 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Bayesian Density Analysis
Oct 03, 2018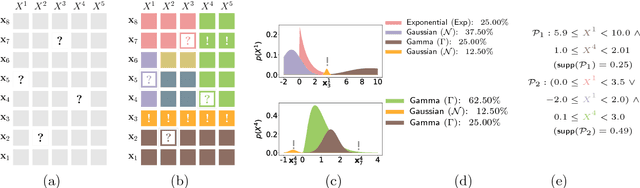
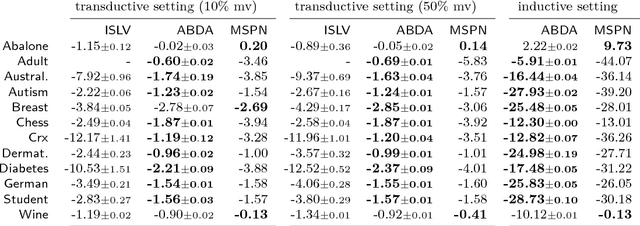

Making sense of a dataset in an automatic and unsupervised fashion is a challenging problem in statistics and AI. Classical approaches for density estimation are usually not flexible enough to deal with the uncertainty inherent to real-world data: they are often restricted to fixed latent interaction models and homogeneous likelihoods; they are sensitive to missing, corrupt and anomalous data; moreover, their expressiveness generally comes at the price of intractable inference. As a result, supervision from statisticians is usually needed to find the right model for the data. However, as domain experts do not necessarily have to be experts in statistics, we propose Automatic Bayesian Density Analysis (ABDA) to make density estimation accessible at large. ABDA automates the selection of adequate likelihood models from arbitrarily rich dictionaries while modeling their interactions via a deep latent structure adaptively learned from data as a sum-product network. ABDA casts uncertainty estimation at these local and global levels into a joint Bayesian inference problem, providing robust and yet tractable inference. Extensive empirical evidence shows that ABDA is a suitable tool for automatic exploratory analysis of heterogeneous tabular data, allowing for missing value estimation, statistical data type and likelihood discovery, anomaly detection and dependency structure mining, on top of providing accurate density estimation.
Minimal Random Code Learning: Getting Bits Back from Compressed Model Parameters
Sep 30, 2018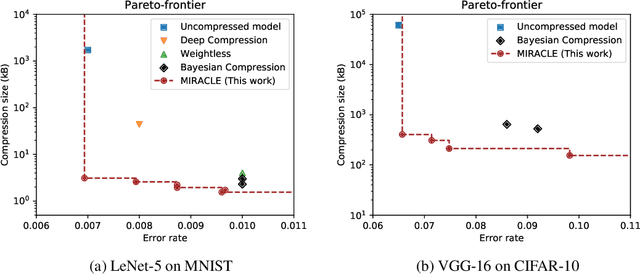
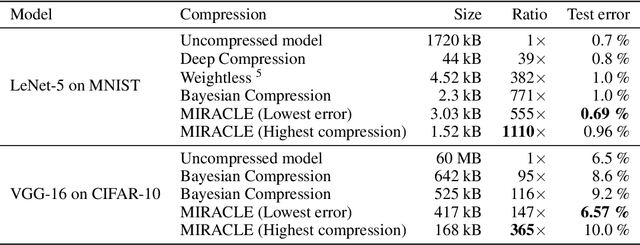
While deep neural networks are a highly successful model class, their large memory footprint puts considerable strain on energy consumption, communication bandwidth, and storage requirements. Consequently, model size reduction has become an utmost goal in deep learning. A typical approach is to train a set of deterministic weights, while applying certain techniques such as pruning and quantization, in order that the empirical weight distribution becomes amenable to Shannon-style coding schemes. However, as shown in this paper, relaxing weight determinism and using a full variational distribution over weights allows for more efficient coding schemes and consequently higher compression rates. In particular, following the classical bits-back argument, we encode the network weights using a random sample, requiring only a number of bits corresponding to the Kullback-Leibler divergence between the sampled variational distribution and the encoding distribution. By imposing a constraint on the Kullback-Leibler divergence, we are able to explicitly control the compression rate, while optimizing the expected loss on the training set. The employed encoding scheme can be shown to be close to the optimal information-theoretical lower bound, with respect to the employed variational family. Our method sets new state-of-the-art in neural network compression, as it strictly dominates previous approaches in a Pareto sense: On the benchmarks LeNet-5/MNIST and VGG-16/CIFAR-10, our approach yields the best test performance for a fixed memory budget, and vice versa, it achieves the highest compression rates for a fixed test performance.
