 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Building Inspection via Perceiver IO Fusion of Satellite and Street-Level Imagery
May 25, 2026We present a multi-modal classification framework that fuses satellite and street-level imagery through a Perceiver IO architecture operating on spatial patch tokens from a shared DINOv2 backbone. The design naturally handles a variable number of street-level views per building without padding or fixed-size pooling, and jointly predicts multi-label roof element and roof material classes. We construct a large-scale dataset of 32,135 buildings (61,672 segments) spanning ten countries, pairing satellite images with up to eight street-level views per segment and evaluating four masking strategies for isolating the target building. We propose an RGB-M masking strategy that appends the building footprint mask as a fourth input channel, providing a soft spatial prior that outperforms hard cropping across both modalities. The Perceiver IO fusion model improves over all other fusion strategies and yields substantial per-class gains for attributes visible from street level (e.g., +11.3 AP for slate, +1.3 AP for dormers), though the satellite-only baseline retains a slight advantage in macro-averaged mAP for classes that are predominantly visible from above. These results establish a scalable, flexible architecture for multi-modal building inspection that can accommodate heterogeneous inputs and multiple output tasks.
Joint Instance Segmentation and Geometric Attribute Regression for Roof Structures in Aerial Imagery
May 25, 2026We present a method for jointly predicting instance-level roof segment masks together with three continuous geometric attributes -- building height, roof slope, and roof azimuth -- from a single aerial orthophoto. Our approach extends Mask R-CNN with a dedicated attribute regression branch and introduces two key innovations: a conditional azimuth loss that suppresses supervision for flat roof segments where azimuth labels are inherently noisy, and a log-normalized height representation that addresses the heavily skewed distribution of building heights. We train and evaluate on a large-scale dataset of Dutch aerial images paired with automatically derived ground truth from 3DBAG, a nationwide LiDAR-based 3D building dataset. Using a DINOv3 ConvNeXt-Base backbone, our method achieves a mean absolute error of approximately 4 degrees for roof slope, 7 degrees for azimuth, and 1 meter for building height, with an instance segmentation AP$_{50}$ of 0.566. The predicted per-segment masks and attributes are sufficient to reconstruct simplified 3D building models (LoD2) from a single overhead image, requiring expensive 3D reference data only for training.
Safe Fakes: Evaluating Face Anonymizers for Face Detectors
Apr 23, 2021
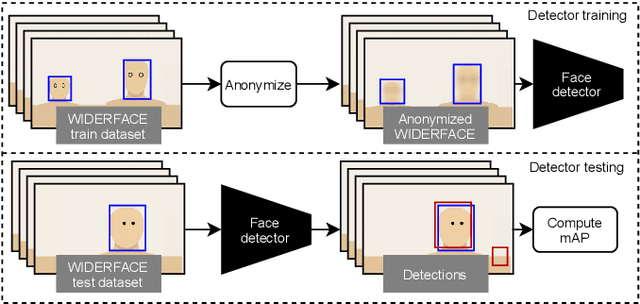


Since the introduction of the GDPR and CCPA legislation, both public and private facial image datasets are increasingly scrutinized. Several datasets have been taken offline completely and some have been anonymized. However, it is unclear how anonymization impacts face detection performance. To our knowledge, this paper presents the first empirical study on the effect of image anonymization on supervised training of face detectors. We compare conventional face anonymizers with three state-of-the-art Generative Adversarial Network-based (GAN) methods, by training an off-the-shelf face detector on anonymized data. Our experiments investigate the suitability of anonymization methods for maintaining face detector performance, the effect of detectors overtraining on anonymization artefacts, dataset size for training an anonymizer, and the effect of training time of anonymization GANs. A final experiment investigates the correlation between common GAN evaluation metrics and the performance of a trained face detector. Although all tested anonymization methods lower the performance of trained face detectors, faces anonymized using GANs cause far smaller performance degradation than conventional methods. As the most important finding, the best-performing GAN, DeepPrivacy, removes identifiable faces for a face detector trained on anonymized data, resulting in a modest decrease from 91.0 to 88.3 mAP. In the last few years, there have been rapid improvements in realism of GAN-generated faces. We expect that further progression in GAN research will allow the use of Deep Fake technology for privacy-preserving Safe Fakes, without any performance degradation for training face detectors.