 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoPE-LIME: RoPE-Space Locality + Sparse-K Sampling for Efficient LLM Attribution
Feb 06, 2026Explaining closed-source LLM outputs is challenging because API access prevents gradient-based attribution, while perturbation methods are costly and noisy when they depend on regenerated text. We introduce RoPE-LIME, an open-source extension of gSMILE that decouples reasoning from explanation: given a fixed output from a closed model, a smaller open-source surrogate computes token-level attributions from probability-based objectives (negative log-likelihood and divergence targets) under input perturbations. RoPE-LIME incorporates (i) a locality kernel based on Relaxed Word Mover's Distance computed in RoPE embedding space for stable similarity under masking, and (ii) Sparse-K sampling, an efficient perturbation strategy that improves interaction coverage under limited budgets. Experiments on HotpotQA (sentence features) and a hand-labeled MMLU subset (word features) show that RoPE-LIME produces more informative attributions than leave-one-out sampling and improves over gSMILE while substantially reducing closed-model API calls.
Succeeding at Scale: Automated Multi-Retriever Fusion and Query-Side Adaptation for Multi-Tenant Search
Jan 08, 2026Large-scale multi-tenant retrieval systems amass vast user query logs yet critically lack the curated relevance labels required for effective domain adaptation. This "dark data" problem is exacerbated by the operational cost of model updates: jointly fine-tuning query and document encoders requires re-indexing the entire corpus, which is prohibitive in multi-tenant environments with thousands of isolated indices. To address these dual challenges, we introduce \textbf{DevRev Search}, a passage retrieval benchmark for technical customer support constructed through a fully automatic pipeline. We employ a \textbf{fusion-based candidate generation} strategy, pooling results from diverse sparse and dense retrievers, and utilize an LLM-as-a-Judge to perform rigorous \textbf{consistency filtering} and relevance assignment. We further propose a practical \textbf{Index-Preserving Adaptation} strategy: by fine-tuning only the query encoder via Low-Rank Adaptation (LoRA), we achieve competitive performance improvements while keeping the document index frozen. Our experiments on DevRev Search and SciFact demonstrate that targeting specific transformer layers in the query encoder yields optimal quality-efficiency trade-offs, offering a scalable path for personalized enterprise search.
Efficient Single-Pass Training for Multi-Turn Reasoning
Apr 25, 2025



Training Large Language Models ( LLMs) to generate explicit reasoning before they produce an answer has been shown to improve their performance across various tasks such as mathematics and coding. However, fine-tuning LLMs on multi-turn reasoning datasets presents a unique challenge: LLMs must generate reasoning tokens that are excluded from subsequent inputs to the LLM. This discrepancy prevents us from processing an entire conversation in a single forward pass-an optimization readily available when we fine-tune on a multi-turn non-reasoning dataset. This paper proposes a novel approach that overcomes this limitation through response token duplication and a custom attention mask that enforces appropriate visibility constraints. Our approach significantly reduces the training time and allows efficient fine-tuning on multi-turn reasoning datasets.
Batch Decorrelation for Active Metric Learning
May 23, 2020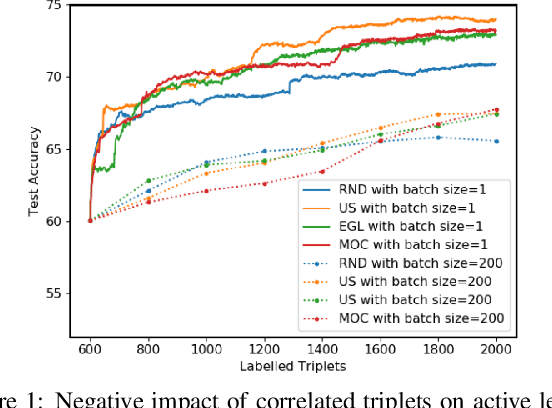
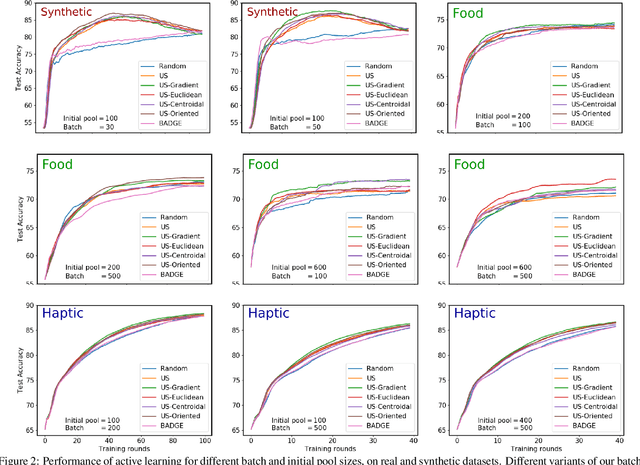
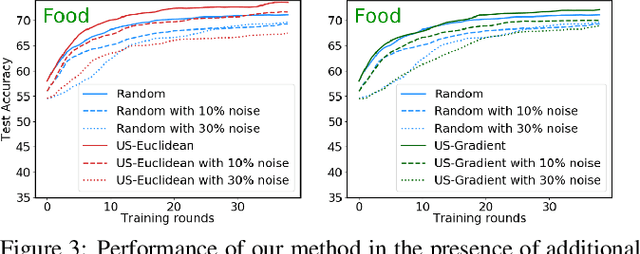
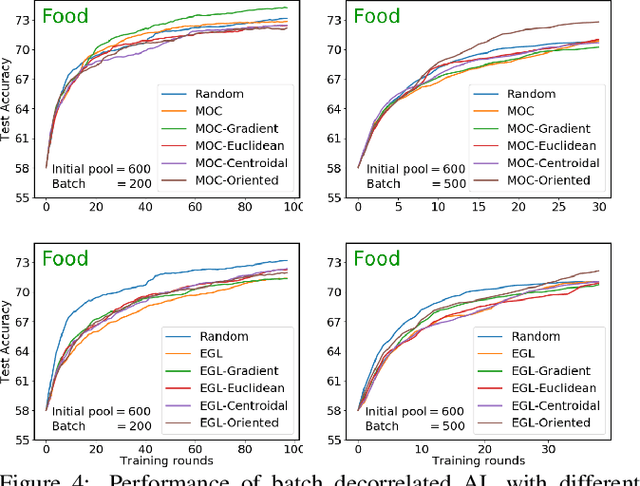
We present an active learning strategy for training parametric models of distance metrics, given triplet-based similarity assessments: object $x_i$ is more similar to object $x_j$ than to $x_k$. In contrast to prior work on class-based learning, where the fundamental goal is classification and any implicit or explicit metric is binary, we focus on {\em perceptual} metrics that express the {\em degree} of (dis)similarity between objects. We find that standard active learning approaches degrade when annotations are requested for {\em batches} of triplets at a time: our studies suggest that correlation among triplets is responsible. In this work, we propose a novel method to {\em decorrelate} batches of triplets, that jointly balances informativeness and diversity while decoupling the choice of heuristic for each criterion. Experiments indicate our method is general, adaptable, and outperforms the state-of-the-art.