Learning Deep Mixtures of Gaussian Process Experts Using Sum-Product Networks
Sep 12, 2018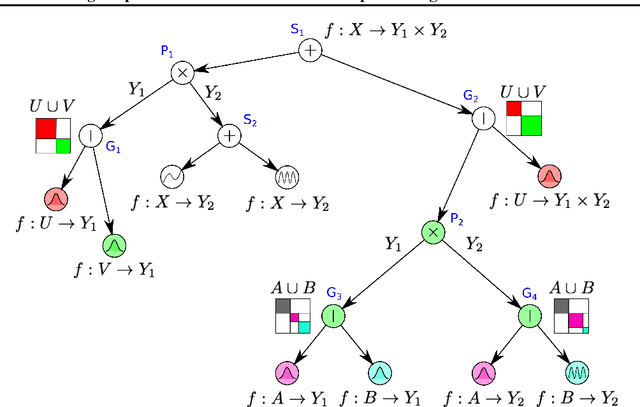
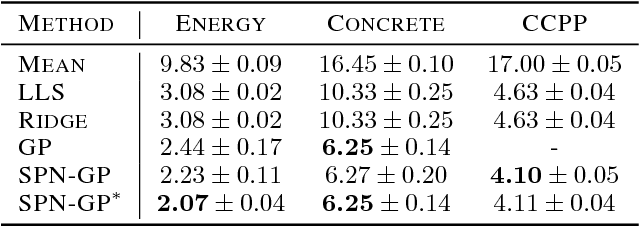
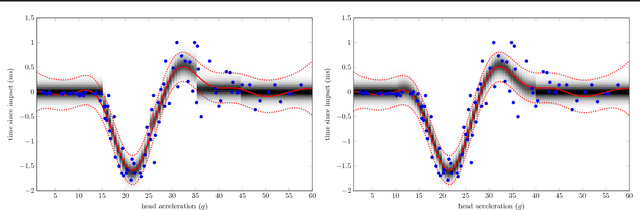
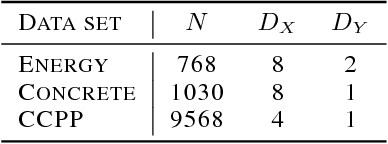
While Gaussian processes (GPs) are the method of choice for regression tasks, they also come with practical difficulties, as inference cost scales cubic in time and quadratic in memory. In this paper, we introduce a natural and expressive way to tackle these problems, by incorporating GPs in sum-product networks (SPNs), a recently proposed tractable probabilistic model allowing exact and efficient inference. In particular, by using GPs as leaves of an SPN we obtain a novel flexible prior over functions, which implicitly represents an exponentially large mixture of local GPs. Exact and efficient posterior inference in this model can be done in a natural interplay of the inference mechanisms in GPs and SPNs. Thereby, each GP is -- similarly as in a mixture of experts approach -- responsible only for a subset of data points, which effectively reduces inference cost in a divide and conquer fashion. We show that integrating GPs into the SPN framework leads to a promising probabilistic regression model which is: (1) computational and memory efficient, (2) allows efficient and exact posterior inference, (3) is flexible enough to mix different kernel functions, and (4) naturally accounts for non-stationarities in time series. In a variate of experiments, we show that the SPN-GP model can learn input dependent parameters and hyper-parameters and is on par with or outperforms the traditional GPs as well as state of the art approximations on real-world data.
