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Actions Teach You to Think: Reasoning-Action Synergy via Reinforcement Learning in Conversational Agents
Dec 12, 2025Supervised fine-tuning (SFT) has emerged as one of the most effective ways to improve the performance of large language models (LLMs) in downstream tasks. However, SFT can have difficulty generalizing when the underlying data distribution changes, even when the new data does not fall completely outside the training domain. Recent reasoning-focused models such as o1 and R1 have demonstrated consistent gains over their non-reasoning counterparts, highlighting the importance of reasoning for improved generalization and reliability. However, collecting high-quality reasoning traces for SFT remains challenging -- annotations are costly, subjective, and difficult to scale. To address this limitation, we leverage Reinforcement Learning (RL) to enable models to learn reasoning strategies directly from task outcomes. We propose a pipeline in which LLMs generate reasoning steps that guide both the invocation of tools (e.g., function calls) and the final answer generation for conversational agents. Our method employs Group Relative Policy Optimization (GRPO) with rewards designed around tool accuracy and answer correctness, allowing the model to iteratively refine its reasoning and actions. Experimental results demonstrate that our approach improves both the quality of reasoning and the precision of tool invocations, achieving a 1.5% relative improvement over the SFT model (trained without explicit thinking) and a 40% gain compared to the base of the vanilla Qwen3-1.7B model. These findings demonstrate the promise of unifying reasoning and action learning through RL to build more capable and generalizable conversational agents.
Pre-Act: Multi-Step Planning and Reasoning Improves Acting in LLM Agents
May 15, 2025The ReAct (Reasoning + Action) capability in large language models (LLMs) has become the foundation of modern agentic systems. Recent LLMs, such as DeepSeek-R1 and OpenAI o1/o3, exemplify this by emphasizing reasoning through the generation of ample intermediate tokens, which help build a strong premise before producing the final output tokens. In this paper, we introduce Pre-Act, a novel approach that enhances the agent's performance by creating a multi-step execution plan along with the detailed reasoning for the given user input. This plan incrementally incorporates previous steps and tool outputs, refining itself after each step execution until the final response is obtained. Our approach is applicable to both conversational and non-conversational agents. To measure the performance of task-oriented agents comprehensively, we propose a two-level evaluation framework: (1) turn level and (2) end-to-end. Our turn-level evaluation, averaged across five models, shows that our approach, Pre-Act, outperforms ReAct by 70% in Action Recall on the Almita dataset. While this approach is effective for larger models, smaller models crucial for practical applications, where latency and cost are key constraints, often struggle with complex reasoning tasks required for agentic systems. To address this limitation, we fine-tune relatively small models such as Llama 3.1 (8B & 70B) using the proposed Pre-Act approach. Our experiments show that the fine-tuned 70B model outperforms GPT-4, achieving a 69.5% improvement in action accuracy (turn-level) and a 28% improvement in goal completion rate (end-to-end) on the Almita (out-of-domain) dataset.
REFINE on Scarce Data: Retrieval Enhancement through Fine-Tuning via Model Fusion of Embedding Models
Oct 16, 2024



Retrieval augmented generation (RAG) pipelines are commonly used in tasks such as question-answering (QA), relying on retrieving relevant documents from a vector store computed using a pretrained embedding model. However, if the retrieved context is inaccurate, the answers generated using the large language model (LLM) may contain errors or hallucinations. Although pretrained embedding models have advanced, adapting them to new domains remains challenging. Fine-tuning is a potential solution, but industry settings often lack the necessary fine-tuning data. To address these challenges, we propose REFINE, a novel technique that generates synthetic data from available documents and then uses a model fusion approach to fine-tune embeddings for improved retrieval performance in new domains, while preserving out-of-domain capability. We conducted experiments on the two public datasets: SQUAD and RAG-12000 and a proprietary TOURISM dataset. Results demonstrate that even the standard fine-tuning with the proposed data augmentation technique outperforms the vanilla pretrained model. Furthermore, when combined with model fusion, the proposed approach achieves superior performance, with a 5.76% improvement in recall on the TOURISM dataset, and 6.58 % and 0.32% enhancement on SQUAD and RAG-12000 respectively.
A Learning Approach to Natural Language Understanding
Jun 01, 1994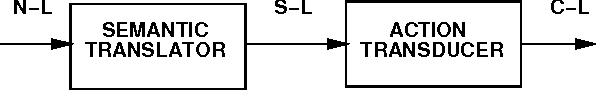
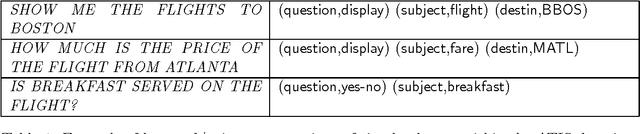
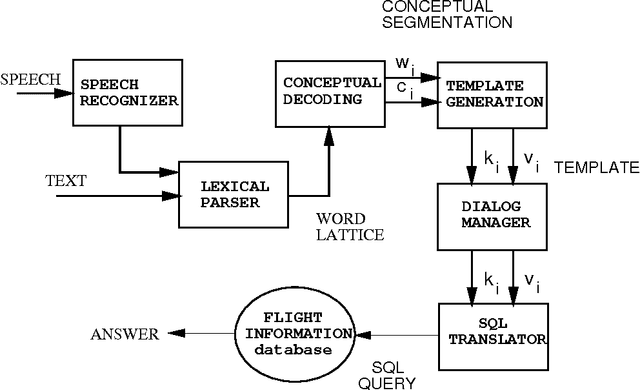

In this paper we propose a learning paradigm for the problem of understanding spoken language. The basis of the work is in a formalization of the understanding problem as a communication problem. This results in the definition of a stochastic model of the production of speech or text starting from the meaning of a sentence. The resulting understanding algorithm consists in a Viterbi maximization procedure, analogous to that commonly used for recognizing speech. The algorithm was implemented for building
* 18 pages, Latex file + compressed figures