 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Retrieval Methods in Azure AI Search
Dec 08, 2025Increasingly, attorneys are interested in moving beyond keyword and semantic search to improve the efficiency of how they find key information during a document review task. Large language models (LLMs) are now seen as tools that attorneys can use to ask natural language questions of their data during document review to receive accurate and concise answers. This study evaluates retrieval strategies within Microsoft Azure's Retrieval-Augmented Generation (RAG) framework to identify effective approaches for Early Case Assessment (ECA) in eDiscovery. During ECA, legal teams analyze data at the outset of a matter to gain a general understanding of the data and attempt to determine key facts and risks before beginning full-scale review. In this paper, we compare the performance of Azure AI Search's keyword, semantic, vector, hybrid, and hybrid-semantic retrieval methods. We then present the accuracy, relevance, and consistency of each method's AI-generated responses. Legal practitioners can use the results of this study to enhance how they select RAG configurations in the future.
Leveraging Machine Learning and Large Language Models for Automated Image Clustering and Description in Legal Discovery
Dec 08, 2025The rapid increase in digital image creation and retention presents substantial challenges during legal discovery, digital archive, and content management. Corporations and legal teams must organize, analyze, and extract meaningful insights from large image collections under strict time pressures, making manual review impractical and costly. These demands have intensified interest in automated methods that can efficiently organize and describe large-scale image datasets. This paper presents a systematic investigation of automated cluster description generation through the integration of image clustering, image captioning, and large language models (LLMs). We apply K-means clustering to group images into 20 visually coherent clusters and generate base captions using the Azure AI Vision API. We then evaluate three critical dimensions of the cluster description process: (1) image sampling strategies, comparing random, centroid-based, stratified, hybrid, and