Probabilistic Deep Learning using Random Sum-Product Networks
Jun 22, 2018
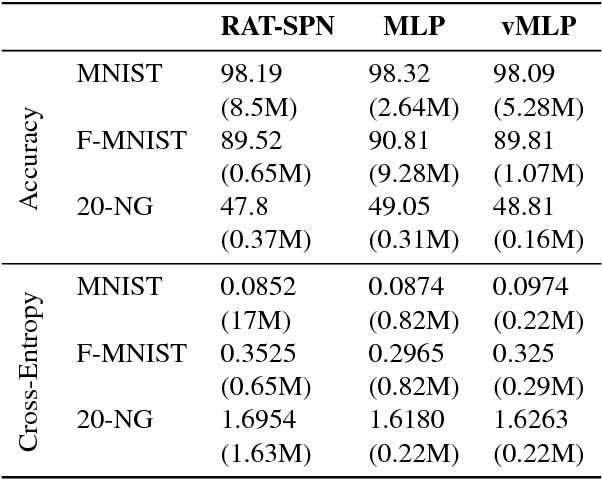
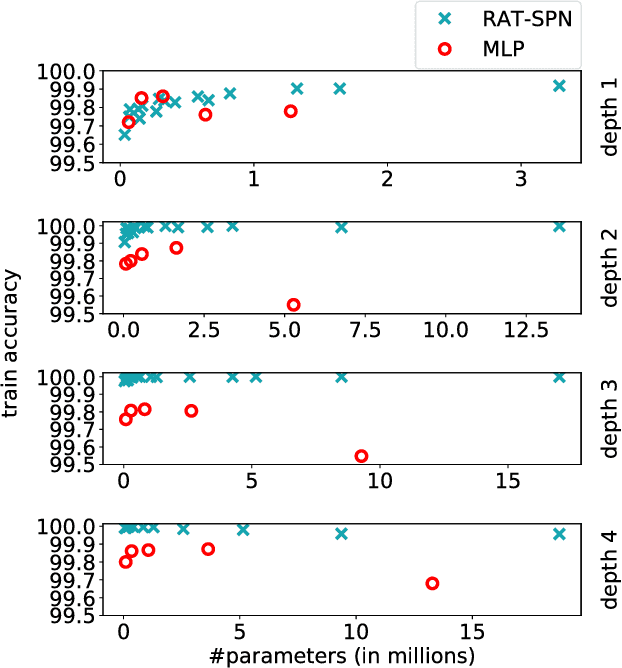
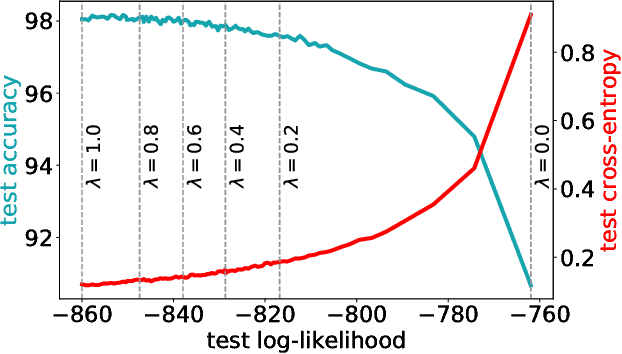
The need for consistent treatment of uncertainty has recently triggered increased interest in probabilistic deep learning methods. However, most current approaches have severe limitations when it comes to inference, since many of these models do not even permit to evaluate exact data likelihoods. Sum-product networks (SPNs), on the other hand, are an excellent architecture in that regard, as they allow to efficiently evaluate likelihoods, as well as arbitrary marginalization and conditioning tasks. Nevertheless, SPNs have not been fully explored as serious deep learning models, likely due to their special structural requirements, which complicate learning. In this paper, we make a drastic simplification and use random SPN structures which are trained in a "classical deep learning manner", i.e. employing automatic differentiation, SGD, and GPU support. The resulting models, called RAT-SPNs, yield prediction results comparable to deep neural networks, while still being interpretable as generative model and maintaining well-calibrated uncertainties. This property makes them highly robust under missing input features and enables them to naturally detect outliers and peculiar samples.
