 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Contrasting Quasi-Clique Patterns
Oct 03, 2018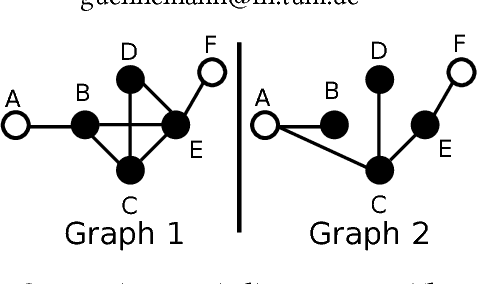
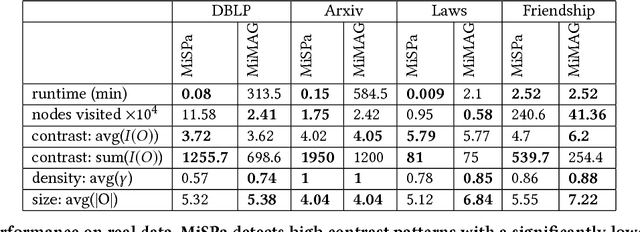
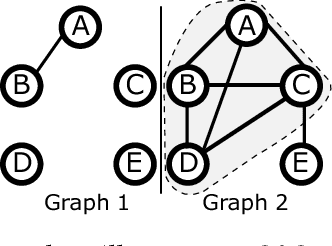
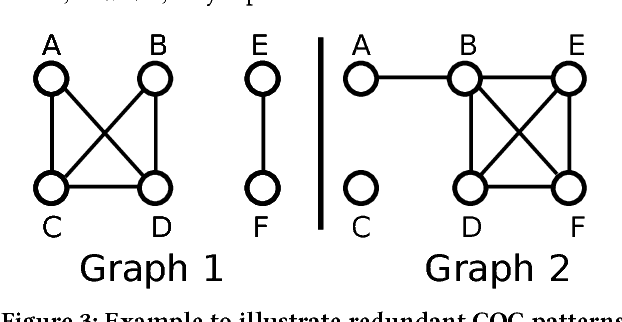
Mining dense quasi-cliques is a well-known clustering task with applications ranging from social networks over collaboration graphs to document analysis. Recent work has extended this task to multiple graphs; i.e. the goal is to find groups of vertices highly dense among multiple graphs. In this paper, we argue that in a multi-graph scenario the sparsity is valuable for knowledge extraction as well. We introduce the concept of contrasting quasi-clique patterns: a collection of vertices highly dense in one graph but highly sparse (i.e. less connected) in a second graph. Thus, these patterns specifically highlight the difference/contrast between the considered graphs. Based on our novel model, we propose an algorithm that enables fast computation of contrasting patterns by exploiting intelligent traversal and pruning techniques. We showcase the potential of contrasting patterns on a variety of synthetic and real-world datasets.
On the Phase Transition of Finding a Biclique in a larger Bipartite Graph
Sep 19, 2016



We report on the phase transition of finding a complete subgraph, of specified dimensions, in a bipartite graph. Finding a complete subgraph in a bipartite graph is a problem that has growing attention in several domains, including bioinformatics, social network analysis and domain clustering. A key step for a successful phase transition study is identifying a suitable order parameter, when none is known. To this purpose, we have applied a decision tree classifier to real-world instances of this problem, in order to understand what problem features separate an instance that is hard to solve from those that is not. We have successfully identified one such order parameter and with it the phase transition of finding a complete bipartite subgraph of specified dimensions. Our phase transition study shows an easy-to-hard-to-easy-to-hard-to-easy pattern. Further, our results indicate that the hardest instances are in a region where it is more likely that the corresponding bipartite graph will have a complete subgraph of specified dimensions, a positive answer. By contrast, instances with a negative answer are more likely to appear in a region where the computational cost is negligible. This behaviour is remarkably similar for problems of a number of different sizes.