 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoMo: Generating Entity-Specific Post-Modifiers in Context
Apr 08, 2019
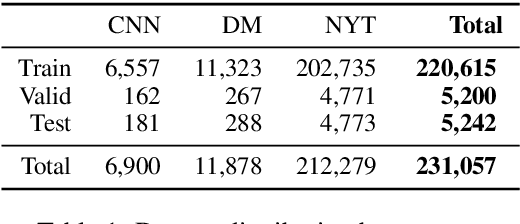
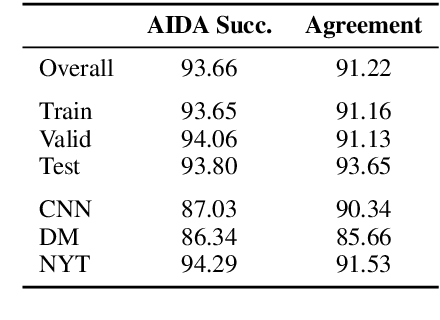

We introduce entity post-modifier generation as an instance of a collaborative writing task. Given a sentence about a target entity, the task is to automatically generate a post-modifier phrase that provides contextually relevant information about the entity. For example, for the sentence, "Barack Obama, _______, supported the #MeToo movement.", the phrase "a father of two girls" is a contextually relevant post-modifier. To this end, we build PoMo, a post-modifier dataset created automatically from news articles reflecting a journalistic need for incorporating entity information that is relevant to a particular news event. PoMo consists of more than 231K sentences with post-modifiers and associated facts extracted from Wikidata for around 57K unique entities. We use crowdsourcing to show that modeling contextual relevance is necessary for accurate post-modifier generation. We adapt a number of existing generation approaches as baselines for this dataset. Our results show there is large room for improvement in terms of both identifying relevant facts to include (knowing which claims are relevant gives a >20% improvement in BLEU score), and generating appropriate post-modifier text for the context (providing relevant claims is not sufficient for accurate generation). We conduct an error analysis that suggests promising directions for future research.
Multimodal Attribute Extraction
Nov 29, 2017
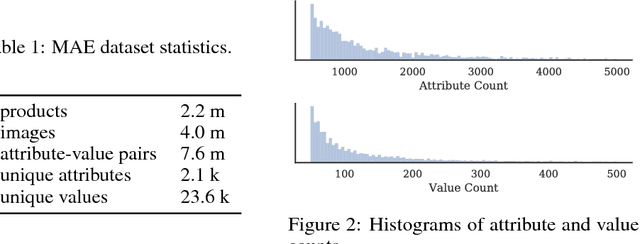
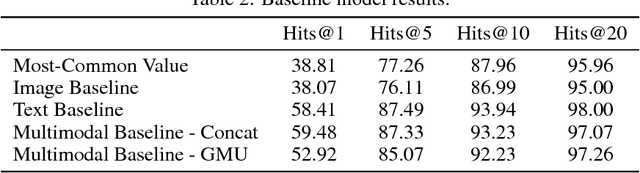
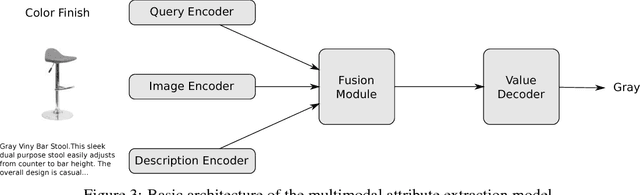
The broad goal of information extraction is to derive structured information from unstructured data. However, most existing methods focus solely on text, ignoring other types of unstructured data such as images, video and audio which comprise an increasing portion of the information on the web. To address this shortcoming, we propose the task of multimodal attribute extraction. Given a collection of unstructured and semi-structured contextual information about an entity (such as a textual description, or visual depictions) the task is to extract the entity's underlying attributes. In this paper, we provide a dataset containing mixed-media data for over 2 million product items along with 7 million attribute-value pairs describing the items which can be used to train attribute extractors in a weakly supervised manner. We provide a variety of baselines which demonstrate the relative effectiveness of the individual modes of information towards solving the task, as well as study human performance.