Safe Semi-Supervised Learning of Sum-Product Networks
Oct 10, 2017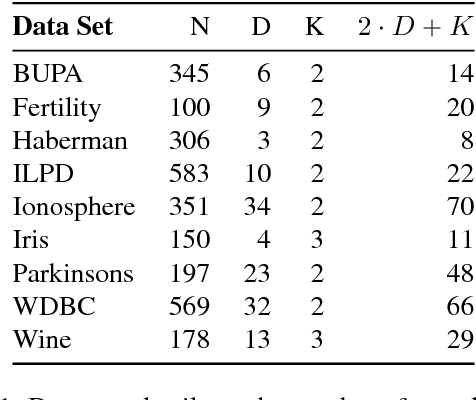
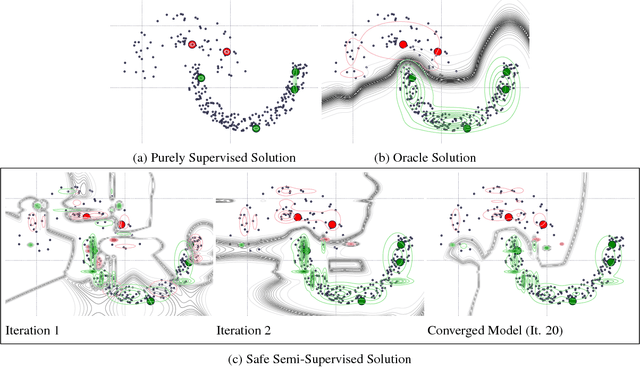
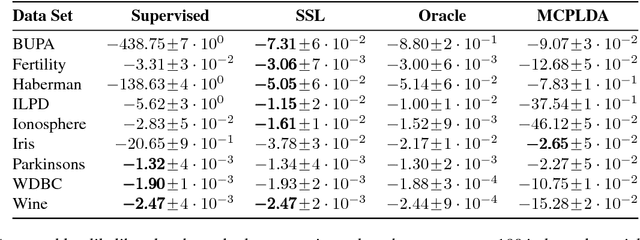
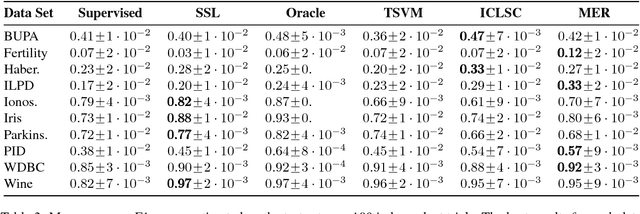
In several domains obtaining class annotations is expensive while at the same time unlabelled data are abundant. While most semi-supervised approaches enforce restrictive assumptions on the data distribution, recent work has managed to learn semi-supervised models in a non-restrictive regime. However, so far such approaches have only been proposed for linear models. In this work, we introduce semi-supervised parameter learning for Sum-Product Networks (SPNs). SPNs are deep probabilistic models admitting inference in linear time in number of network edges. Our approach has several advantages, as it (1) allows generative and discriminative semi-supervised learning, (2) guarantees that adding unlabelled data can increase, but not degrade, the performance (safe), and (3) is computationally efficient and does not enforce restrictive assumptions on the data distribution. We show on a variety of data sets that safe semi-supervised learning with SPNs is competitive compared to state-of-the-art and can lead to a better generative and discriminative objective value than a purely supervised approach.
On the Latent Variable Interpretation in Sum-Product Networks
Oct 28, 2016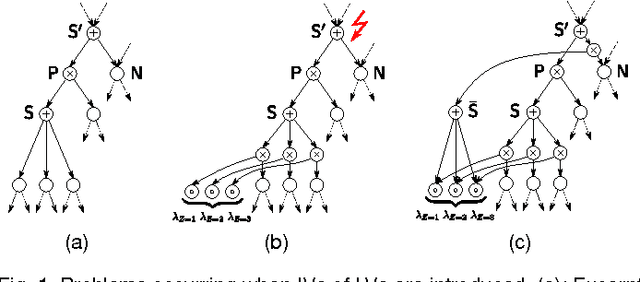
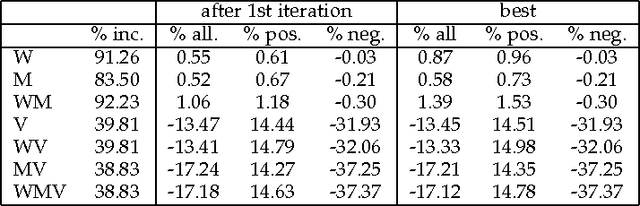

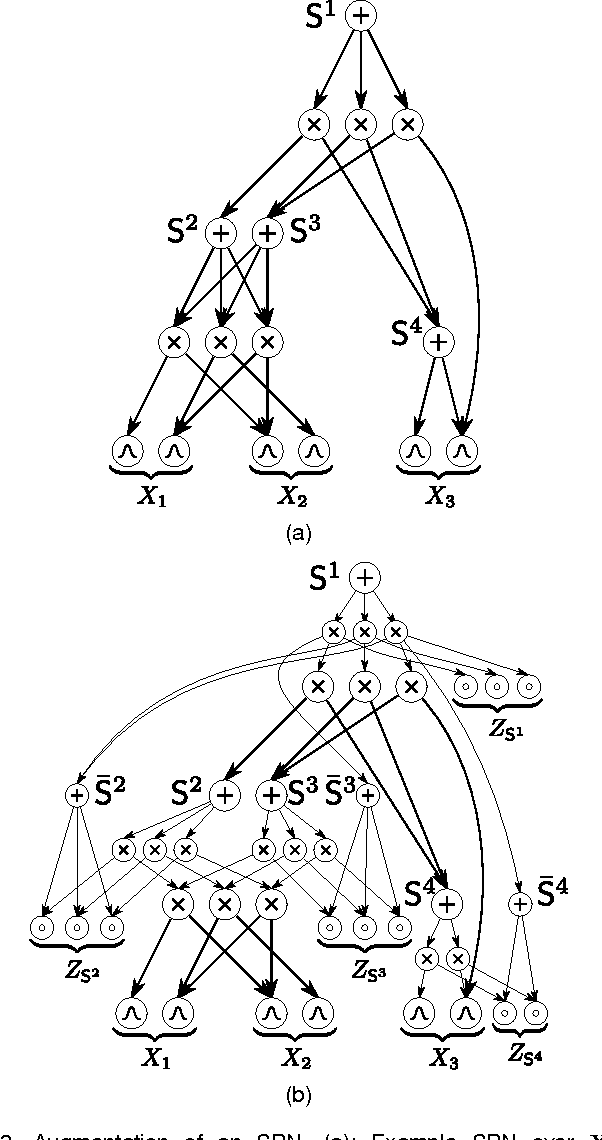
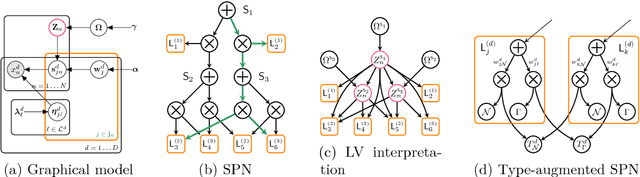
One of the central themes in Sum-Product networks (SPNs) is the interpretation of sum nodes as marginalized latent variables (LVs). This interpretation yields an increased syntactic or semantic structure, allows the application of the EM algorithm and to efficiently perform MPE inference. In literature, the LV interpretation was justified by explicitly introducing the indicator variables corresponding