density-based sampling against using all cluster images; (2) prompting techniques, contrasting standard prompting with chain-of-thought prompting; and (3) description generation methods, comparing LLM-based generation with traditional TF-IDF and template-based approaches. We assess description quality using semantic similarity and coverage metrics. Results show that strategic sampling with 20 images per cluster performs comparably to exhaustive inclusion while significantly reducing computational cost, with only stratified sampling showing modest degradation. LLM-based methods consistently outperform TF-IDF baselines, and standard prompts outperform chain-of-thought prompts for this task. These findings provide practical guidance for deploying scalable, accurate cluster description systems that support high-volume workflows in legal discovery and other domains requiring automated organization of large image collections.
Empirical Evaluations of Seed Set Selection Strategies for Predictive Coding
Mar 21, 2019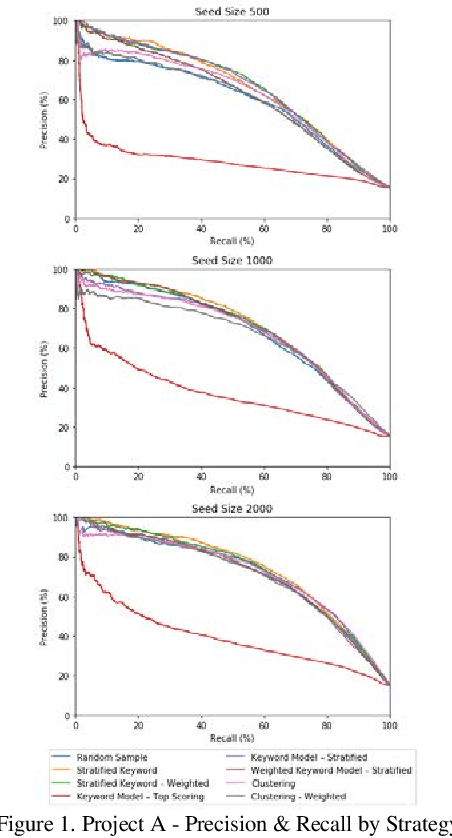
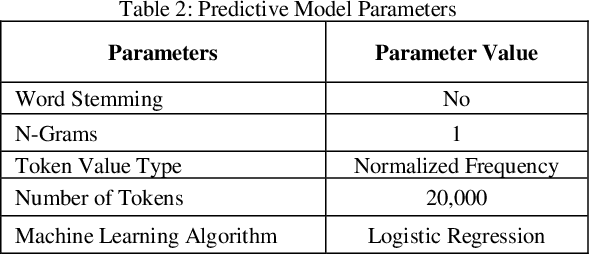
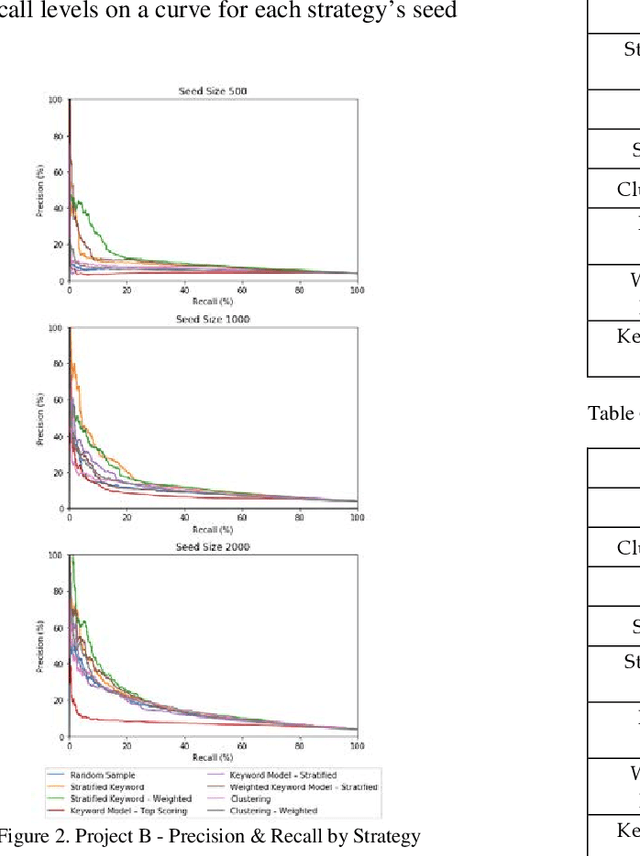
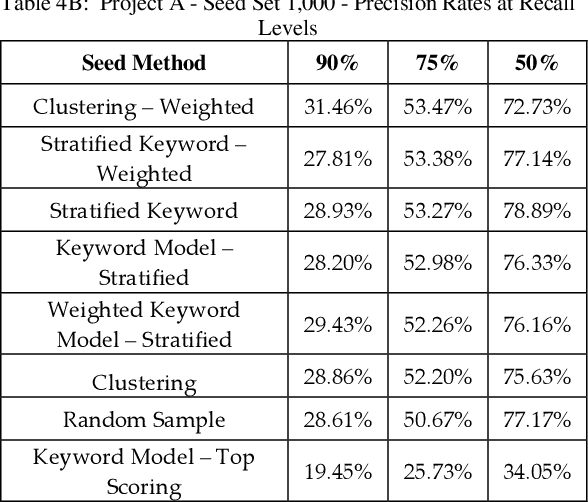
Training documents have a significant impact on the performance of predictive models in the legal domain. Yet, there is limited research that explores the effectiveness of the training document selection strategy - in particular, the strategy used to select the seed set, or the set of documents an attorney reviews first to establish an initial model. Since there is limited research on this important component of predictive coding, the authors of this paper set out to identify strategies that consistently perform well. Our research demonstrated that the seed set selection strategy can have a significant impact on the precision of a predictive model. Enabling attorneys with the results of this study will allow them to initiate the most effective predictive modeling process to comb through the terabytes of data typically present in modern litigation. This study used documents from four actual legal cases to evaluate eight different seed set selection strategies. Attorneys can use the results contained within this paper to enhance their approach to predictive coding.