to the LVs' states. However, as pointed out in this paper, this approach is in conflict with the completeness condition in SPNs and does not fully specify the probabilistic model. We propose a remedy for this problem by modifying the original approach for introducing the LVs, which we call SPN augmentation. We discuss conditional independencies in augmented SPNs, formally establish the probabilistic interpretation of the sum-weights and give an interpretation of augmented SPNs as Bayesian networks. Based on these results, we find a sound derivation of the EM algorithm for SPNs. Furthermore, the Viterbi-style algorithm for MPE proposed in literature was never proven to be correct. We show that this is indeed a correct algorithm, when applied to selective SPNs, and in particular when applied to augmented SPNs. Our theoretical results are confirmed in experiments on synthetic data and 103 real-world datasets.
Exact Maximum Margin Structure Learning of Bayesian Networks
Jun 27, 2012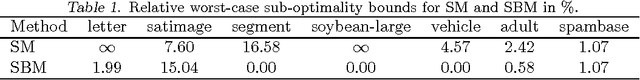
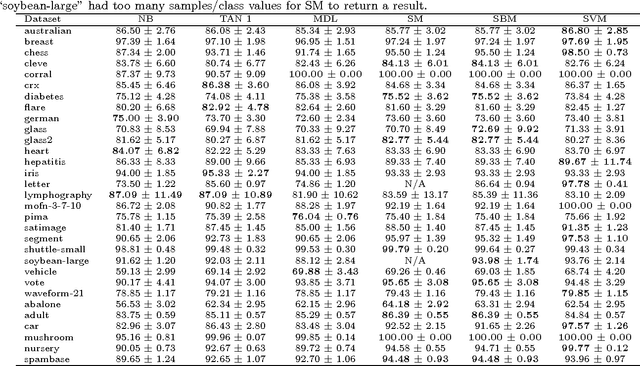

Recently, there has been much interest in finding globally optimal Bayesian network structures. These techniques were developed for generative scores and can not be directly extended to discriminative scores, as desired for classification. In this paper, we propose an exact method for finding network structures maximizing the probabilistic soft margin, a successfully applied discriminative score. Our method is based on branch-and-bound techniques within a linear programming framework and maintains an any-time solution, together with worst-case sub-optimality bounds. We apply a set of order constraints for enforcing the network structure to be acyclic, which allows a compact problem representation and the use of general-purpose optimization techniques. In classification experiments, our methods clearly outperform generatively trained network structures and compete with support vector machines.